OnionEval: An Unified Evaluation of Fact-conflicting Hallucination for Small-Large Language Models
作者: Chongren Sun, Yuran Li, Di Wu, Benoit Boulet
分类: cs.CL
发布日期: 2025-01-22
💡 一句话要点
OnionEval:统一评估大小型语言模型中事实冲突性幻觉的框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 小型语言模型 幻觉评估 事实冲突 上下文推理 思维链 自然语言处理 OnionEval
📋 核心要点
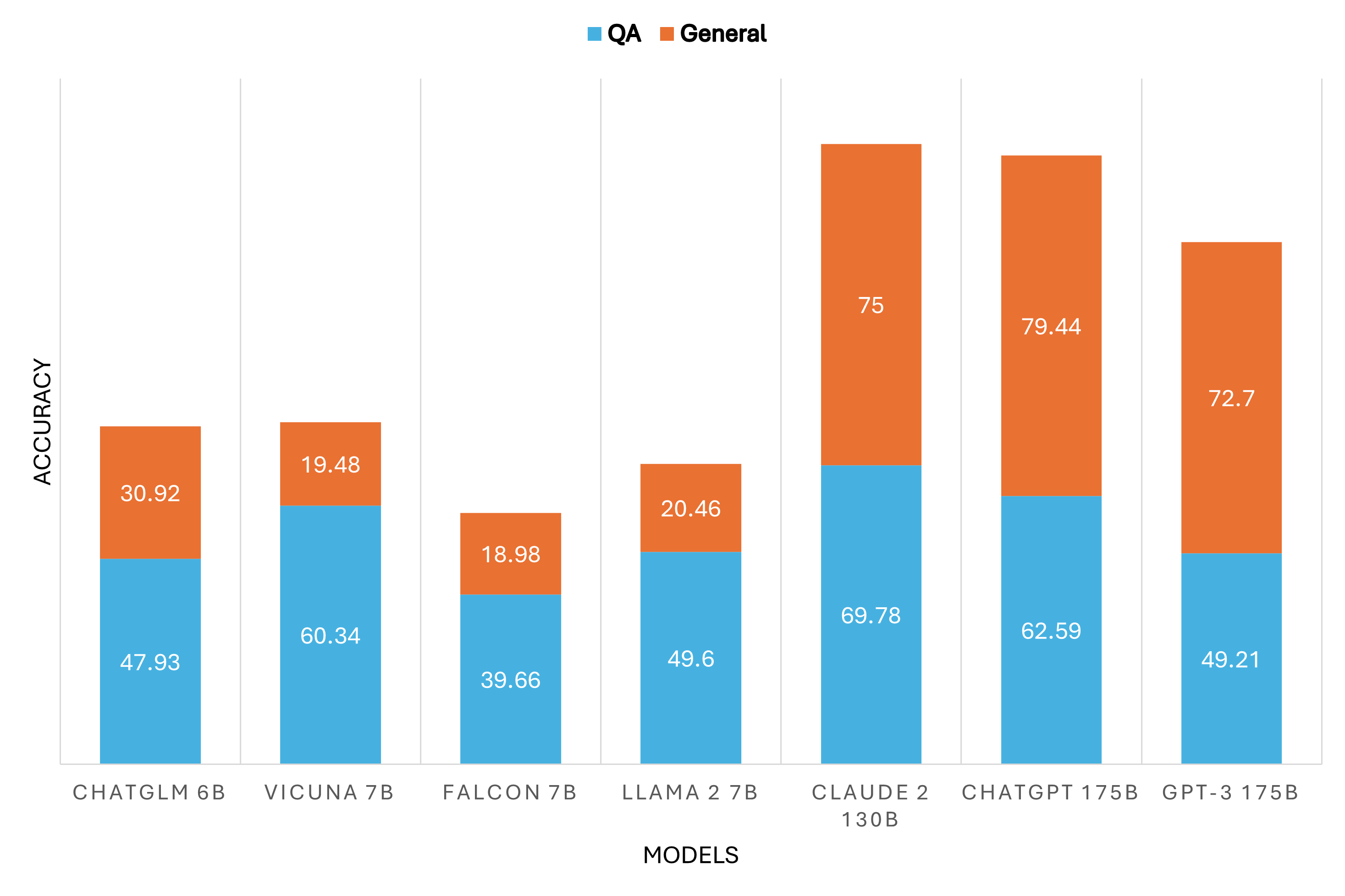
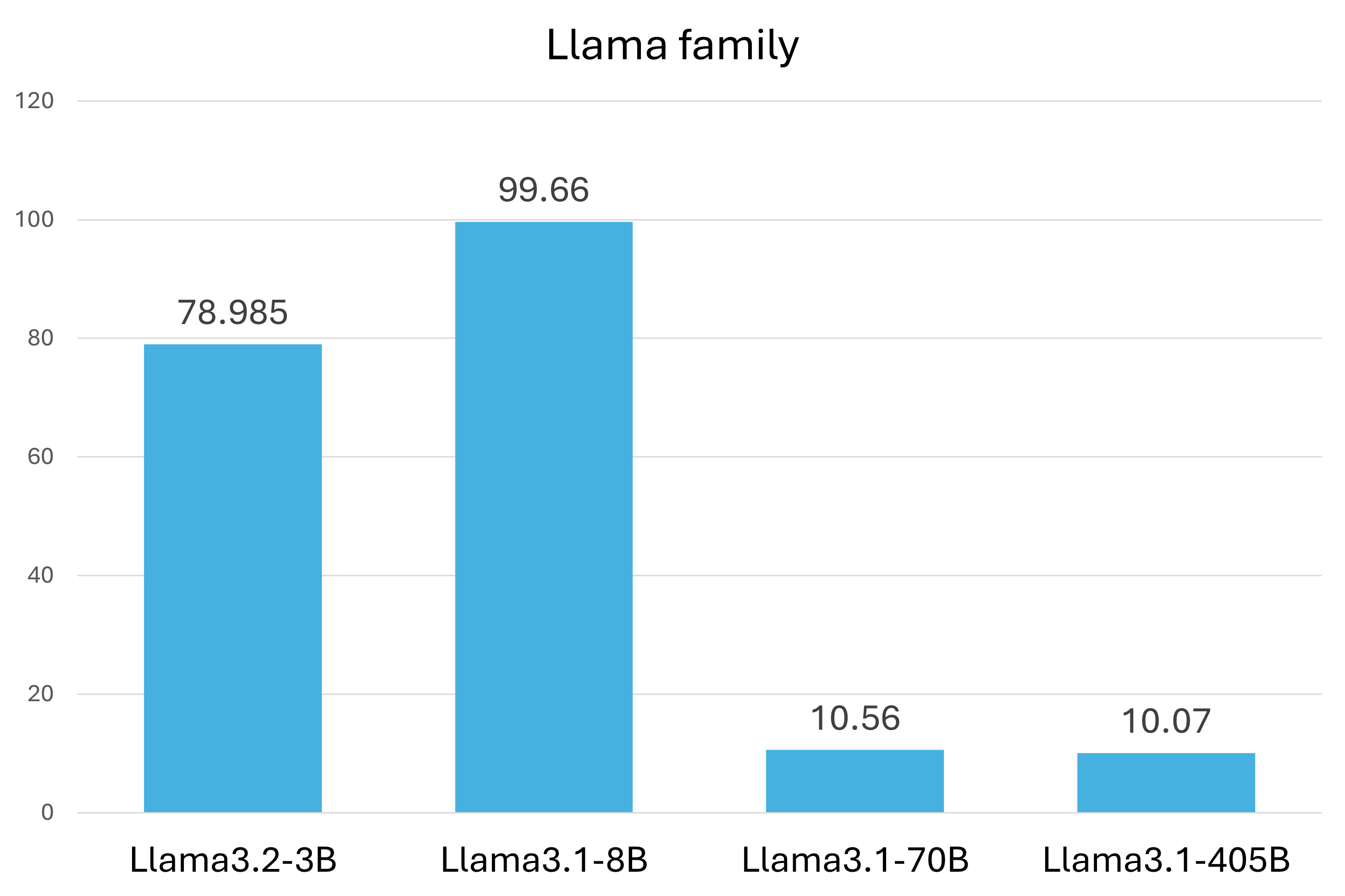
- 现有幻觉评估基准较少关注小型语言模型(SLLM),且SLLM在不同基准上表现差异大,缺乏统一评估标准。
- 提出OnionEval框架,通过多层结构和上下文影响分数(CI)来评估SLLM在不同上下文级别的事实冲突性幻觉。
- 实验表明SLLM擅长事实分析但上下文推理能力弱,而思维链策略能有效缓解这一问题,提升SLLM的实用性。
📝 摘要(中文)
大型语言模型(LLMs)能力强大,但训练和推理需要大量的计算资源。在LLM家族中,较小的模型(参数少于100亿)在各种任务中也表现良好。然而,这些较小的模型与较大的模型有相似的局限性,包括产生幻觉的倾向。尽管存在许多评估LLM中幻觉的基准,但很少有专门关注小型LLM(SLLM)的。此外,SLLM在不同的基准测试中表现出差异很大的性能。本文介绍了一种多层结构化框架OnionEval,以及一种称为上下文影响分数(CI)的特定指标,旨在有效地评估小型LLM在不同上下文级别上事实冲突性幻觉的倾向。实验结果揭示了SLLM的一个关键特征:它们擅长事实分析,但在上下文推理方面面临挑战。进一步的研究表明,一个简单的思维链策略可以显著减少这些限制,提高SLLM在实际应用中的实用性。
🔬 方法详解
问题定义:论文旨在解决小型语言模型(SLLM)中事实冲突性幻觉难以统一评估的问题。现有的大型语言模型(LLM)幻觉评估基准通常计算资源需求高,不适用于SLLM,并且SLLM在不同基准上的表现差异很大,缺乏一个能有效评估SLLM在不同上下文级别幻觉倾向的框架。
