Does Table Source Matter? Benchmarking and Improving Multimodal Scientific Table Understanding and Reasoning
作者: Bohao Yang, Yingji Zhang, Dong Liu, André Freitas, Chenghua Lin
分类: cs.CL
发布日期: 2025-01-22 (更新: 2025-02-25)
🔗 代码/项目: GITHUB
💡 一句话要点
提出MMSci框架,提升多模态大模型在科学表格理解和数值推理上的能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 表格理解 数值推理 科学文献分析 领域特定数据集
📋 核心要点
- 现有大语言模型依赖将表格转换为文本序列,而多模态大模型在处理科学表格时受限于固定输入分辨率和数值推理能力。
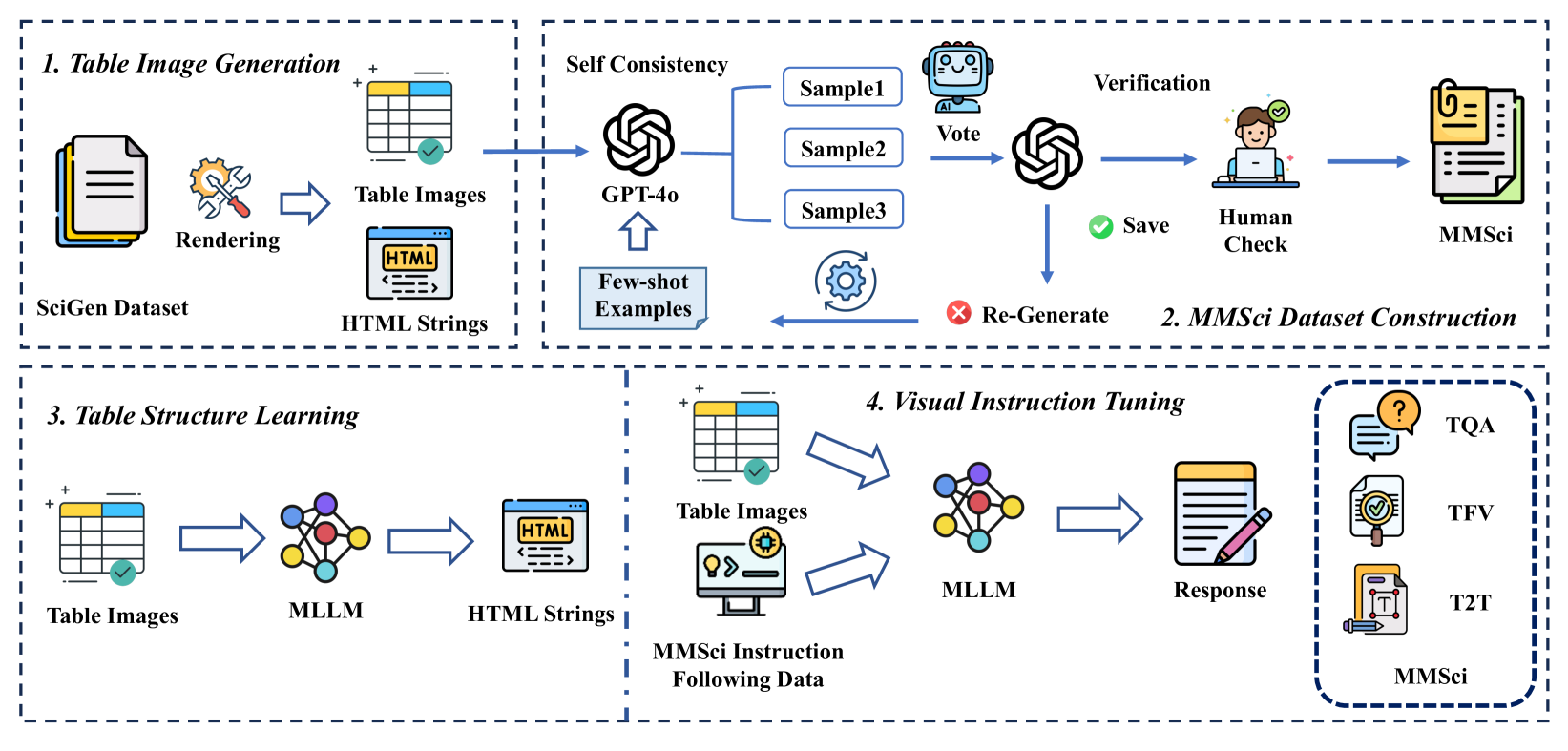
- 论文提出MMSci框架,包含领域特定的预训练数据、指令调优数据和评估基准,并采用动态输入分辨率来提升模型性能。
- 实验表明,使用领域特定数据训练的模型优于使用通用数据训练的模型,且动态输入分辨率显著提升了表格理解和数值推理能力。
📝 摘要(中文)
本文提出了一个全面的多模态科学表格理解和推理框架,该框架利用动态输入图像分辨率。该框架包含三个关键组成部分:(1) MMSci-Pre,一个包含52K科学表格结构识别样本的领域特定表格结构学习数据集;(2) MMSci-Ins,一个包含12K样本的指令调优数据集,涵盖三个基于表格的任务;(3) MMSci-Eval,一个包含3,114个测试样本的基准,专门用于评估数值推理能力。大量实验表明,与150K通用领域表格相比,我们提出的领域特定方法在52K科学表格图像上实现了卓越的性能,突出了数据质量的重要性。我们提出的基于表格的多模态大模型,结合动态输入分辨率,在通用表格理解和数值推理能力方面都显示出显著的改进,并对保留数据集具有很强的泛化能力。我们的代码和数据已公开。
