LLMs as Repositories of Factual Knowledge: Limitations and Solutions
作者: Seyed Mahed Mousavi, Simone Alghisi, Giuseppe Riccardi
分类: cs.CL
发布日期: 2025-01-22
💡 一句话要点
提出实体感知微调(ENAF),提升LLM在时效性事实知识问答中的准确性和一致性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 事实知识 时间敏感性 知识图谱 微调
📋 核心要点
- 现有LLM在处理时效性事实知识时,面临数据更新和信息源不一致带来的准确性和一致性挑战。
- 论文提出实体感知微调(ENAF)方法,通过在微调阶段引入实体的结构化表示,提升模型对事实的理解和记忆。
- 实验结果表明,ENAF方法能够有效提高LLM在时间敏感事实问答任务中的准确性和一致性。
📝 摘要(中文)
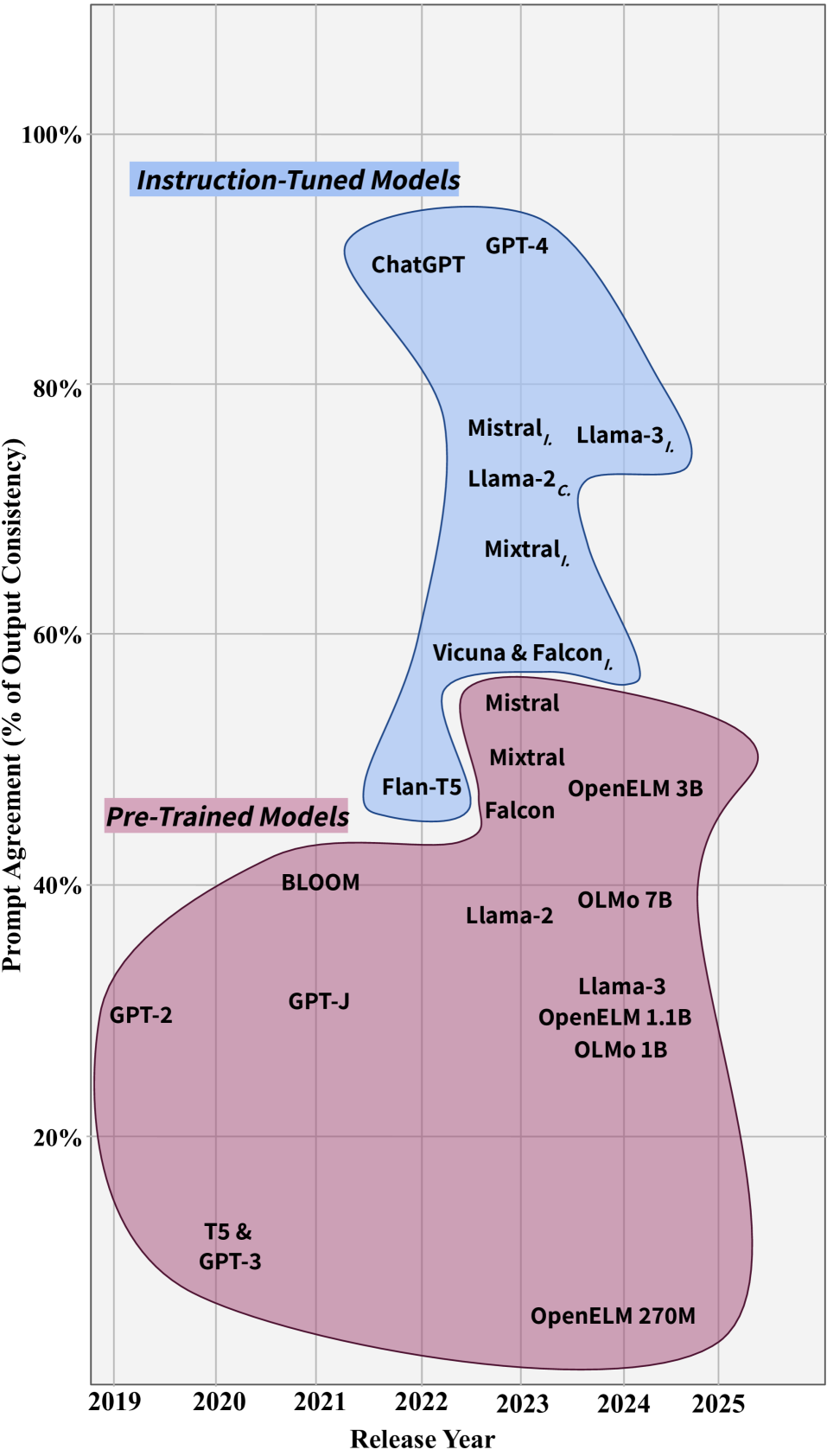
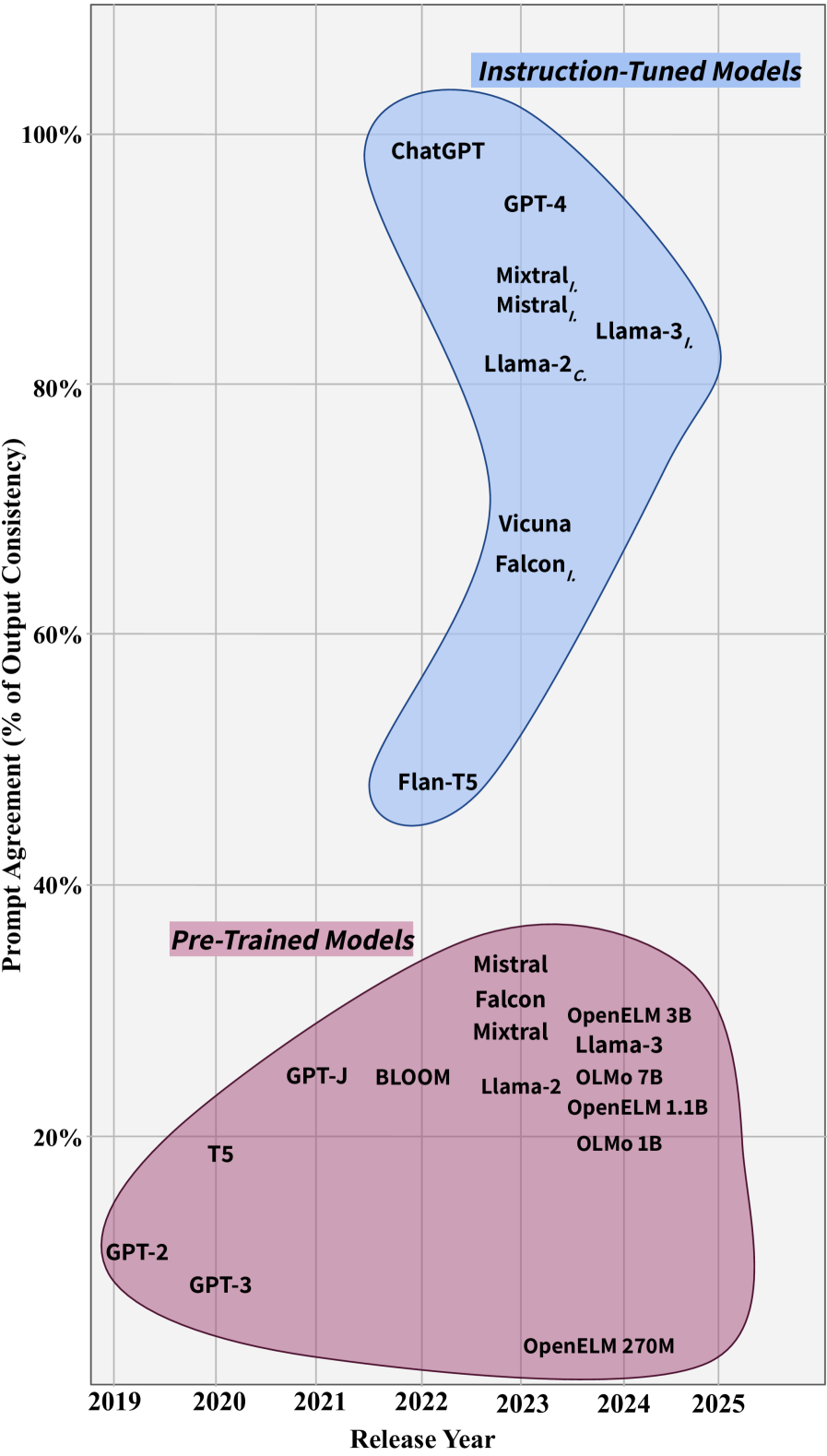
大型语言模型(LLM)的知识来源是数据快照,其中包含在不同时间戳从不同媒体类型(例如维基、社交媒体等)收集的关于实体的事实信息。这种非结构化知识会随着时间的推移而发生变化。同样重要的是不同信息来源中出现的不一致和不准确。因此,模型在训练或推理过程中,关于某个实体的知识可能会受到扰动,从而导致不一致和不准确的模型性能。本文研究了大型语言模型(LLM)作为事实知识存储库的适当性。我们考虑了24个最先进的LLM,它们是封闭源代码、部分(权重)开源或完全(权重和训练数据)开源的。我们评估了它们在回答时间敏感的事实问题时的可靠性,包括准确性和在提示受到扰动时的一致性。我们进一步评估了现有方法在提高LLM准确性和一致性方面的有效性。然后,我们提出“实体感知微调”(ENAF),这是一种软神经符号方法,旨在在微调期间提供实体的结构化表示,以提高模型的性能。
🔬 方法详解
问题定义:论文旨在解决LLM作为事实知识库时,由于训练数据的时间快照特性和信息源的不一致性,导致模型在回答时间敏感的事实性问题时出现准确性和一致性问题。现有方法难以有效应对知识更新和信息冲突带来的挑战。
