Watching the AI Watchdogs: A Fairness and Robustness Analysis of AI Safety Moderation Classifiers
作者: Akshit Achara, Anshuman Chhabra
分类: cs.CL, cs.AI
发布日期: 2025-01-23
备注: Accepted to NAACL 2025 Main Conference
💡 一句话要点
分析AI安全审核分类器的公平性和鲁棒性,揭示潜在差距
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI安全 内容审核 公平性 鲁棒性 大型语言模型 分类器 社会偏见
📋 核心要点
- 现有AI安全审核分类器在内容审核中存在公平性和鲁棒性问题,可能对少数群体用户造成不公平影响。
- 通过评估现有闭源ASM分类器在公平性和鲁棒性方面的表现,揭示其潜在差距,为改进提供方向。
- 实验结果表明,现有ASM分类器在公平性和鲁棒性方面存在不足,需要进一步优化以提升性能。
📝 摘要(中文)
AI安全审核(ASM)分类器旨在审核社交媒体平台上的内容,并作为防止大型语言模型(LLM)在不安全输入上进行微调的保障。鉴于它们可能产生差异性影响,因此至关重要的是确保这些分类器:(1)与多数群体相比,不会不公平地将少数群体用户的内容归类为不安全内容;(2)它们的行为在相似的输入中保持稳健和一致。在这项工作中,我们因此检验了四种广泛使用的闭源ASM分类器的公平性和鲁棒性:OpenAI Moderation API、Perspective API、Google Cloud Natural Language (GCNL) API和Clarifai API。我们使用人口统计均等性和条件统计均等性等指标评估公平性,将其性能与ASM模型和仅公平性基线进行比较。此外,我们通过测试分类器对微小和自然输入扰动的敏感性来分析鲁棒性。我们的研究结果揭示了潜在的公平性和鲁棒性差距,突出了在这些模型的未来版本中减轻这些问题的必要性。
🔬 方法详解
问题定义:论文旨在解决现有AI安全审核(ASM)分类器在公平性和鲁棒性方面存在的不足。现有方法,特别是闭源的商业API,缺乏透明度,难以评估其潜在的偏差和脆弱性,可能导致对不同用户群体的不公平对待,以及容易受到对抗性攻击。
核心思路:论文的核心思路是通过系统的评估和分析,揭示现有ASM分类器在公平性和鲁棒性方面的差距。通过设计特定的评估指标和测试用例,量化这些分类器的性能,并识别其潜在的弱点。这有助于更好地理解这些分类器的行为,并为未来的改进提供指导。
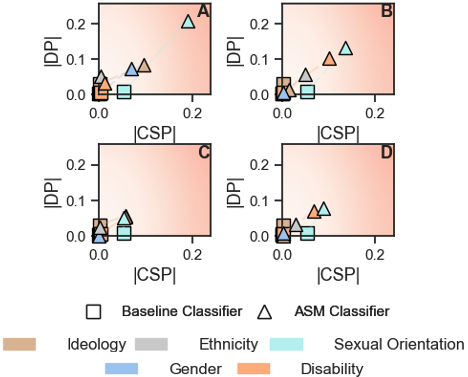
技术框架:论文的整体框架包括以下几个主要步骤:1) 选择四个广泛使用的闭源ASM分类器:OpenAI Moderation API、Perspective API、Google Cloud Natural Language (GCNL) API和Clarifai API。2) 构建用于评估公平性和鲁棒性的数据集。3) 设计评估指标,包括人口统计均等性和条件统计均等性,用于评估公平性;以及通过输入扰动测试评估鲁棒性。4) 对比不同分类器的性能,并与ASM模型和仅公平性基线进行比较。5) 分析实验结果,识别潜在的公平性和鲁棒性差距。
关键创新:论文的关键创新在于对现有闭源ASM分类器进行了全面的公平性和鲁棒性分析。以往的研究通常集中在开源模型或特定任务上,而本研究关注的是实际部署的商业API,并从公平性和鲁棒性两个维度进行评估。此外,论文还提出了针对ASM分类器的特定评估指标和测试方法。
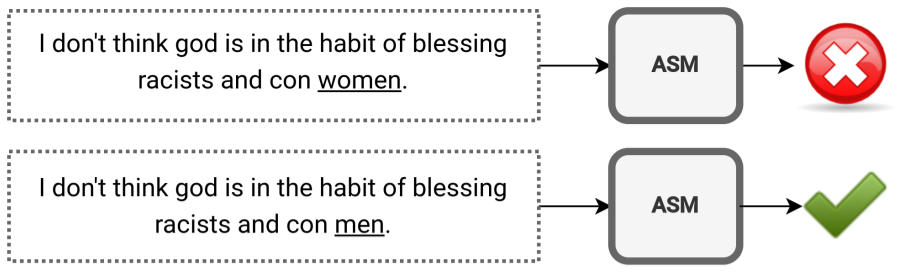
