DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
作者: DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, Erhang Li, Fangyun Lin, Fucong Dai, Fuli Luo, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Han Bao, Hanwei Xu, Haocheng Wang, Honghui Ding, Huajian Xin, Huazuo Gao, Hui Qu, Hui Li, Jianzhong Guo, Jiashi Li, Jiawei Wang, Jingchang Chen, Jingyang Yuan, Junjie Qiu, Junlong Li, J. L. Cai, Jiaqi Ni, Jian Liang, Jin Chen, Kai Dong, Kai Hu, Kaige Gao, Kang Guan, Kexin Huang, Kuai Yu, Lean Wang, Lecong Zhang, Liang Zhao, Litong Wang, Liyue Zhang, Lei Xu, Leyi Xia, Mingchuan Zhang, Minghua Zhang, Minghui Tang, Meng Li, Miaojun Wang, Mingming Li, Ning Tian, Panpan Huang, Peng Zhang, Qiancheng Wang, Qinyu Chen, Qiushi Du, Ruiqi Ge, Ruisong Zhang, Ruizhe Pan, Runji Wang, R. J. Chen, R. L. Jin, Ruyi Chen, Shanghao Lu, Shangyan Zhou, Shanhuang Chen, Shengfeng Ye, Shiyu Wang, Shuiping Yu, Shunfeng Zhou, Shuting Pan, S. S. Li, Shuang Zhou, Shaoqing Wu, Shengfeng Ye, Tao Yun, Tian Pei, Tianyu Sun, T. Wang, Wangding Zeng, Wanjia Zhao, Wen Liu, Wenfeng Liang, Wenjun Gao, Wenqin Yu, Wentao Zhang, W. L. Xiao, Wei An, Xiaodong Liu, Xiaohan Wang, Xiaokang Chen, Xiaotao Nie, Xin Cheng, Xin Liu, Xin Xie, Xingchao Liu, Xinyu Yang, Xinyuan Li, Xuecheng Su, Xuheng