Preference Curriculum: LLMs Should Always Be Pretrained on Their Preferred Data
作者: Xuemiao Zhang, Liangyu Xu, Feiyu Duan, Yongwei Zhou, Sirui Wang, Rongxiang Weng, Jingang Wang, Xunliang Cai
分类: cs.CL, cs.AI
发布日期: 2025-01-21 (更新: 2025-02-17)
备注: 18 pages, 13 figures
💡 一句话要点
提出基于困惑度差异的偏好课程学习框架,提升LLM预训练效果
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 预训练 课程学习 困惑度差异 数据偏好
📋 核心要点
- 传统LLM预训练采用静态数据分布,忽略了模型能力提升后数据偏好的动态变化。
- PDPC框架通过困惑度差异(PD)来量化数据难度,并构建偏好函数预测模型在不同阶段的数据偏好。
- 实验表明,PDPC显著提升了LLM在MMLU和CMMLU等基准测试上的性能,验证了其有效性。
📝 摘要(中文)
大型语言模型(LLM)通常在预训练过程中使用一致的数据分布。然而,随着模型能力的提高,其数据偏好会动态变化,需要在不同的训练阶段使用不同的数据进行预训练。为了实现这一点,我们提出了基于困惑度差异(PD)的偏好课程学习(PDPC)框架,该框架始终感知并使用LLM偏好的数据来训练和提升它们。首先,我们引入PD指标来量化样本对于弱模型和强模型的挑战程度差异。PD高的样本对于弱模型来说更难学习,更适合安排在预训练的后期阶段。其次,我们提出了偏好函数来近似和预测LLM在任何训练步骤的数据偏好,从而离线完成数据集的安排,并确保连续训练不中断。在1.3B和3B模型上的实验结果表明,PDPC显著优于基线。值得注意的是,在1T tokens上训练的3B模型在MMLU和CMMLU上的平均准确率提高了8.1%以上。
🔬 方法详解
问题定义:现有LLM预训练方法通常采用静态数据分布,即在整个预训练过程中使用相同的数据集和采样策略。然而,随着模型训练的进行,其能力不断提升,对数据的“偏好”也会发生变化。例如,在训练初期,模型可能更适合学习简单、基础的知识,而在训练后期,则需要更复杂、更具挑战性的数据。这种静态数据分布无法充分利用模型的学习能力,导致训练效率低下和最终性能受限。
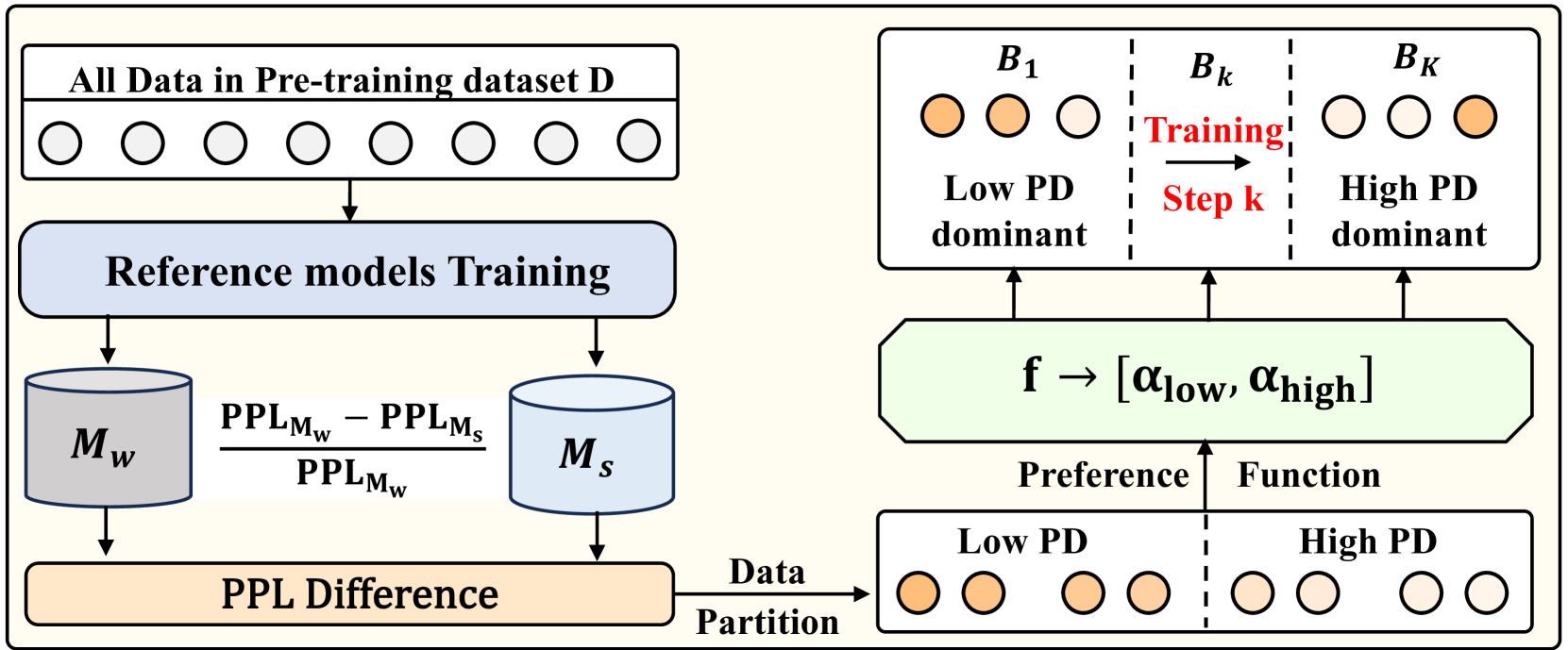
