OpenGenAlign: A Preference Dataset and Benchmark for Trustworthy Reward Modeling in Open-Ended, Long-Context Generation
作者: Hanning Zhang, Juntong Song, Juno Zhu, Yuanhao Wu, Tong Zhang, Cheng Niu
分类: cs.CL
发布日期: 2025-01-22 (更新: 2025-11-12)
备注: Preprint update
💡 一句话要点
提出OpenGenAlign,用于开放域长文本生成中可信奖励建模的偏好数据集与基准。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励建模 长文本生成 偏好数据集 强化学习 开放域 大型语言模型 幻觉抑制
📋 核心要点
- 现有奖励模型在开放域长文本生成任务中表现不足,缺乏针对该场景的有效评估和改进方法。
- OpenGenAlign框架通过构建高质量偏好数据集,并训练奖励模型,从而评估和提升长文本生成质量。
- 实验表明,OpenGenAlign训练的奖励模型在基准测试中表现优异,并能有效提升策略模型的生成质量。
📝 摘要(中文)
奖励建模在评估和改进大型语言模型(LLMs)的生成能力方面至关重要。虽然最近的研究表明,奖励建模在提高安全性、有用性、推理能力和指令遵循能力方面具有可行性,但其在开放域长文本生成中的能力和泛化性仍很少被探索。本文介绍了OpenGenAlign,一个框架和一个高质量数据集,旨在开发奖励模型,以评估和改进无幻觉、全面、可靠和高效的开放域长文本生成。我们定义了四个关键指标来评估生成质量,并开发了一个自动化流程,使用o3评估多个LLM在长文本问答、数据到文本和摘要场景中的输出,最终得到33K高质量的偏好数据,人类一致性率为81%。实验结果表明,现有的奖励模型在保留的基准测试中表现不佳。我们训练的奖励模型在基准测试中取得了优异的性能,并使用强化学习(RL)有效地提高了策略模型的生成质量。此外,OpenGenAlign可以用于现有数据集中的有效引导生成。更重要的是,我们证明了OpenGenAlign可以与其他领域的奖励数据集成,以获得更好的性能。
🔬 方法详解
问题定义:论文旨在解决开放域长文本生成任务中,现有奖励模型无法有效评估和提升生成质量的问题。现有方法在处理长文本时,容易出现幻觉、信息不全面、可靠性低等问题,缺乏针对这些问题的有效评估指标和训练数据。
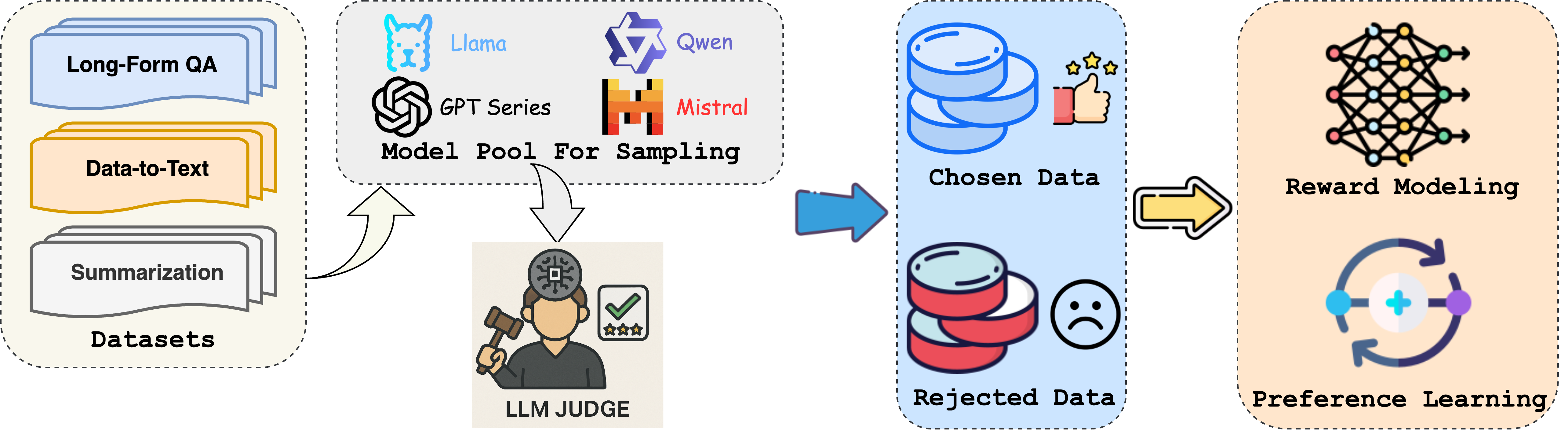
核心思路:论文的核心思路是构建一个高质量的偏好数据集OpenGenAlign,该数据集包含多个LLM在不同长文本生成任务上的输出,并由人工标注其偏好顺序。然后,利用该数据集训练奖励模型,使其能够准确评估生成文本的质量,并指导策略模型的训练。
技术框架:OpenGenAlign框架包含以下几个主要模块:1) 数据收集:利用多个LLM在长文本问答、数据到文本和摘要等任务上生成文本。2) 质量评估:定义了四个关键指标(无幻觉、全面性、可靠性和效率)来评估生成质量。3) 人工标注:对生成的文本进行人工标注,确定偏好顺序。4) 奖励模型训练:利用标注数据训练奖励模型,使其能够预测文本的质量。5) 策略模型训练:利用奖励模型指导策略模型的训练,提升生成质量。
关键创新:论文的关键创新在于构建了一个高质量的、专门针对开放域长文本生成的偏好数据集OpenGenAlign。该数据集包含了多个LLM在不同任务上的输出,并由人工标注其偏好顺序,为奖励模型的训练提供了可靠的数据基础。此外,论文还定义了四个关键指标来评估生成质量,为奖励模型的训练提供了明确的目标。
关键设计:在数据收集阶段,论文选择了多个具有代表性的LLM,并在长文本问答、数据到文本和摘要等任务上生成文本。在人工标注阶段,论文采用了三元组比较的方式,即每次比较三个文本,确定其偏好顺序。在奖励模型训练阶段,论文采用了pairwise ranking loss,使得奖励模型能够学习到文本之间的偏好关系。具体参数设置未知。