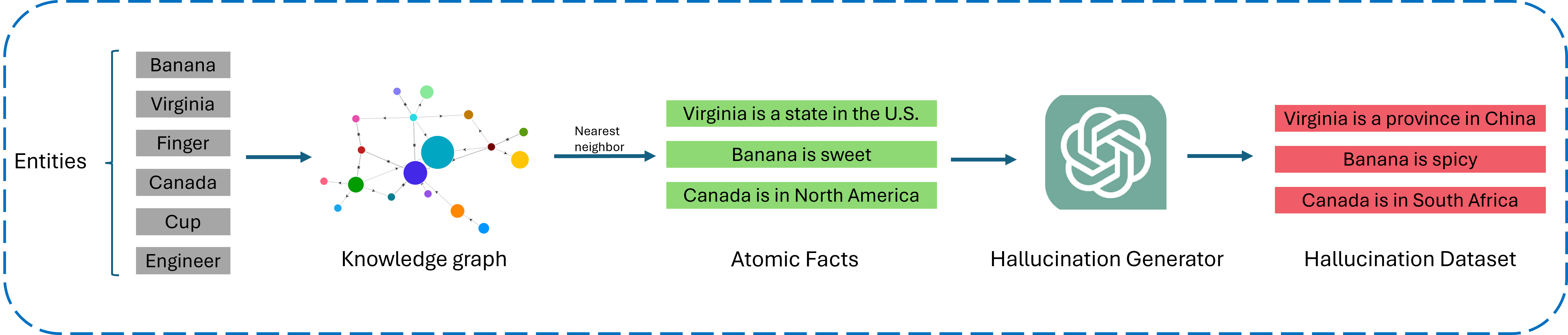
核心思路:论文的核心思路是构建一个多层结构化评估框架OnionEval,该框架模拟了洋葱的结构,从不同层次的上下文信息入手,评估SLLM在不同上下文信息下的幻觉情况。通过设计特定的指标,即上下文影响分数(CI),来量化上下文信息对SLLM生成结果的影响,从而更全面地评估SLLM的幻觉问题。
技术框架:OnionEval框架包含多个层次,每个层次代表不同程度的上下文信息。评估流程如下:1) 构建包含不同上下文信息的测试用例;2) 使用SLLM对测试用例进行回答;3) 利用上下文影响分数(CI)评估SLLM在不同上下文层次下的幻觉情况。CI分数越高,表明SLLM受上下文信息的影响越大,幻觉的可能性越低。
关键创新:OnionEval的关键创新在于其多层结构化的评估框架和上下文影响分数(CI)的设计。多层结构允许从不同粒度的上下文信息评估SLLM的幻觉情况,而CI分数提供了一种量化上下文信息影响的指标,使得幻觉评估更加客观和可比较。与现有方法相比,OnionEval更专注于SLLM,并考虑了上下文信息对幻觉的影响。
关键设计:上下文影响分数(CI)的计算方式未知,论文中可能包含其具体公式。此外,OnionEval框架中每个层次的上下文信息构建方式,以及如何选择合适的SLLM进行评估,都是关键的设计细节。论文还提到思维链(Chain-of-Thought)策略可以提升SLLM的性能,具体如何将思维链策略融入到SLLM中,也是一个重要的技术细节。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SLLM在事实分析方面表现良好,但在上下文推理方面存在挑战。通过引入简单的思维链策略,可以显著降低SLLM的幻觉倾向,提高其在实际应用中的性能。具体的性能提升幅度未知,需要在论文中查找。
🎯 应用场景
该研究成果可应用于开发更可靠的小型语言模型,尤其是在资源受限的环境中。例如,在移动设备、嵌入式系统或边缘计算场景中,可以使用经过OnionEval评估和优化的SLLM,以提供更准确、更可靠的自然语言处理服务,如智能助手、信息检索和文本生成。
📄 摘要(原文)
Large Language Models (LLMs) are highly capable but require significant computational resources for both training and inference. Within the LLM family, smaller models (those with fewer than 10 billion parameters) also perform well across various tasks. However, these smaller models share similar limitations to their larger counterparts, including the tendency to hallucinate. Despite the existence of many benchmarks to evaluate hallucination in LLMs, few have specifically focused on small LLMs (SLLMs). Additionally, SLLMs show widely varying performance across different benchmarks. In this paper, we introduce OnionEval, a multi-layer structured framework with a specific metric called the context-influence score (CI), designed to effectively assess the fact-conflicting hallucination tendencies of small LLMs across different contextual levels. Our experimental results reveal a key feature of SLLMs: they excel in factual analysis but face challenges with context reasoning. Further investigation shows that a simple Chain-of-Thought strategy can significantly reduce these limitations, improving the practical usefulness of SLLMs in real-world applications.