核心思路:论文的核心思路是在微调阶段,通过引入实体的结构化表示,让模型更好地理解和记忆事实信息。这种结构化表示可以帮助模型区分不同时间点的事实,并解决信息冲突。
技术框架:ENAF方法主要包含以下几个阶段:1) 收集时间敏感的事实性问题数据集;2) 对LLM进行微调,在微调过程中,将实体信息以结构化的形式输入模型;3) 使用微调后的模型回答事实性问题,并评估其准确性和一致性。
关键创新:ENAF的关键创新在于引入了“实体感知”的概念,将实体信息以结构化的形式融入到微调过程中。这种方法不同于传统的微调方法,后者通常只关注文本信息,而忽略了实体之间的关系和时间信息。
关键设计:ENAF采用了一种软神经符号方法,将实体信息编码为向量表示,并将其与文本信息融合。具体来说,论文可能使用了知识图谱嵌入、实体链接等技术来获取实体的结构化表示。损失函数的设计可能考虑了准确性和一致性两个方面,例如,可以使用交叉熵损失来衡量准确性,并使用某种正则化项来鼓励模型输出一致的结果。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了ENAF方法的有效性。实验结果表明,ENAF方法能够显著提高LLM在时间敏感事实问答任务中的准确性和一致性。具体的性能数据和对比基线需要在论文中查找,但总体趋势是ENAF优于现有方法。
🎯 应用场景
该研究成果可应用于智能问答系统、搜索引擎、知识图谱构建等领域。通过提高LLM在时效性事实知识问答中的准确性和一致性,可以提升用户体验,并为决策提供更可靠的信息支持。未来,该方法有望应用于更广泛的知识密集型任务。
📄 摘要(原文)
LLMs' sources of knowledge are data snapshots containing factual information about entities collected at different timestamps and from different media types (e.g. wikis, social media, etc.). Such unstructured knowledge is subject to change due to updates through time from past to present. Equally important are the inconsistencies and inaccuracies occurring in different information sources. Consequently, the model's knowledge about an entity may be perturbed while training over the sequence of snapshots or at inference time, resulting in inconsistent and inaccurate model performance. In this work, we study the appropriateness of Large Language Models (LLMs) as repositories of factual knowledge. We consider twenty-four state-of-the-art LLMs that are either closed-, partially (weights), or fully (weight and training data) open-source. We evaluate their reliability in responding to time-sensitive factual questions in terms of accuracy and consistency when prompts are perturbed. We further evaluate the effectiveness of state-of-the-art methods to improve LLMs' accuracy and consistency. We then propose "ENtity-Aware Fine-tuning" (ENAF), a soft neurosymbolic approach aimed at providing a structured representation of entities during fine-tuning to improve the model's performance.