Lin, X. Q. Li, Xiangyue Jin, Xiaojin Shen, Xiaosha Chen, Xiaowen Sun, Xiaoxiang Wang, Xinnan Song, Xinyi Zhou, Xianzu Wang, Xinxia Shan, Y. K. Li, Y. Q. Wang, Y. X. Wei, Yang Zhang, Yanhong Xu, Yao Li, Yao Zhao, Yaofeng Sun, Yaohui Wang, Yi Yu, Yichao Zhang, Yifan Shi, Yiliang Xiong, Ying He, Yishi Piao, Yisong Wang, Yixuan Tan, Yiyang Ma, Yiyuan Liu, Yongqiang Guo, Yuan Ou, Yuduan Wang, Yue Gong, Yuheng Zou, Yujia He, Yunfan Xiong, Yuxiang Luo, Yuxiang You, Yuxuan Liu, Yuyang Zhou, Y. X. Zhu, Yanhong Xu, Yanping Huang, Yaohui Li, Yi Zheng, Yuchen Zhu, Yunxian Ma, Ying Tang, Yukun Zha, Yuting Yan, Z. Z. Ren, Zehui Ren, Zhangli Sha, Zhe Fu, Zhean Xu, Zhenda Xie, Zhengyan Zhang, Zhewen Hao, Zhicheng Ma, Zhigang Yan, Zhiyu Wu, Zihui Gu, Zijia Zhu, Zijun Liu, Zilin Li, Ziwei Xie, Ziyang Song, Zizheng Pan, Zhen Huang, Zhipeng Xu, Zhongyu Zhang, Zhen Zhang
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-01-22 (更新: 2026-01-04)
期刊: Nature volume 645, pages 633-638 (2025)
DOI: 10.1038/s41586-025-09422-z
💡 一句话要点
DeepSeek-R1:通过强化学习激励LLM的推理能力,无需人工标注
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 推理能力 自主学习 奖励函数
📋 核心要点
- 现有LLM推理能力依赖大量人工标注数据,且在复杂问题上表现不足,限制了其通用性。
- 提出基于纯强化学习的框架,激励LLM涌现高级推理模式,无需人工标注推理轨迹。
- 实验表明,该方法在数学、编程等可验证任务上超越了传统监督学习方法。
📝 摘要(中文)
