ACEBench: Who Wins the Match Point in Tool Usage?
作者: Chen Chen, Xinlong Hao, Weiwen Liu, Xu Huang, Xingshan Zeng, Shuai Yu, Dexun Li, Shuai Wang, Weinan Gan, Yuefeng Huang, Wulong Liu, Xinzhi Wang, Defu Lian, Baoqun Yin, Yasheng Wang, Wu Liu
分类: cs.CL
发布日期: 2025-01-22 (更新: 2025-11-20)
💡 一句话要点
ACEBench:评估LLM工具使用能力的多维度综合基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 工具使用 评估基准 多轮对话 智能体交互
📋 核心要点
- 现有工具使用评估基准缺乏真实多轮对话场景,评估维度单一,且依赖LLM或API执行,成本高昂。
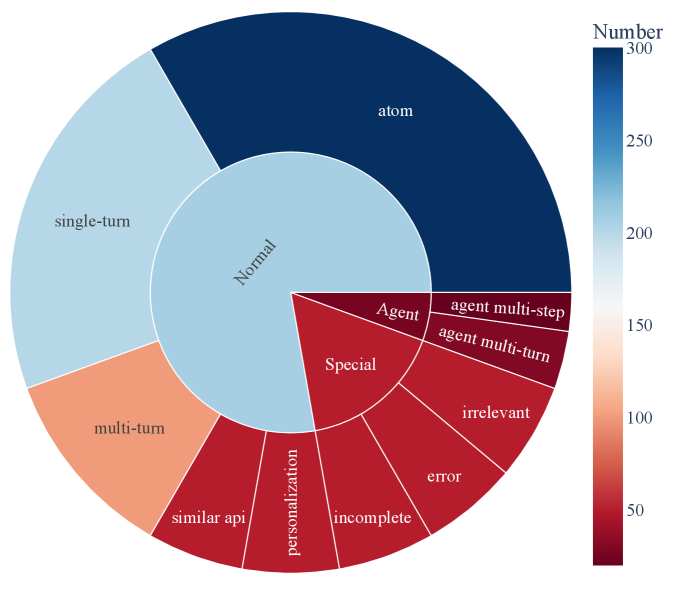
- ACEBench通过Normal、Special和Agent三种数据类型,模拟不同复杂度的场景,全面评估LLM的工具使用能力。
- 实验结果表明,ACEBench能够更细致地分析LLM在不同场景下的工具使用错误,为改进LLM提供指导。
📝 摘要(中文)
大型语言模型(LLMs)在决策和推理方面展现出巨大潜力,尤其是在与各种工具集成以有效解决复杂问题时。然而,现有的LLM工具使用评估基准存在以下局限性:(1)评估场景有限,通常缺乏在真实多轮对话环境中的评估;(2)评估维度狭窄,对LLM如何使用工具的详细评估不足;(3)依赖LLM或真实API执行进行评估,这带来了显著的开销。为了应对这些挑战,我们推出了ACEBench,这是一个用于评估LLM工具使用的综合基准。ACEBench根据评估方法将数据分为三种主要类型:Normal、Special和Agent。“Normal”评估基本场景中的工具使用;“Special”评估在具有模糊或不完整指令情况下的工具使用;“Agent”通过多智能体交互评估工具使用,以模拟真实世界的多轮对话。我们使用ACEBench进行了广泛的实验,深入分析了各种LLM,并对不同数据类型的错误原因进行了更细致的检查。
🔬 方法详解
问题定义:现有的大语言模型工具使用评估基准存在场景覆盖不足、评估维度单一以及评估成本过高等问题。具体来说,现有基准缺乏对真实多轮对话场景的模拟,难以评估LLM在复杂交互环境下的工具使用能力。同时,对LLM工具使用过程的细节评估不足,难以定位LLM的错误原因。此外,依赖LLM自身或真实API执行进行评估,导致评估成本较高。
核心思路:ACEBench的核心思路是通过构建一个多维度、多场景的综合性基准,全面评估LLM的工具使用能力。该基准通过设计不同类型的数据,模拟不同复杂度的场景,从而更真实地反映LLM在实际应用中的表现。同时,ACEBench注重对LLM工具使用过程的细节评估,以便更准确地分析LLM的错误原因。
技术框架:ACEBench的整体框架包括数据收集与标注、评估指标设计以及实验分析三个主要部分。数据收集与标注阶段,构建了Normal、Special和Agent三种类型的数据,分别对应基本场景、模糊指令场景和多智能体交互场景。评估指标设计阶段,针对不同类型的数据,设计了相应的评估指标,例如准确率、召回率等。实验分析阶段,使用ACEBench对多种LLM进行评估,并分析LLM在不同场景下的表现。
关键创新:ACEBench的关键创新在于其多维度、多场景的评估体系。与现有基准相比,ACEBench不仅考虑了LLM在基本场景下的工具使用能力,还考虑了LLM在模糊指令和多智能体交互等复杂场景下的表现。这种多维度的评估体系能够更全面地反映LLM的工具使用能力。
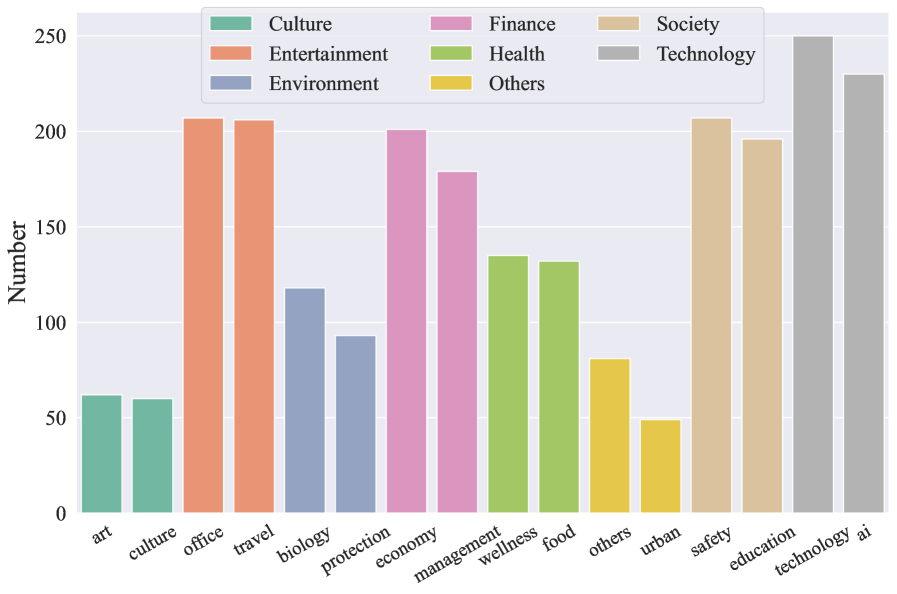
