Efficient Prompt Compression with Evaluator Heads for Long-Context Transformer Inference
作者: Weizhi Fei, Xueyan Niu, Guoqing Xie, Yingqing Liu, Bo Bai, Wei Han
分类: cs.CL
发布日期: 2025-01-22 (更新: 2025-02-05)
💡 一句话要点
提出基于评估头的高效提示压缩方法,加速长文本Transformer推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 提示压缩 长文本推理 Transformer 注意力机制 评估头 模型加速 无监督学习
📋 核心要点
- 长文本处理对LLM至关重要,但计算成本高昂,性能下降。
- 提出EHPC方法,利用评估头选择关键tokens进行提示压缩,无需额外训练。
- EHPC在提示压缩和长文本推理加速方面达到SOTA,降低API调用成本。
📝 摘要(中文)
长文本输入对于大型语言模型(LLMs)的应用至关重要,但同时也增加了计算成本并降低了性能。为了解决这一挑战,我们提出了一种高效、免训练的提示压缩方法,该方法能够在压缩后的提示中保留关键信息。我们识别出基于Transformer的LLMs中的特定注意力头,将其指定为评估头,这些评估头能够选择长输入中对于推理最为重要的tokens。基于此,我们开发了EHPC,一种基于评估头的提示压缩方法,它使LLMs能够通过在预填充阶段仅利用前几层的评估头来快速“浏览”输入提示,随后仅将重要的tokens传递给模型进行推理。EHPC在两个主流基准测试(提示压缩和长文本推理加速)中取得了最先进的结果。因此,它有效地降低了商业API调用的复杂性和成本。我们进一步证明,与基于键值缓存的加速方法相比,EHPC取得了具有竞争力的结果,从而突显了其增强LLMs在长文本任务中的效率的潜力。
🔬 方法详解
问题定义:论文旨在解决长文本输入导致的大型语言模型推理效率降低和计算成本增加的问题。现有方法,如直接使用完整长文本,计算量大;而简单的截断或降采样可能丢失关键信息,影响模型性能。
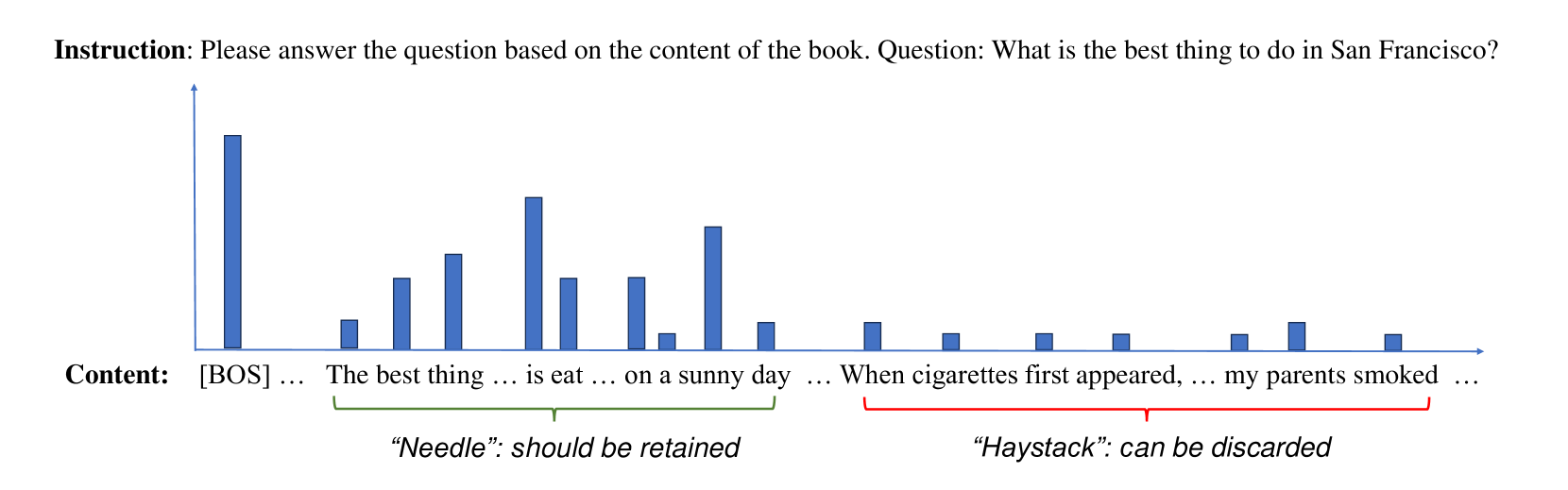
核心思路:论文的核心思路是识别并利用Transformer模型中具有评估token重要性能力的特定注意力头(称为评估头),通过这些评估头筛选出长文本输入中的关键tokens,从而实现提示压缩,减少计算量,同时保留关键信息。
技术框架:EHPC方法主要包含两个阶段:预填充阶段和推理阶段。在预填充阶段,仅使用模型的前几层(包含评估头)对完整输入进行处理,利用评估头选择重要tokens。然后,将选择出的重要tokens传递到模型的剩余层进行推理。整个过程无需额外的训练。
关键创新:EHPC的关键创新在于发现了Transformer模型中存在的“评估头”,并利用这些头进行无监督的提示压缩。与传统的提示压缩方法相比,EHPC无需训练,更加高效且易于部署。此外,EHPC直接在模型内部进行token选择,避免了外部压缩模块带来的额外开销。
关键设计:EHPC的关键设计包括:1) 评估头的选择标准:通过分析注意力权重,选择能够有效区分重要tokens的注意力头。2) 重要性评分函数:设计评分函数来量化每个token的重要性,例如基于注意力权重的统计量。3) tokens选择策略:根据重要性评分选择top-k个tokens,构成压缩后的提示。
🖼️ 关键图片


📊 实验亮点
EHPC在提示压缩和长文本推理加速两个主流基准测试中取得了SOTA结果。实验表明,EHPC能够显著降低计算成本,同时保持甚至提升模型性能。与基于键值缓存的加速方法相比,EHPC也展现出了具有竞争力的性能,证明了其在长文本处理方面的潜力。
🎯 应用场景
EHPC方法可广泛应用于需要处理长文本输入的各种场景,例如:长篇文档摘要、代码生成、对话系统、知识库问答等。通过降低计算成本和提高推理速度,EHPC能够有效提升LLM在这些场景中的实用性,并降低商业API的使用成本,具有重要的商业价值。
📄 摘要(原文)
Although applications involving long-context inputs are crucial for the effective utilization of large language models (LLMs), they also result in increased computational costs and reduced performance. To address this challenge, we propose an efficient, training-free prompt compression method that retains key information within compressed prompts. We identify specific attention heads in transformer-based LLMs, which we designate as evaluator heads, that are capable of selecting tokens in long inputs that are most significant for inference. Building on this discovery, we develop EHPC, an Evaluator Head-based Prompt Compression method, which enables LLMs to rapidly "skim through" input prompts by leveraging only the first few layers with evaluator heads during the pre-filling stage, subsequently passing only the important tokens to the model for inference. EHPC achieves state-of-the-art results across two mainstream benchmarks: prompt compression and long-context inference acceleration. Consequently, it effectively reduces the complexity and costs associated with commercial API calls. We further demonstrate that EHPC attains competitive results compared to key-value cache-based acceleration methods, thereby highlighting its potential to enhance the efficiency of LLMs for long-context tasks.