🖼️ 关键图片
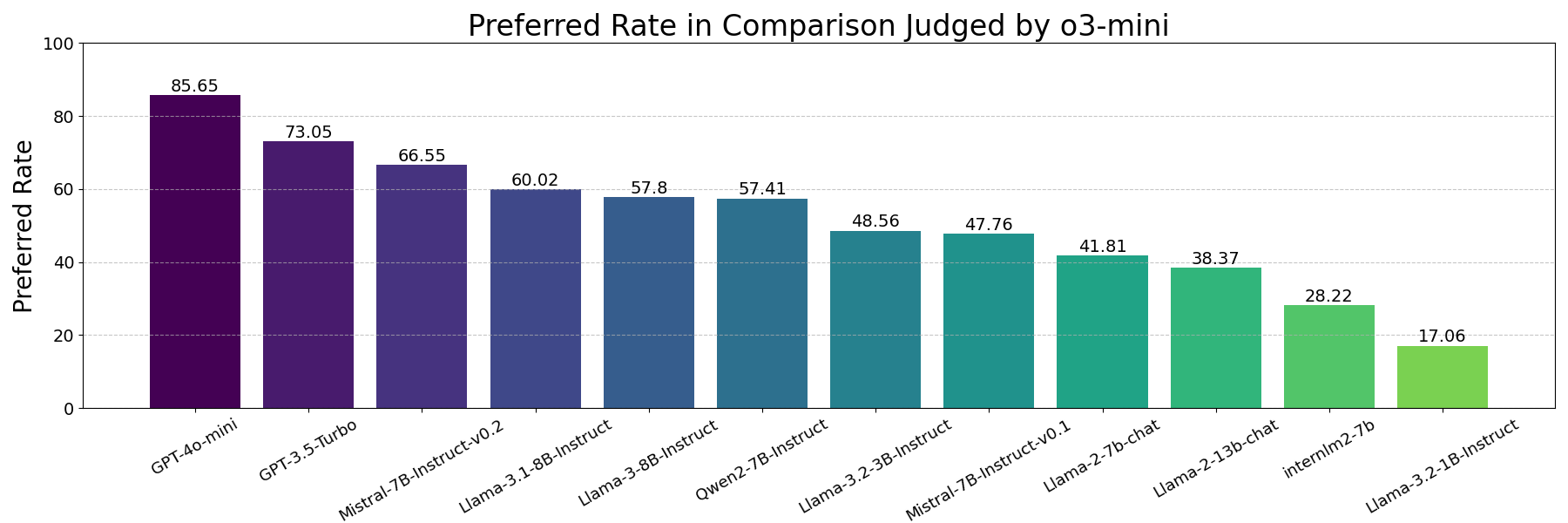
📊 实验亮点
实验结果表明,现有的奖励模型在OpenGenAlign基准测试中表现不佳,而论文训练的奖励模型取得了优异的性能,人类一致性率达到81%。通过使用该奖励模型进行强化学习,策略模型的生成质量得到了有效提升。此外,OpenGenAlign还可以与其他领域的奖励数据集成,以获得更好的性能。具体提升幅度未知。
🎯 应用场景
OpenGenAlign的研究成果可应用于各种需要高质量长文本生成的场景,例如智能客服、自动报告生成、新闻摘要等。通过训练奖励模型,可以有效提升生成文本的质量,减少幻觉,提高信息全面性和可靠性,从而提升用户体验和工作效率。该研究也为未来开发更强大的开放域长文本生成模型奠定了基础。
📄 摘要(原文)
Reward Modeling is critical in evaluating and improving the generation of Large Language Models (LLMs). While numerous recent works have shown its feasibility in improving safety, helpfulness, reasoning, and instruction-following ability, its capability and generalization to open-ended long-context generation is still rarely explored. In this paper, we introduce OpenGenAlign, a framework and a high-quality dataset designed to develop reward models to evaluate and improve hallucination-free, comprehensive, reliable, and efficient open-ended long-context generation. We define four key metrics to assess generation quality and develop an automated pipeline to evaluate the outputs of multiple LLMs across long-context QA, Data-to-Text, and Summarization scenarios using o3, ending up with 33K high-quality preference data with a human agreement rate of 81\%. Experimental results first demonstrate that existing reward models perform suboptimally on the held-out benchmark. And Our trained reward model achieves superior performance in the benchmark and effectively improves the generation quality of the policy models using Reinforcement Learning (RL). Additionally, OpenGenAlign could be used for effective guided generation in existing datasets. Furthermore, we demonstrate that the OpenGenAlign could be integrated with reward data from other domains to achieve better performance.