Can Large Language Models Understand Preferences in Personalized Recommendation?
作者: Zhaoxuan Tan, Zinan Zeng, Qingkai Zeng, Zhenyu Wu, Zheyuan Liu, Fengran Mo, Meng Jiang
分类: cs.CL
发布日期: 2025-01-23
🔗 代码/项目: GITHUB
💡 一句话要点
提出PerRecBench,评估LLM在消除用户评分偏差和物品质量影响下的个性化推荐能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 个性化推荐 大型语言模型 用户偏好 评估方法 排序学习
📋 核心要点
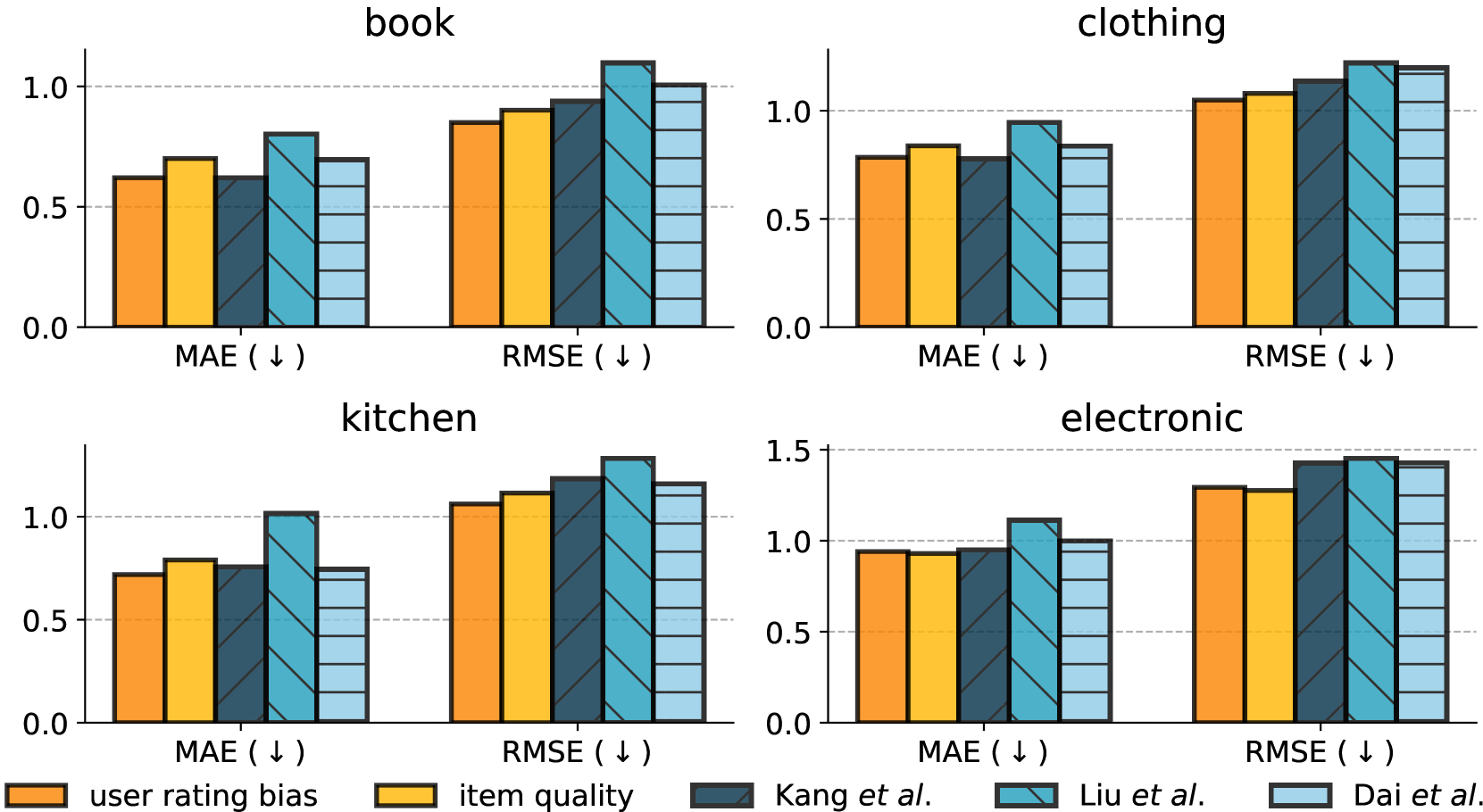
- 现有推荐评估方法侧重评分预测,易受用户评分偏差和物品质量的影响,难以准确评估模型对用户偏好的理解。
- 论文提出PerRecBench,通过分组排序的方式,消除用户评分偏差和物品质量的影响,从而更准确地评估模型捕捉用户偏好的能力。
- 实验表明,即使是大型LLM在消除偏差后,个性化推荐效果仍然不佳,凸显了现有方法在理解用户偏好方面的局限性。
📝 摘要(中文)
大型语言模型(LLM)在包括个性化推荐在内的各种任务中表现出色。现有的评估方法通常侧重于评分预测,依赖于实际评分和预测评分之间的回归误差。然而,用户评分偏差和物品质量是评分背后的两个重要影响因素,可能会掩盖用户-物品对数据中的个人偏好。为了解决这个问题,我们引入了PerRecBench,将评估与这两个因素分离,并以分组排序的方式评估推荐技术在捕捉个人偏好方面的能力。我们发现,通常擅长评分预测的基于LLM的推荐技术,在通过分组用户消除用户评分偏差和物品质量时,无法识别用户喜欢和不喜欢的物品。通过PerRecBench和19个LLM,我们发现,虽然较大的模型通常优于较小的模型,但它们仍然难以进行个性化推荐。我们的研究结果揭示了成对和列表排序方法优于点排序方法、PerRecBench与传统回归指标的低相关性、用户画像的重要性以及预训练数据分布的作用。我们进一步探索了三种监督微调策略,发现合并来自单格式训练的权重是有希望的,但提高LLM对用户偏好的理解仍然是一个开放的研究问题。