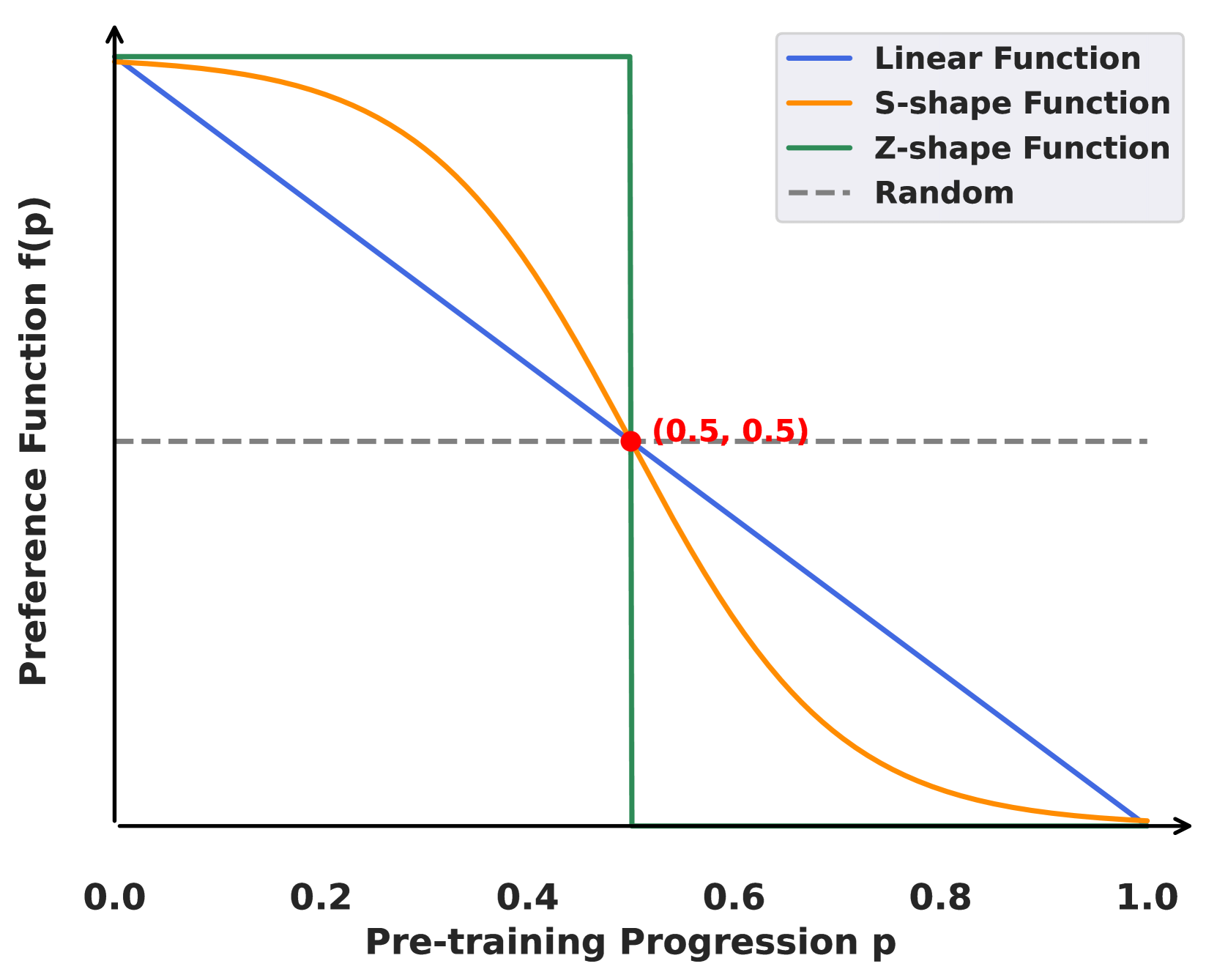
核心思路:PDPC的核心思路是根据LLM在不同训练阶段的“偏好”来动态调整训练数据。具体来说,它通过困惑度差异(Perplexity Difference, PD)来衡量数据样本对于不同能力模型的难度。PD高的样本表示对于弱模型来说更难学习,因此更适合在训练后期使用。通过构建一个偏好函数,PDPC可以预测LLM在任意训练步骤的数据偏好,从而实现数据的动态排序和选择。
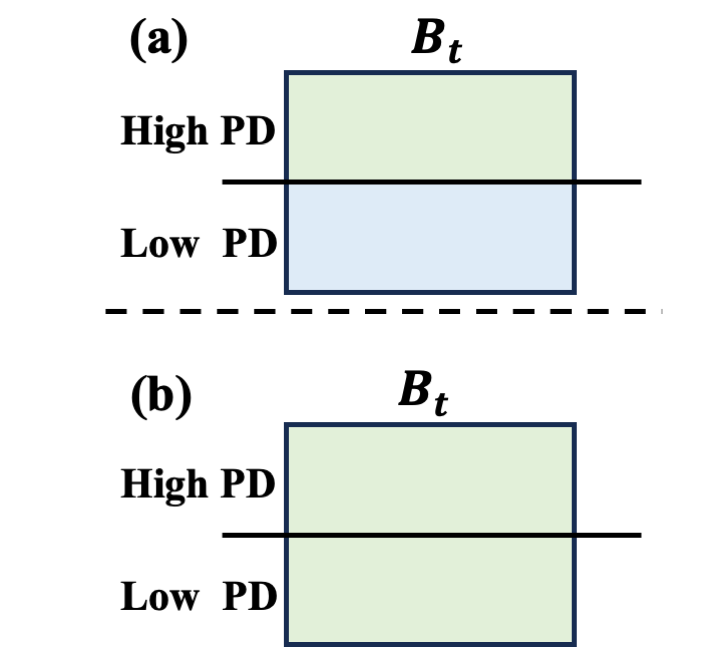
技术框架:PDPC框架主要包含两个阶段:数据排序阶段和预训练阶段。在数据排序阶段,首先使用弱模型和强模型分别计算数据集中每个样本的困惑度,然后计算PD值。根据PD值对数据集进行排序,得到一个难度递增的数据序列。同时,训练一个偏好函数,用于预测LLM在不同训练阶段的数据偏好。在预训练阶段,根据偏好函数动态选择数据进行训练。
关键创新:PDPC的关键创新在于提出了基于困惑度差异(PD)的数据难度量化方法和偏好函数。PD能够有效地衡量数据样本对于不同能力模型的难度,从而为动态调整训练数据提供依据。偏好函数能够预测LLM在不同训练阶段的数据偏好,从而实现数据的自适应选择。
关键设计:PD的计算公式为:PD(x) = Perplexity_weak(x) - Perplexity_strong(x),其中x表示一个数据样本,Perplexity_weak(x)和Perplexity_strong(x)分别表示弱模型和强模型在该样本上的困惑度。偏好函数可以使用神经网络进行建模,输入为训练步数,输出为数据样本的偏好得分。在预训练阶段,可以根据偏好得分对数据进行采样,或者直接选择偏好得分最高的数据进行训练。
🖼️ 关键图片
📊 实验亮点
在1.3B和3B模型上的实验结果表明,PDPC显著优于基线方法。具体来说,在1T tokens上训练的3B模型在MMLU和CMMLU上的平均准确率提高了8.1%以上。此外,实验还表明,PDPC能够有效地提高模型的训练效率,减少训练所需的计算资源。
🎯 应用场景
PDPC框架可应用于各种LLM的预训练,尤其适用于计算资源有限的场景。通过动态调整训练数据,可以提高训练效率,减少计算成本,并提升模型的最终性能。该方法还可以推广到其他机器学习任务中,例如图像分类、目标检测等,通过动态调整训练数据,提高模型的泛化能力。
📄 摘要(原文)
Large language models (LLMs) generally utilize a consistent data distribution throughout the pretraining process. However, as the model's capability improves, it is intuitive that its data preferences dynamically change, indicating the need for pretraining with different data at various training stages. To achieve it, we propose the Perplexity Difference (PD) based Preference Curriculum learning (PDPC) framework, which always perceives and uses the data preferred by LLMs to train and boost them. First, we introduce the PD metric to quantify the difference in how challenging a sample is for weak versus strong models. Samples with high PD are more challenging for weak models to learn and are more suitable to be arranged in the later stage of pretraining. Second, we propose the preference function to approximate and predict the data preference of the LLM at any training step, so as to complete the arrangement of the dataset offline and ensure continuous training without interruption. Experimental results on 1.3B and 3B models demonstrate that PDPC significantly surpasses baselines. Notably, the 3B model trained on 1T tokens achieves an increased average accuracy of over 8.1% across MMLU and CMMLU.