Generating Plausible Distractors for Multiple-Choice Questions via Student Choice Prediction
作者: Yooseop Lee, Suin Kim, Yohan Jo
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-01-21 (更新: 2025-05-31)
备注: This paper has been accepted for publication at ACL 2025
💡 一句话要点
提出基于学生选择预测的干扰项生成方法,提升多选题的区分度。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多选题生成 干扰项生成 学生选择预测 直接偏好优化 pairwise排序 教育评估 认知偏差
📋 核心要点
- 现有干扰项生成方法难以有效提升干扰项难度,降低了多选题的区分度和有效性。
- 通过训练pairwise排序器来推断学生误解,并利用DPO训练干扰项生成器,提升干扰项的合理性。
- 实验表明,该方法生成的干扰项更合理,多选题的区分度指数更高,效果优于现有基线方法。
📝 摘要(中文)
在教育领域设计多选题(MCQ)时,创建合理的干扰项对于识别学生的误解和知识差距,并准确评估他们的理解至关重要。然而,以往关于干扰项生成的研究没有充分关注提高干扰项的难度,导致多选题的有效性降低。本研究提出了一个训练模型的流程,以生成更可能被学生选择的干扰项。首先,我们训练一个pairwise排序器来推断学生的误解,并评估两个干扰项的相对合理性。使用该模型,我们创建了一个pairwise干扰项排序的数据集,然后通过直接偏好优化(DPO)训练一个干扰项生成器,以生成更合理的干扰项。在计算机科学科目(Python、DB、MLDL)上的实验表明,我们的pairwise排序器有效地识别了学生潜在的误解,并实现了与人类专家相当的排序准确率。此外,我们的干扰项生成器在生成合理的干扰项方面优于几个基线,并产生了具有更高项目区分度指数(DI)的问题。