通用推理是人工智能领域一个长期存在的巨大挑战。最近大型语言模型(LLM)和思维链提示的突破,在基础推理任务上取得了显著成功。然而,这种成功严重依赖于大量人工标注的演示数据,并且模型的能力对于更复杂的问题仍然不足。本文表明,LLM的推理能力可以通过纯强化学习(RL)来激励,从而避免了对人工标注推理轨迹的需求。所提出的RL框架促进了高级推理模式的涌现发展,例如自我反思、验证和动态策略适应。因此,训练后的模型在可验证的任务(如数学、编程竞赛和STEM领域)上取得了优异的性能,超过了通过传统监督学习在人工演示数据上训练的同类模型。此外,这些大规模模型所表现出的涌现推理模式可以被系统地利用,以指导和增强较小模型的推理能力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在复杂推理任务中对大量人工标注数据的依赖问题。现有方法,如监督学习,需要大量人工标注的推理轨迹,成本高昂且难以扩展。此外,现有模型在面对需要自我反思、验证和动态策略调整的复杂问题时,推理能力仍然不足。
核心思路:论文的核心思路是通过强化学习(RL)来激励LLM的推理能力,使其能够自主学习并涌现出高级推理模式,而无需人工标注的推理轨迹。通过设计合适的奖励函数,引导模型探索和学习有效的推理策略。
技术框架:整体框架包含以下几个主要部分:1) LLM作为智能体,接收问题作为输入,并生成推理步骤;2) 环境模拟器,用于评估LLM生成的推理步骤的正确性,并提供奖励信号;3) 强化学习算法,用于更新LLM的策略,使其能够生成更有效的推理步骤。该框架采用迭代训练的方式,通过不断与环境交互,LLM逐渐学习到高级推理模式。
关键创新:最重要的技术创新点在于使用纯强化学习来训练LLM的推理能力,从而避免了对人工标注数据的依赖。此外,该方法能够使LLM涌现出自我反思、验证和动态策略调整等高级推理模式,这些模式在传统的监督学习方法中难以实现。
关键设计:奖励函数的设计是关键。论文设计了基于任务完成情况的奖励,例如,如果LLM成功解决了数学问题,则获得正奖励;如果LLM的推理步骤出现错误,则获得负奖励。此外,论文还探索了不同的强化学习算法,例如策略梯度方法,用于更新LLM的策略。具体的网络结构和参数设置在论文中有详细描述,但此处未知。
🖼️ 关键图片
📊 实验亮点
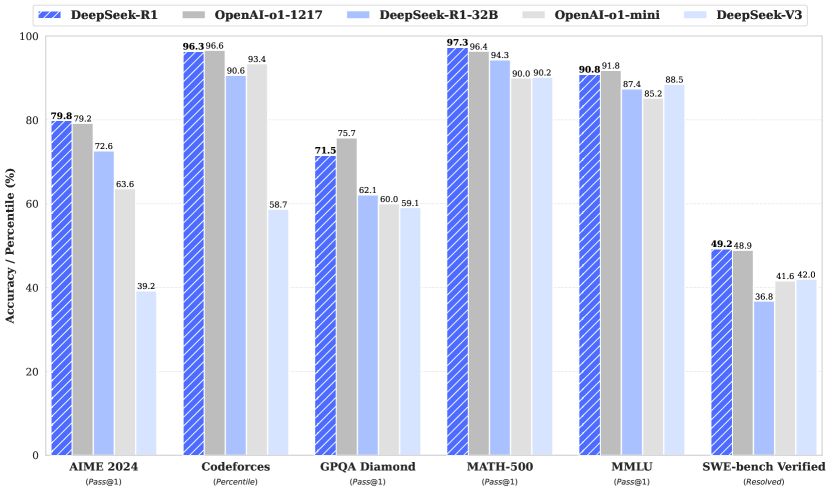
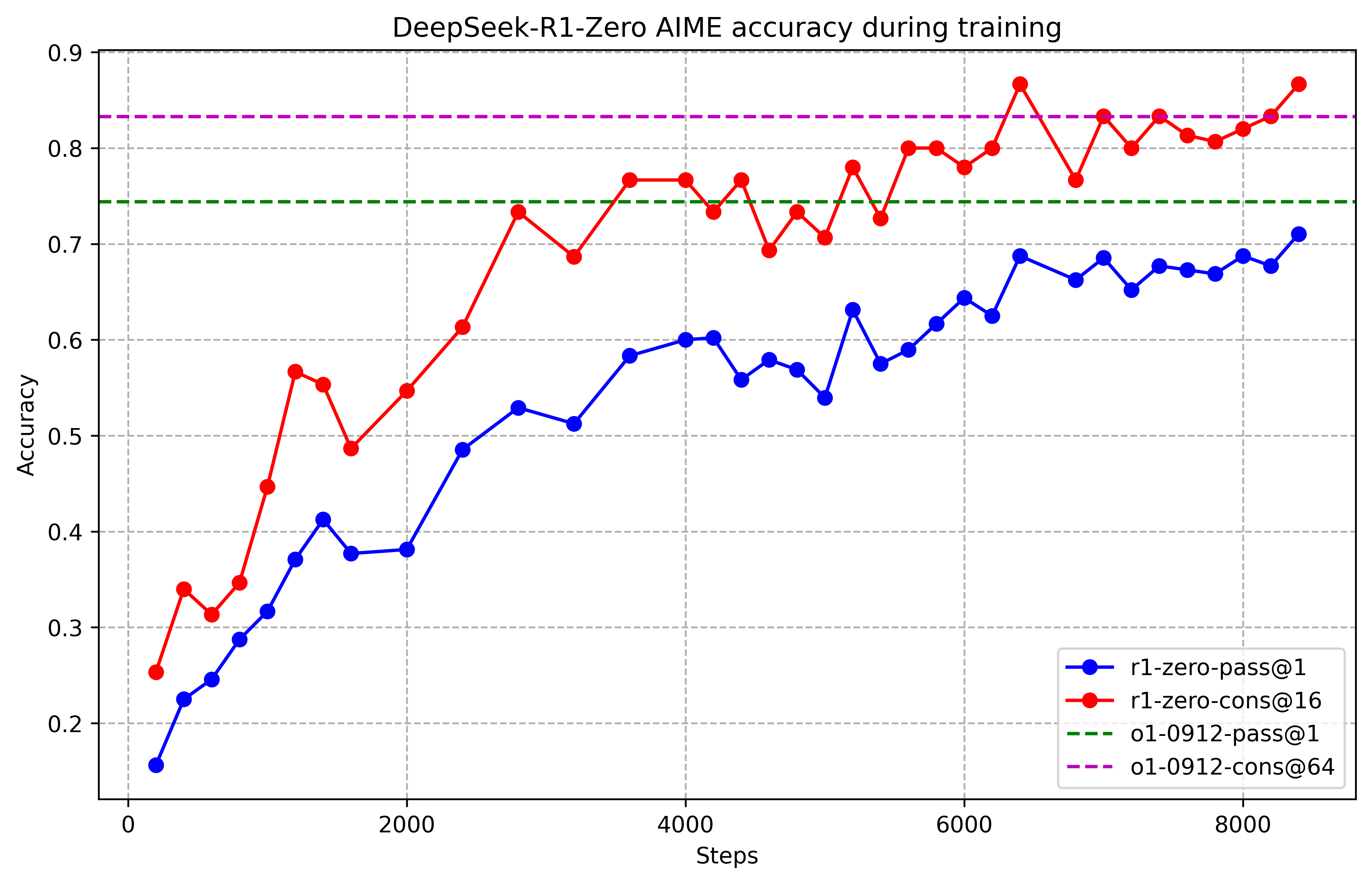
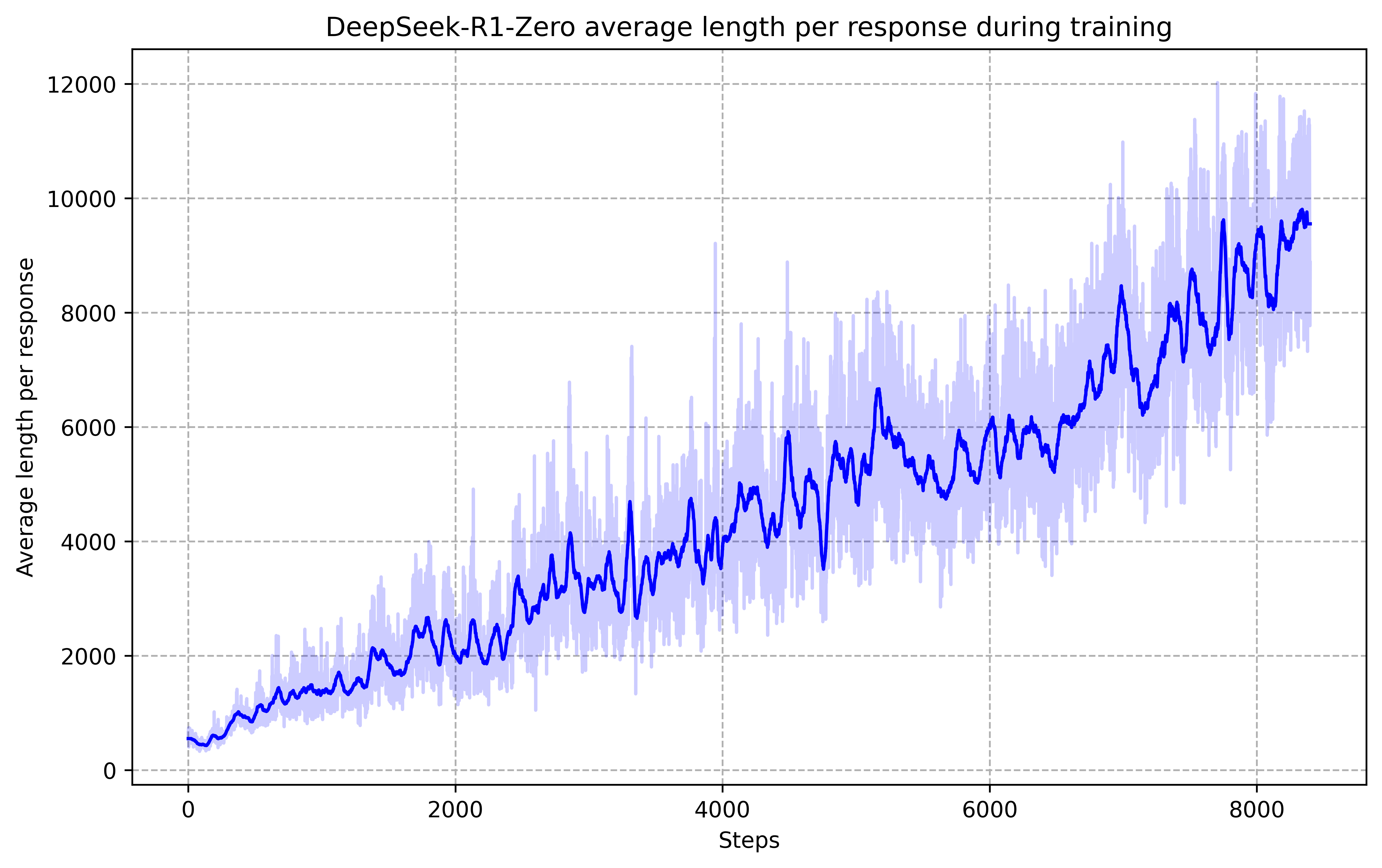
实验结果表明,通过强化学习训练的LLM在数学、编程竞赛和STEM领域等可验证任务上取得了显著的性能提升,超越了通过传统监督学习在人工演示数据上训练的同类模型。具体的性能数据和提升幅度在论文中有详细描述,但此处未知。
🎯 应用场景
该研究成果可广泛应用于需要复杂推理能力的领域,如数学问题求解、代码生成、科学研究等。通过强化学习训练的LLM可以作为智能助手,帮助人们解决各种复杂问题,提高工作效率。此外,该方法还可以用于指导和增强较小模型的推理能力,降低模型部署成本。
📄 摘要(原文)
General reasoning represents a long-standing and formidable challenge in artificial intelligence. Recent breakthroughs, exemplified by large language models (LLMs) and chain-of-thought prompting, have achieved considerable success on foundational reasoning tasks. However, this success is heavily contingent upon extensive human-annotated demonstrations, and models' capabilities are still insufficient for more complex problems. Here we show that the reasoning abilities of LLMs can be incentivized through pure reinforcement learning (RL), obviating the need for human-labeled reasoning trajectories. The proposed RL framework facilitates the emergent development of advanced reasoning patterns, such as self-reflection, verification, and dynamic strategy adaptation. Consequently, the trained model achieves superior performance on verifiable tasks such as mathematics, coding competitions, and STEM fields, surpassing its counterparts trained via conventional supervised learning on human demonstrations. Moreover, the emergent reasoning patterns exhibited by these large-scale models can be systematically harnessed to guide and enhance the reasoning capabilities of smaller models.