🔬 方法详解
问题定义:现有的大语言模型(LLMs)在表格理解方面取得了进展,但主要依赖于将表格转换为文本序列。多模态大语言模型(MLLMs)虽然可以直接处理图像,但在处理科学表格时面临挑战,主要体现在两个方面:一是固定输入图像分辨率限制了对表格细节的捕捉;二是数值推理能力不足,难以完成复杂的计算和分析任务。因此,如何提升MLLMs在科学表格理解和数值推理方面的能力是一个亟待解决的问题。
核心思路:本文的核心思路是构建一个领域特定的多模态科学表格理解和推理框架,通过高质量的数据集和动态输入分辨率来提升模型的性能。具体来说,论文认为数据质量比数据数量更重要,因此构建了一个包含52K科学表格结构识别样本的领域特定数据集MMSci-Pre。同时,为了提升模型的数值推理能力,论文提出了一个包含12K样本的指令调优数据集MMSci-Ins和一个包含3,114个测试样本的基准MMSci-Eval。此外,论文还采用了动态输入分辨率,允许模型根据表格的复杂程度调整输入图像的分辨率,从而更好地捕捉表格的细节。
技术框架:该框架主要包含三个组成部分:MMSci-Pre、MMSci-Ins和MMSci-Eval。MMSci-Pre是一个领域特定的表格结构学习数据集,用于预训练模型,使其能够更好地理解科学表格的结构。MMSci-Ins是一个指令调优数据集,用于微调模型,使其能够更好地完成基于表格的任务,例如表格问答、表格摘要等。MMSci-Eval是一个评估基准,用于评估模型在数值推理方面的能力。整个框架的目标是提升MLLMs在科学表格理解和数值推理方面的能力。
关键创新:论文的关键创新点在于以下几个方面:一是构建了一个领域特定的科学表格数据集MMSci-Pre,该数据集包含高质量的科学表格图像和结构信息;二是提出了一个指令调优数据集MMSci-Ins,该数据集包含多种基于表格的任务,可以有效地提升模型的数值推理能力;三是采用了动态输入分辨率,允许模型根据表格的复杂程度调整输入图像的分辨率,从而更好地捕捉表格的细节。与现有方法相比,该框架更加注重数据质量和模型的数值推理能力。