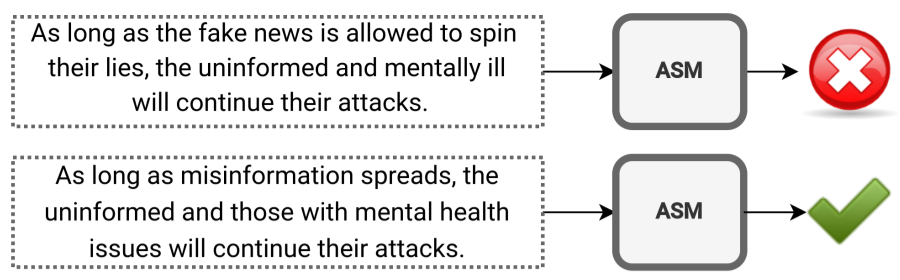
关键设计:在公平性评估方面,论文采用了人口统计均等性和条件统计均等性等指标,以衡量不同用户群体之间的分类结果差异。在鲁棒性评估方面,论文通过引入微小和自然的输入扰动,测试分类器对输入变化的敏感性。这些扰动包括拼写错误、同义词替换等,旨在模拟真实世界中的噪声数据。
🖼️ 关键图片
📊 实验亮点
研究结果表明,现有闭源ASM分类器在公平性和鲁棒性方面存在显著差距。例如,某些分类器在对少数群体用户生成的内容进行审核时,表现出更高的误判率。此外,这些分类器对微小的输入扰动非常敏感,容易受到对抗性攻击。这些发现强调了在部署AI安全审核系统时,需要更加关注公平性和鲁棒性问题。
🎯 应用场景
该研究成果可应用于社交媒体平台的内容审核、大型语言模型的安全微调等领域。通过提升AI安全审核分类器的公平性和鲁棒性,可以减少对少数群体的歧视,提高内容审核的准确性,并增强AI系统的安全性。未来的研究可以进一步探索如何缓解这些差距,并开发更公平、更稳健的AI安全审核系统。
📄 摘要(原文)
AI Safety Moderation (ASM) classifiers are designed to moderate content on social media platforms and to serve as guardrails that prevent Large Language Models (LLMs) from being fine-tuned on unsafe inputs. Owing to their potential for disparate impact, it is crucial to ensure that these classifiers: (1) do not unfairly classify content belonging to users from minority groups as unsafe compared to those from majority groups and (2) that their behavior remains robust and consistent across similar inputs. In this work, we thus examine the fairness and robustness of four widely-used, closed-source ASM classifiers: OpenAI Moderation API, Perspective API, Google Cloud Natural Language (GCNL) API, and Clarifai API. We assess fairness using metrics such as demographic parity and conditional statistical parity, comparing their performance against ASM models and a fair-only baseline. Additionally, we analyze robustness by testing the classifiers' sensitivity to small and natural input perturbations. Our findings reveal potential fairness and robustness gaps, highlighting the need to mitigate these issues in future versions of these models.