🔬 方法详解
问题定义:现有基于LLM的推荐系统评估方法主要依赖于评分预测的回归误差,但用户评分往往受到用户评分偏差(例如,有些人总是给出高分)和物品质量的影响。这些因素会掩盖用户真实的个性化偏好,使得评估结果无法准确反映模型对用户偏好的理解能力。因此,需要一种新的评估方法,能够消除这些偏差,直接评估模型对用户偏好的捕捉能力。
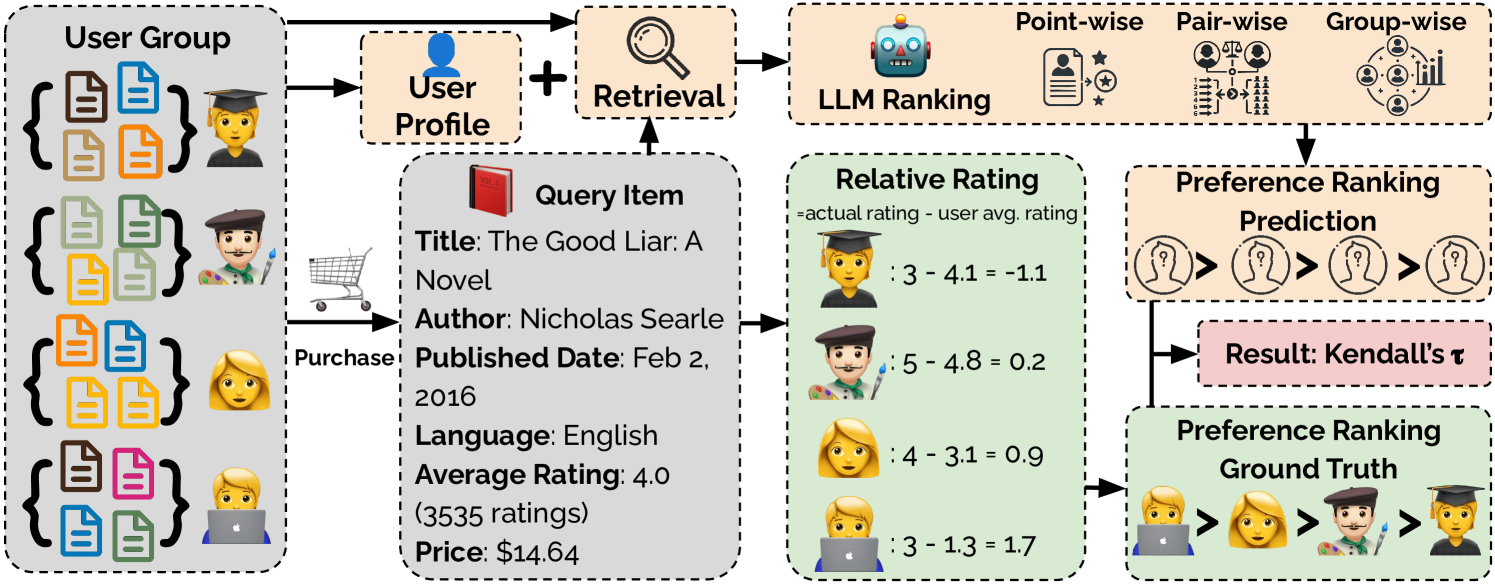
核心思路:论文的核心思路是通过分组排序的方式,消除用户评分偏差和物品质量的影响。具体来说,将同一用户的物品进行分组,然后要求模型对这些物品进行排序,从而评估模型对用户偏好的理解。这种方法避免了直接预测评分,而是关注模型对用户偏好的相对排序能力。
技术框架:PerRecBench的整体框架包括以下几个主要步骤:1) 数据准备:选择合适的推荐数据集,并进行预处理。2) 模型选择:选择待评估的LLM推荐模型。3) 分组排序:将同一用户的物品进行分组,并生成排序任务。4) 模型预测:使用LLM模型对每个分组中的物品进行排序。5) 评估指标:使用排序相关的评估指标(例如,NDCG、MRR)评估模型的排序性能。
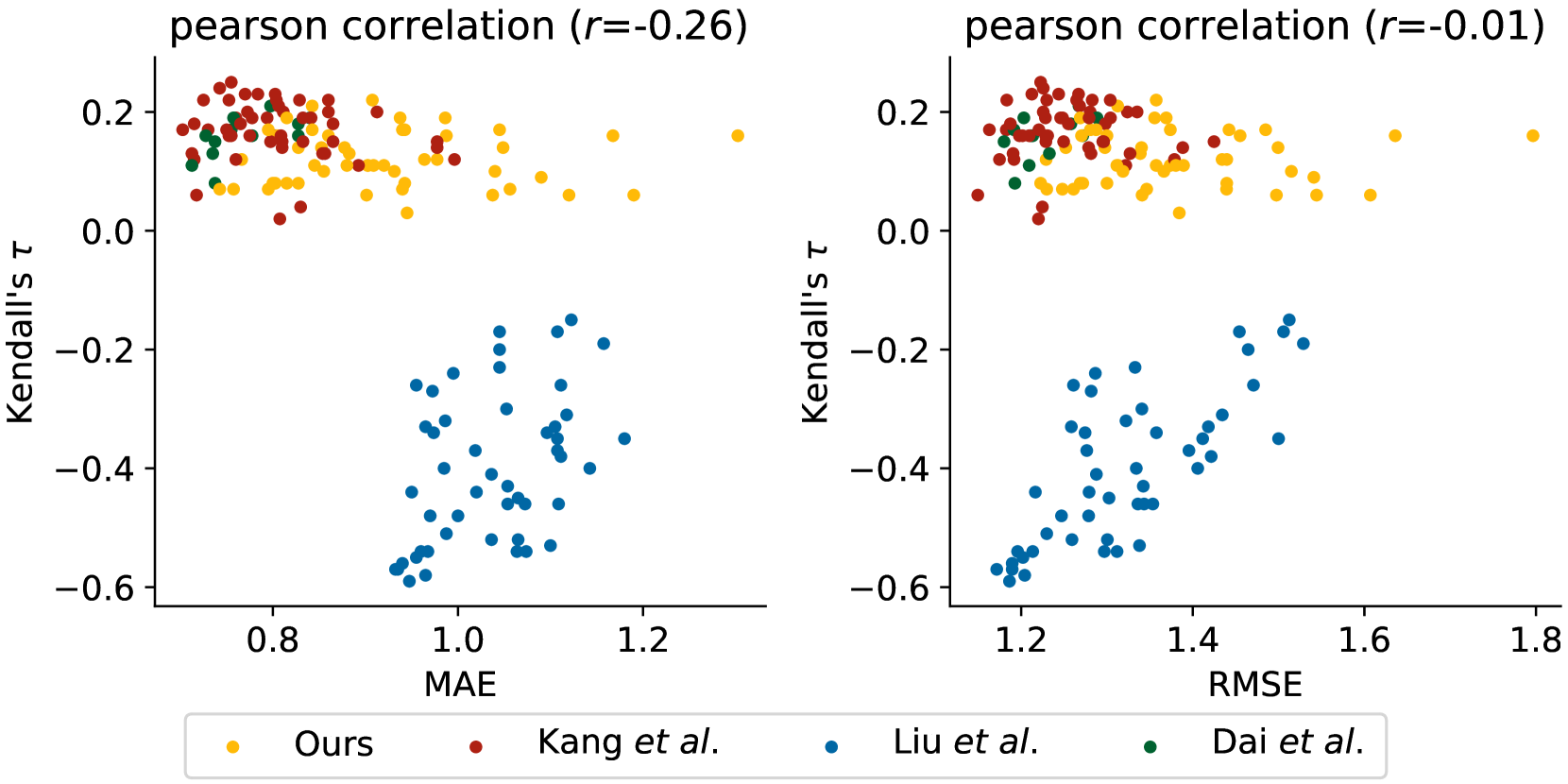
关键创新:PerRecBench的关键创新在于其评估方式,它将评估与用户评分偏差和物品质量解耦。通过分组排序,PerRecBench能够更准确地评估模型对用户偏好的理解能力,而不仅仅是评分预测的准确性。这种评估方式更符合个性化推荐的本质,即为用户推荐其最感兴趣的物品。
关键设计:PerRecBench的关键设计包括:1) 分组策略:如何将同一用户的物品进行分组,例如,可以根据物品的类别、属性等进行分组。2) 排序任务生成:如何将分组后的物品转化为排序任务,例如,可以使用pairwise或listwise的方式生成排序任务。3) 评估指标选择:选择合适的排序评估指标,例如,NDCG、MRR等,以评估模型的排序性能。