Training Dialogue Systems by AI Feedback for Improving Overall Dialogue Impression
作者: Kai Yoshida, Masahiro Mizukami, Seiya Kawano, Canasai Kruengkrai, Hiroaki Sugiyama, Koichiro Yoshino
分类: cs.CL
发布日期: 2025-01-22 (更新: 2025-01-25)
备注: Accepted to ICASSP 2025
💡 一句话要点
利用AI反馈训练对话系统,提升整体对话体验
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话系统 AI反馈 强化学习 奖励模型 监督微调
📋 核心要点
- 现有对话系统难以有效评估和优化对话的整体印象,如一致性、个性等。
- 利用监督微调构建多个奖励模型,分别对应不同的对话印象指标,为对话模型提供更细粒度的反馈信号。
- 实验结果表明,该方法能够提升对话的自然度和各项印象指标的评分。
📝 摘要(中文)
为了提升对话系统中用户交互的参与度,本文旨在改进对话回复的质量以及对话的整体印象,例如一致性、个性化和共情能力。大型语言模型(LLMs)的快速发展推动了对话系统的进步,而基于AI反馈的强化学习(RLAIF)为对齐LLM驱动的对话模型以提升对话印象提供了新思路。 RLAIF通常使用另一个LLM作为奖励模型,通过zero-shot/few-shot prompting技术为LLM对话模型生成训练信号。然而,仅通过prompting LLM来评估整个对话是具有挑战性的。本文通过监督微调(SFT)LLM,构建了12个与对话整体印象相关的指标的奖励模型,用于评估对话回复。我们使用这些奖励模型的信号作为反馈来调整对话模型,从而改善系统给人的印象。自动评估和人工评估结果表明,使用与对话印象相对应的奖励模型来调整对话模型,能够提升单个指标的评估结果以及对话回复的自然度。
🔬 方法详解
问题定义:现有对话系统在提升用户参与度方面面临挑战,尤其是在对话的整体印象方面,例如一致性、个性化和共情能力。仅仅依赖大型语言模型(LLMs)的prompting难以准确评估整个对话的质量,从而限制了对话系统在这些方面的提升。现有的奖励模型构建方法不够精细,无法针对不同的对话印象指标进行优化。
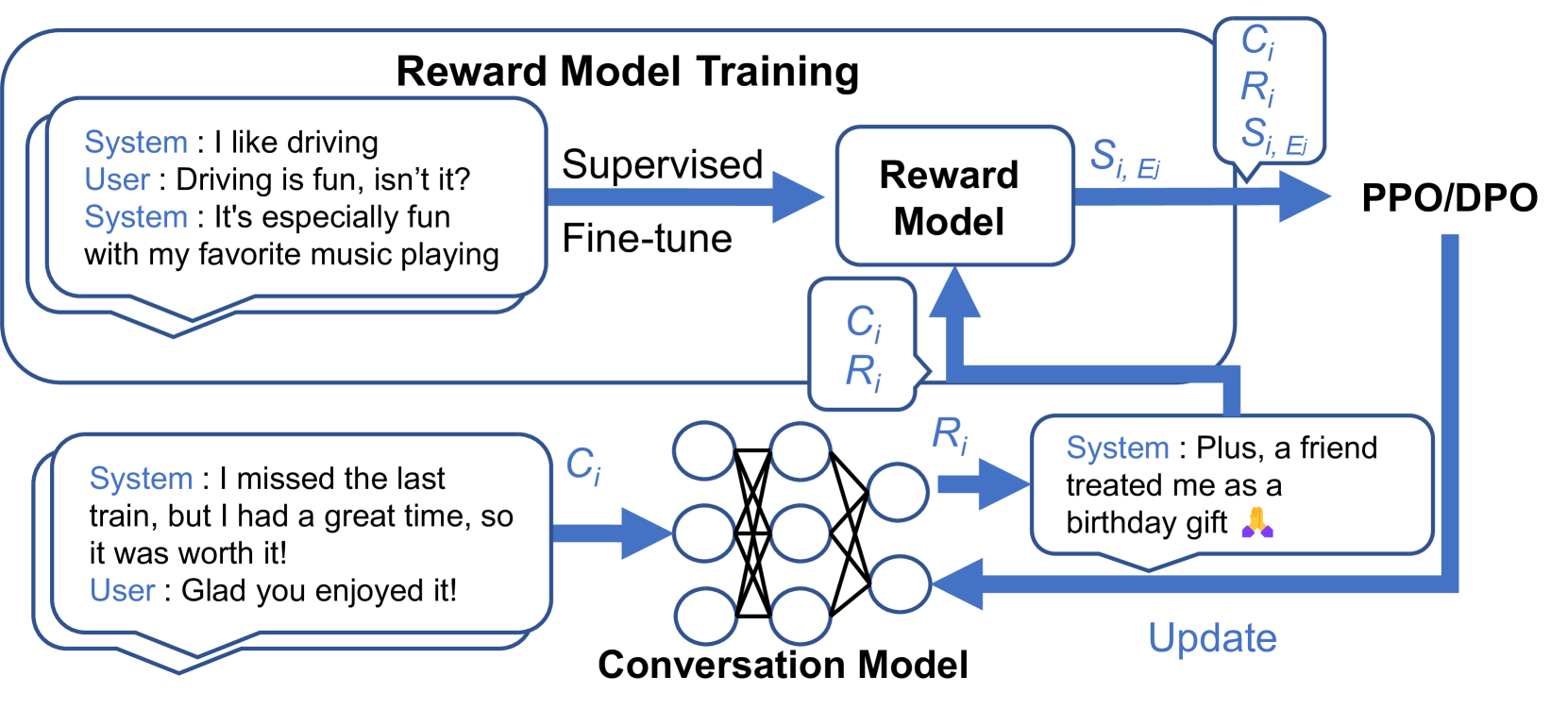
核心思路:本文的核心思路是构建多个专门针对不同对话印象指标的奖励模型,并利用这些奖励模型提供的反馈信号来训练对话模型。通过监督微调(SFT)LLM,使每个奖励模型能够更准确地评估对话在特定方面的表现。这种细粒度的反馈机制能够更有效地指导对话模型的训练,从而提升对话的整体质量。
技术框架:该方法的技术框架主要包含以下几个阶段:1) 数据收集:收集用于训练奖励模型和对话模型的数据集。2) 奖励模型构建:针对12个不同的对话印象指标,分别使用监督微调(SFT)训练LLM,构建相应的奖励模型。3) 对话模型训练:使用奖励模型提供的反馈信号,通过强化学习或其他优化方法,调整对话模型的参数,使其能够生成更符合人类期望的对话。4) 评估:使用自动评估指标和人工评估方法,评估对话模型的性能,并与基线模型进行比较。
关键创新:该方法最重要的技术创新点在于构建了多个针对不同对话印象指标的奖励模型。与传统的单一奖励模型相比,这种方法能够提供更细粒度的反馈信号,从而更有效地指导对话模型的训练。此外,使用监督微调(SFT)来训练奖励模型,可以提高奖励模型的准确性和可靠性。