关键设计:关于动态输入分辨率的具体实现细节未知,论文中没有详细描述。损失函数和网络结构等技术细节也未在摘要中提及,需要查阅论文全文。
🖼️ 关键图片
📊 实验亮点
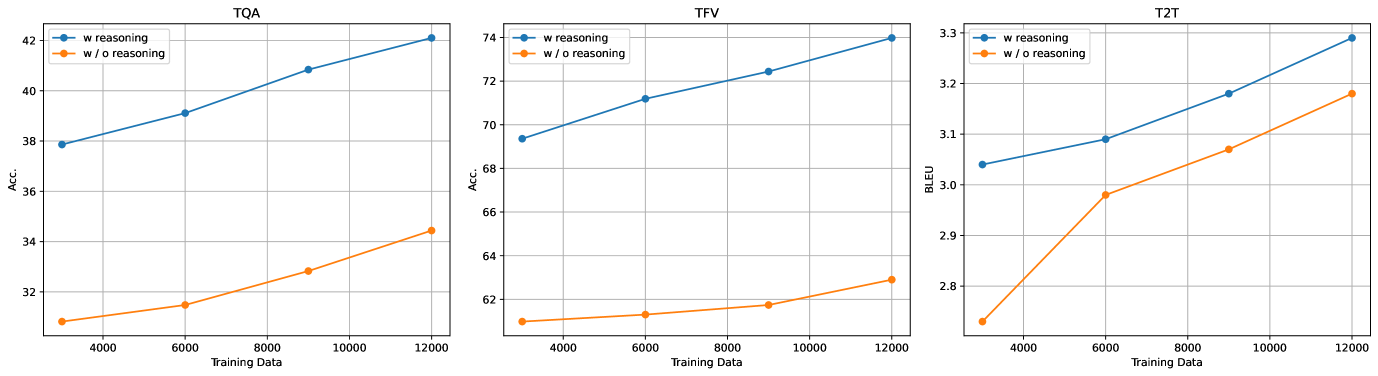
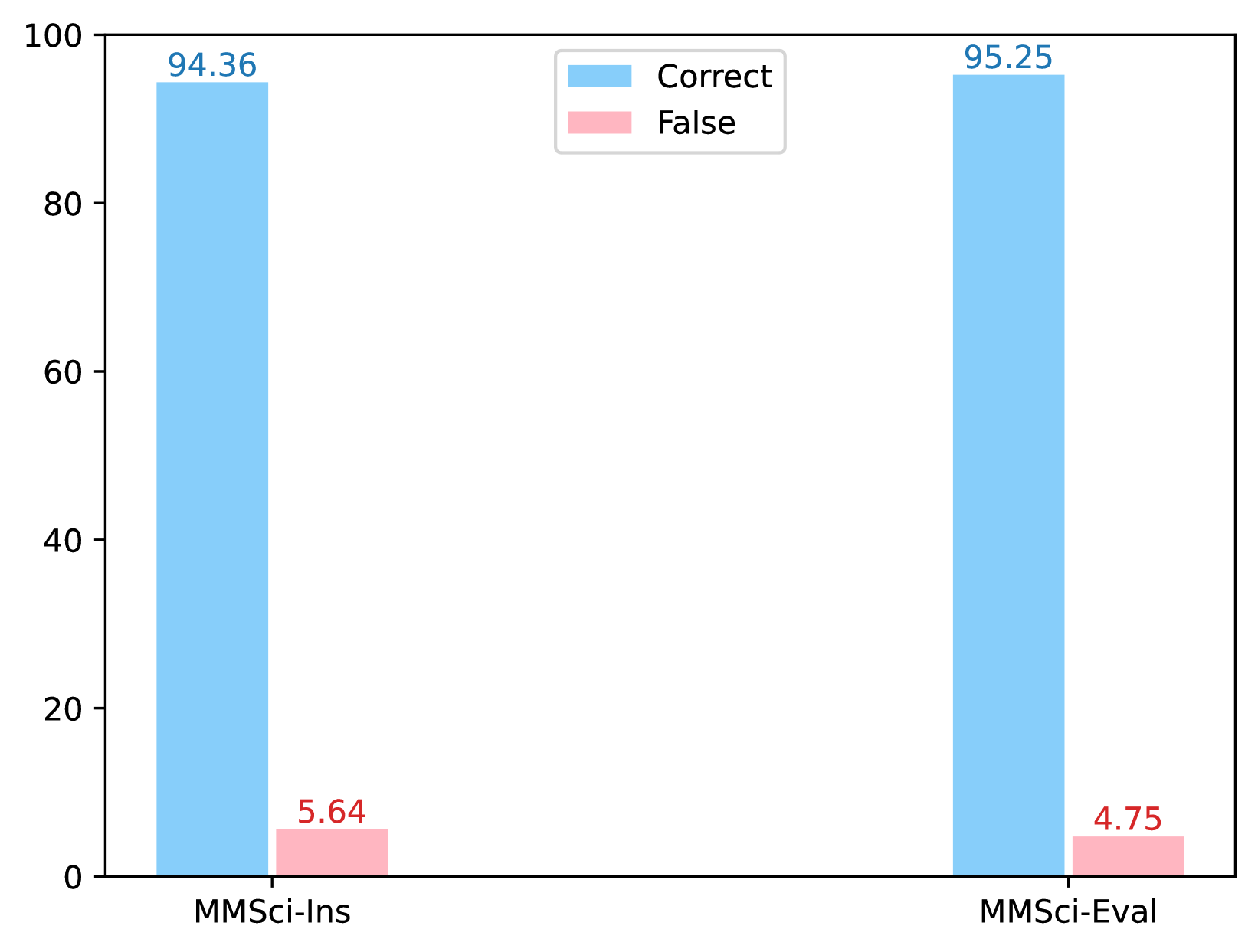
实验结果表明,使用52K科学表格图像训练的模型优于使用150K通用领域表格训练的模型,验证了数据质量的重要性。此外,采用动态输入分辨率的MLLMs在通用表格理解和数值推理能力方面都取得了显著的提升,并且在保留数据集上表现出良好的泛化能力。具体性能数据和提升幅度需要在论文中查找。
🎯 应用场景
该研究成果可应用于科学文献分析、数据挖掘、自动化报告生成等领域。通过提升模型对科学表格的理解和推理能力,可以帮助研究人员更高效地从海量数据中提取有用信息,加速科学发现的进程。未来,该技术有望应用于智能科研助手、自动化数据分析平台等产品中。
📄 摘要(原文)
Recent large language models (LLMs) have advanced table understanding capabilities but rely on converting tables into text sequences. While multimodal large language models (MLLMs) enable direct visual processing, they face limitations in handling scientific tables due to fixed input image resolutions and insufficient numerical reasoning capabilities. We present a comprehensive framework for multimodal scientific table understanding and reasoning with dynamic input image resolutions. Our framework consists of three key components: (1) MMSci-Pre, a domain-specific table structure learning dataset of 52K scientific table structure recognition samples, (2) MMSci-Ins, an instruction tuning dataset with 12K samples across three table-based tasks, and (3) MMSci-Eval, a benchmark with 3,114 testing samples specifically designed to evaluate numerical reasoning capabilities. Extensive experiments demonstrate that our domain-specific approach with 52K scientific table images achieves superior performance compared to 150K general-domain tables, highlighting the importance of data quality over quantity. Our proposed table-based MLLMs with dynamic input resolutions show significant improvements in both general table understanding and numerical reasoning capabilities, with strong generalisation to held-out datasets. Our code and data are publicly available at https://github.com/Bernard-Yang/MMSci_Table.