此外,论文还探索了三种监督微调策略,包括单格式训练和多格式训练,并研究了合并来自单格式训练的权重的效果。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使是大型LLM在PerRecBench上的表现仍然不佳,这表明现有模型在理解用户偏好方面存在局限性。此外,pairwise和listwise排序方法优于pointwise排序方法。PerRecBench与传统的回归指标相关性较低,表明其评估的是不同的能力。用户画像对推荐效果有显著影响,预训练数据分布也起着重要作用。
🎯 应用场景
该研究成果可应用于更准确地评估和改进基于LLM的个性化推荐系统。通过PerRecBench,研究人员可以更好地了解LLM在理解用户偏好方面的能力,并开发出更有效的推荐算法。这有助于提升推荐系统的用户满意度和商业价值,例如在电商、视频推荐、新闻推荐等领域。
📄 摘要(原文)
Large Language Models (LLMs) excel in various tasks, including personalized recommendations. Existing evaluation methods often focus on rating prediction, relying on regression errors between actual and predicted ratings. However, user rating bias and item quality, two influential factors behind rating scores, can obscure personal preferences in user-item pair data. To address this, we introduce PerRecBench, disassociating the evaluation from these two factors and assessing recommendation techniques on capturing the personal preferences in a grouped ranking manner. We find that the LLM-based recommendation techniques that are generally good at rating prediction fail to identify users' favored and disfavored items when the user rating bias and item quality are eliminated by grouping users. With PerRecBench and 19 LLMs, we find that while larger models generally outperform smaller ones, they still struggle with personalized recommendation. Our findings reveal the superiority of pairwise and listwise ranking approaches over pointwise ranking, PerRecBench's low correlation with traditional regression metrics, the importance of user profiles, and the role of pretraining data distributions. We further explore three supervised fine-tuning strategies, finding that merging weights from single-format training is promising but improving LLMs' understanding of user preferences remains an open research problem. Code and data are available at https://github.com/TamSiuhin/PerRecBench