关键设计:在奖励模型构建阶段,使用了监督微调(SFT)技术,并针对每个指标选择了合适的训练数据和损失函数。在对话模型训练阶段,使用了奖励模型提供的反馈信号,并探索了不同的强化学习算法和优化策略。具体的参数设置和网络结构等技术细节在论文中进行了详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用本文提出的方法训练的对话模型在多个对话印象指标上都取得了显著提升。自动评估和人工评估结果均显示,该方法能够提高对话的自然度和各项印象指标的评分。与基线模型相比,该方法在某些指标上的提升幅度超过10%。
🎯 应用场景
该研究成果可应用于各种人机对话场景,例如智能客服、虚拟助手、教育机器人等。通过提升对话系统的整体印象,可以增强用户与系统的互动体验,提高用户满意度和信任度。未来,该方法可以进一步扩展到更复杂的对话场景,例如多轮对话和情感对话。
📄 摘要(原文)
To improve user engagement during conversations with dialogue systems, we must improve individual dialogue responses and dialogue impressions such as consistency, personality, and empathy throughout the entire dialogue. While such dialogue systems have been developing rapidly with the help of large language models (LLMs), reinforcement learning from AI feedback (RLAIF) has attracted attention to align LLM-based dialogue models for such dialogue impressions. In RLAIF, a reward model based on another LLM is used to create a training signal for an LLM-based dialogue model using zero-shot/few-shot prompting techniques. However, evaluating an entire dialogue only by prompting LLMs is challenging. In this study, the supervised fine-tuning (SFT) of LLMs prepared reward models corresponding to 12 metrics related to the impression of the entire dialogue for evaluating dialogue responses. We tuned our dialogue models using the reward model signals as feedback to improve the impression of the system. The results of automatic and human evaluations showed that tuning the dialogue model using our reward model corresponding to dialogue impression improved the evaluation of individual metrics and the naturalness of the dialogue response.