RAMQA: A Unified Framework for Retrieval-Augmented Multi-Modal Question Answering
作者: Yang Bai, Christan Earl Grant, Daisy Zhe Wang
分类: cs.CL, cs.AI, cs.IR, cs.LG
发布日期: 2025-01-23
备注: Accepted by NAACL 2025 Findings
🔗 代码/项目: GITHUB
💡 一句话要点
提出RAMQA,一个统一的检索增强多模态问答框架,提升生成式LLM在MRAQA任务中的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态问答 检索增强 大型语言模型 生成式排序 指令微调
📋 核心要点
- 现有MRAQA方法依赖于小型编码器模型,与先进的生成式LLM不兼容,限制了性能。
- RAMQA结合学习排序和生成式排列增强排序,利用LLaVA和LLaMA进行多模态排序和重排序。
- 在WebQA和MultiModalQA上的实验表明,RAMQA显著优于现有基线,验证了其有效性。
📝 摘要(中文)
多模态检索增强问答(MRAQA)融合了文本和图像,在信息检索(IR)和自然语言处理(NLP)领域受到了广泛关注。传统的排序方法依赖于基于小型编码器的语言模型,这与现代基于解码器的生成式大型语言模型(LLM)不兼容,而后者已经推动了各种NLP任务的发展。为了弥合这一差距,我们提出了RAMQA,一个统一的框架,结合了学习排序方法和生成式排列增强排序技术。我们首先使用LLaVA作为骨干网络训练一个pointwise多模态排序器。然后,我们应用指令微调来训练一个LLaMA模型,用于使用创新的自回归多任务学习方法对top-k文档进行重新排序。我们的生成式排序模型以各种排列方式从候选文档中生成重新排序的文档ID和特定答案。在WebQA和MultiModalQA这两个MRAQA基准上的实验表明,与强大的基线相比,RAMQA取得了显著的改进,突出了我们方法的有效性。代码和数据可在https://github.com/TonyBY/RAMQA获取。
🔬 方法详解
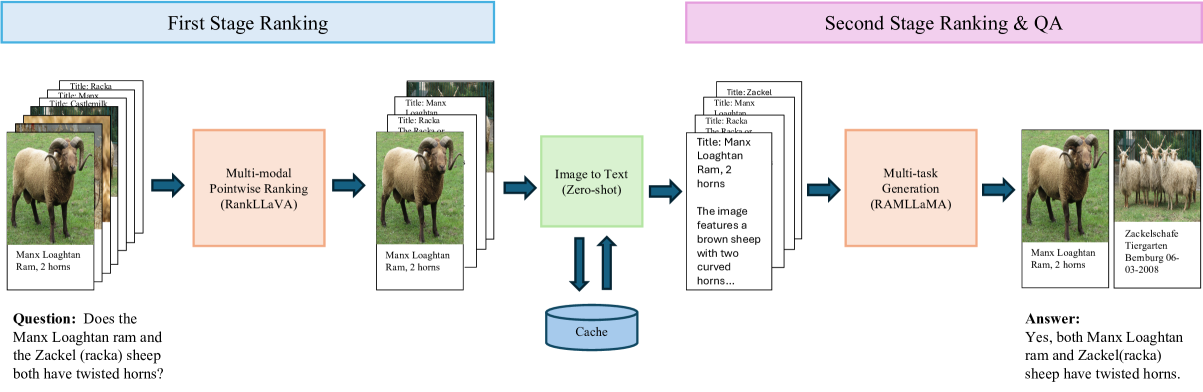
问题定义:论文旨在解决多模态检索增强问答(MRAQA)任务中,现有方法与现代生成式大型语言模型(LLM)不兼容的问题。传统的MRAQA方法依赖于小型编码器模型进行文档排序,无法充分利用生成式LLM在自然语言生成方面的强大能力。这导致检索到的文档排序不佳,最终影响问答的准确性。
核心思路:论文的核心思路是将学习排序方法与生成式排列增强排序技术相结合,构建一个统一的框架RAMQA。该框架首先使用多模态排序器(基于LLaVA)进行初步排序,然后利用生成式LLM(LLaMA)对top-k文档进行重排序。通过生成文档ID和答案,LLM能够更好地理解文档之间的关系,从而优化排序结果。
技术框架:RAMQA框架包含两个主要阶段:1) 多模态排序器训练:使用LLaVA作为骨干网络,训练一个pointwise多模态排序器,用于对候选文档进行初步排序。2) 生成式重排序器训练:使用LLaMA模型,通过指令微调和自回归多任务学习,训练一个生成式重排序器。该重排序器以各种排列方式生成重新排序的文档ID和特定答案。整体流程是先通过多模态排序器得到top-k文档,然后将这些文档输入到生成式重排序器中,得到最终的排序结果和答案。
关键创新:RAMQA的关键创新在于将生成式LLM引入到MRAQA的文档重排序阶段。与传统的基于编码器的排序方法不同,RAMQA利用LLM的生成能力,通过生成文档ID和答案来理解文档之间的关系,从而实现更准确的排序。此外,论文还提出了自回归多任务学习方法,进一步提升了LLM的重排序能力。
关键设计:在多模态排序器训练阶段,使用pointwise损失函数进行优化。在生成式重排序器训练阶段,使用指令微调来引导LLMA模型学习重排序任务。自回归多任务学习包括生成重新排序的文档ID和生成答案两个任务。损失函数是两个任务损失的加权和。文档ID的生成采用自回归的方式,即每次生成一个文档ID,并将其作为下一个ID生成的输入。答案的生成也采用类似的方式。
🖼️ 关键图片


📊 实验亮点
实验结果表明,RAMQA在WebQA和MultiModalQA两个MRAQA基准上均取得了显著的提升。在WebQA上,RAMQA的性能优于现有基线模型,提升幅度达到显著水平。在MultiModalQA上,RAMQA也取得了类似的提升。这些结果验证了RAMQA框架的有效性,并表明生成式重排序方法在MRAQA任务中具有巨大的潜力。
🎯 应用场景
RAMQA框架可应用于各种需要多模态信息检索和问答的场景,例如智能客服、搜索引擎、教育辅助等。通过结合文本和图像信息,RAMQA能够更准确地理解用户的问题,并提供更相关的答案。该研究的成果有助于提升人机交互的效率和用户体验,并为未来的多模态信息处理研究提供借鉴。
📄 摘要(原文)
Multi-modal retrieval-augmented Question Answering (MRAQA), integrating text and images, has gained significant attention in information retrieval (IR) and natural language processing (NLP). Traditional ranking methods rely on small encoder-based language models, which are incompatible with modern decoder-based generative large language models (LLMs) that have advanced various NLP tasks. To bridge this gap, we propose RAMQA, a unified framework combining learning-to-rank methods with generative permutation-enhanced ranking techniques. We first train a pointwise multi-modal ranker using LLaVA as the backbone. Then, we apply instruction tuning to train a LLaMA model for re-ranking the top-k documents using an innovative autoregressive multi-task learning approach. Our generative ranking model generates re-ranked document IDs and specific answers from document candidates in various permutations. Experiments on two MRAQA benchmarks, WebQA and MultiModalQA, show significant improvements over strong baselines, highlighting the effectiveness of our approach. Code and data are available at: https://github.com/TonyBY/RAMQA