关键设计:ACEBench的关键设计包括三种数据类型的构建方式以及评估指标的设计。Normal类型的数据主要通过人工编写或自动生成的方式构建,Special类型的数据则通过引入模糊或不完整的指令来模拟真实场景中的不确定性,Agent类型的数据则通过设计多智能体交互场景来模拟真实世界的多轮对话。评估指标方面,针对不同类型的数据,设计了相应的评估指标,例如准确率、召回率、一致性等。
🖼️ 关键图片

📊 实验亮点
ACEBench对多种LLM进行了评估,结果表明,不同LLM在不同类型的数据上表现差异显著。例如,某些LLM在Normal类型的数据上表现良好,但在Special和Agent类型的数据上表现较差。这些结果表明,ACEBench能够有效区分不同LLM的工具使用能力,并为LLM的改进提供指导。
🎯 应用场景
ACEBench可用于评估和改进大型语言模型在各种实际应用中的工具使用能力,例如智能助手、自动化客服、智能家居控制等。通过ACEBench的评估,可以更好地了解LLM在不同场景下的表现,从而有针对性地改进LLM的工具使用策略,提高LLM的实用性。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated significant potential in decision-making and reasoning, particularly when integrated with various tools to effectively solve complex problems. However, existing benchmarks for evaluating LLMs' tool usage face several limitations: (1) limited evaluation scenarios, often lacking assessments in real multi-turn dialogue contexts; (2) narrow evaluation dimensions, with insufficient detailed assessments of how LLMs use tools; and (3) reliance on LLMs or real API executions for evaluation, which introduces significant overhead. To address these challenges, we introduce ACEBench, a comprehensive benchmark for assessing tool usage in LLMs. ACEBench categorizes data into three primary types based on evaluation methodology: Normal, Special, and Agent. "Normal" evaluates tool usage in basic scenarios; "Special" evaluates tool usage in situations with ambiguous or incomplete instructions; "Agent" evaluates tool usage through multi-agent interactions to simulate real-world, multi-turn dialogues. We conducted extensive experiments using ACEBench, analyzing various LLMs in-depth and providing a more granular examination of error causes across different data types.