🔬 方法详解
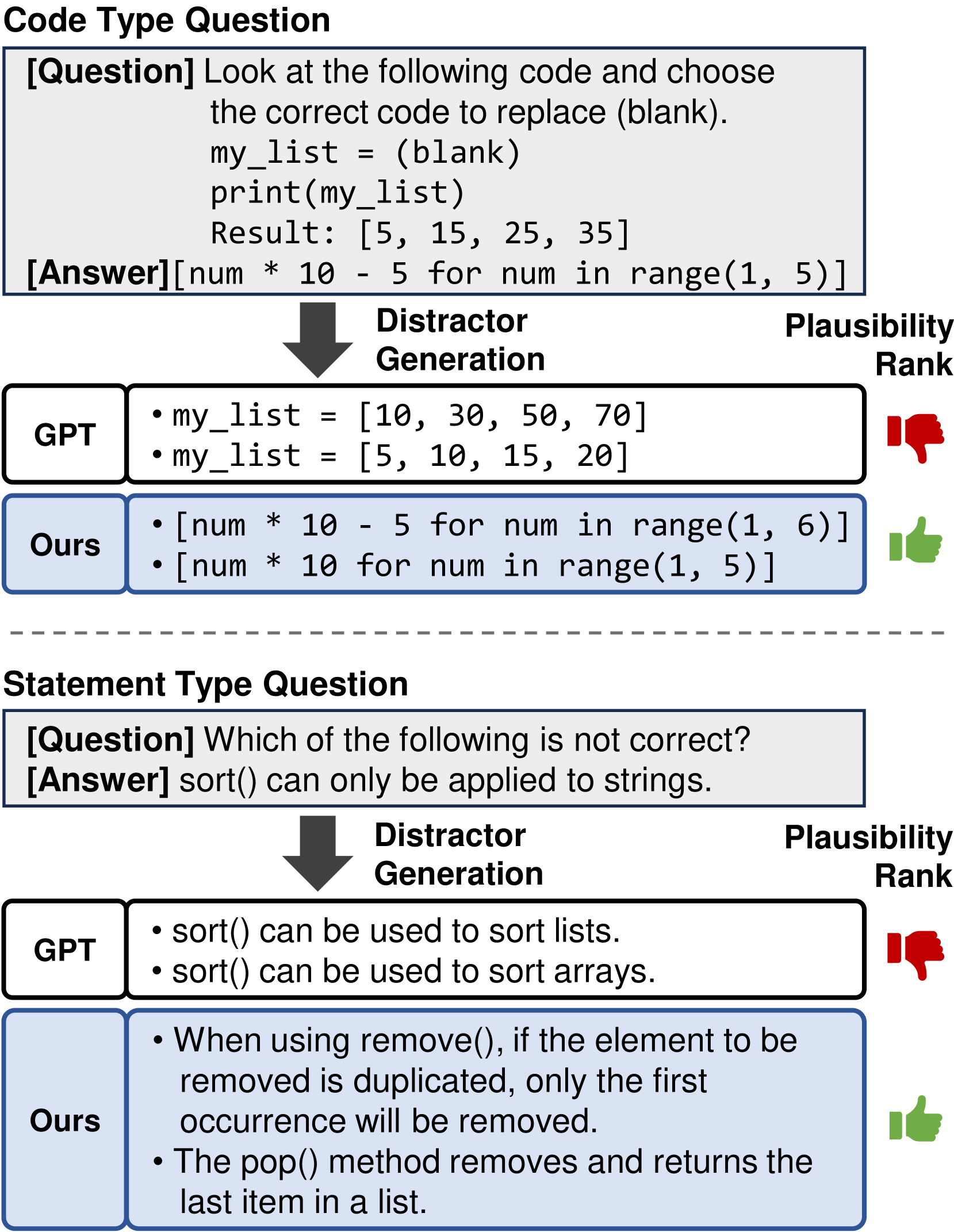
问题定义:论文旨在解决多选题中干扰项生成的问题。现有方法生成的干扰项不够逼真,难以有效区分掌握知识的学生和存在知识漏洞的学生,导致多选题的评估效果不佳。痛点在于如何生成更具迷惑性、更符合学生认知偏差的干扰项。
核心思路:论文的核心思路是利用学生的选择行为来指导干扰项的生成。通过训练一个排序模型来预测学生在两个干扰项中更可能选择哪一个,从而学习学生的潜在误解。然后,利用这个排序模型来优化干扰项生成器,使其生成的干扰项更符合学生的认知偏差,从而提高干扰项的迷惑性。
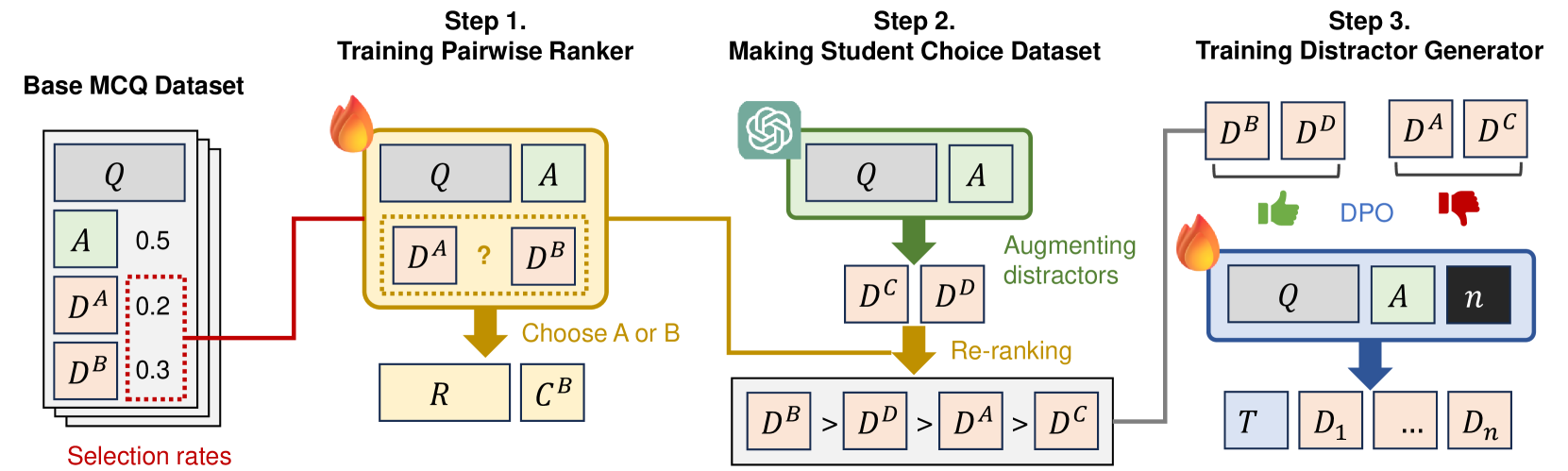
技术框架:整体框架包含两个主要阶段:1) Pairwise排序器训练:使用对比学习方法,训练一个排序模型,输入问题和两个干扰项,输出两个干扰项的相对合理性排序。2) 干扰项生成器训练:使用Direct Preference Optimization (DPO) 方法,利用pairwise排序器提供的排序信息,优化干扰项生成器,使其生成的干扰项更符合排序器的偏好。
关键创新:最重要的创新点在于利用pairwise排序器来模拟学生的认知偏差,并将排序器的输出作为优化目标来指导干扰项生成器的训练。与传统的生成模型直接生成干扰项不同,该方法更加关注干扰项的迷惑性,从而提高了多选题的区分度。
关键设计:Pairwise排序器可以使用各种神经网络结构,例如BERT等预训练语言模型。DPO是一种无需reference模型的强化学习方法,可以直接优化生成模型的策略,使其生成的样本更符合排序器的偏好。损失函数的设计需要考虑排序器的预测置信度,以更好地指导生成器的训练。
🖼️ 关键图片
📊 实验亮点
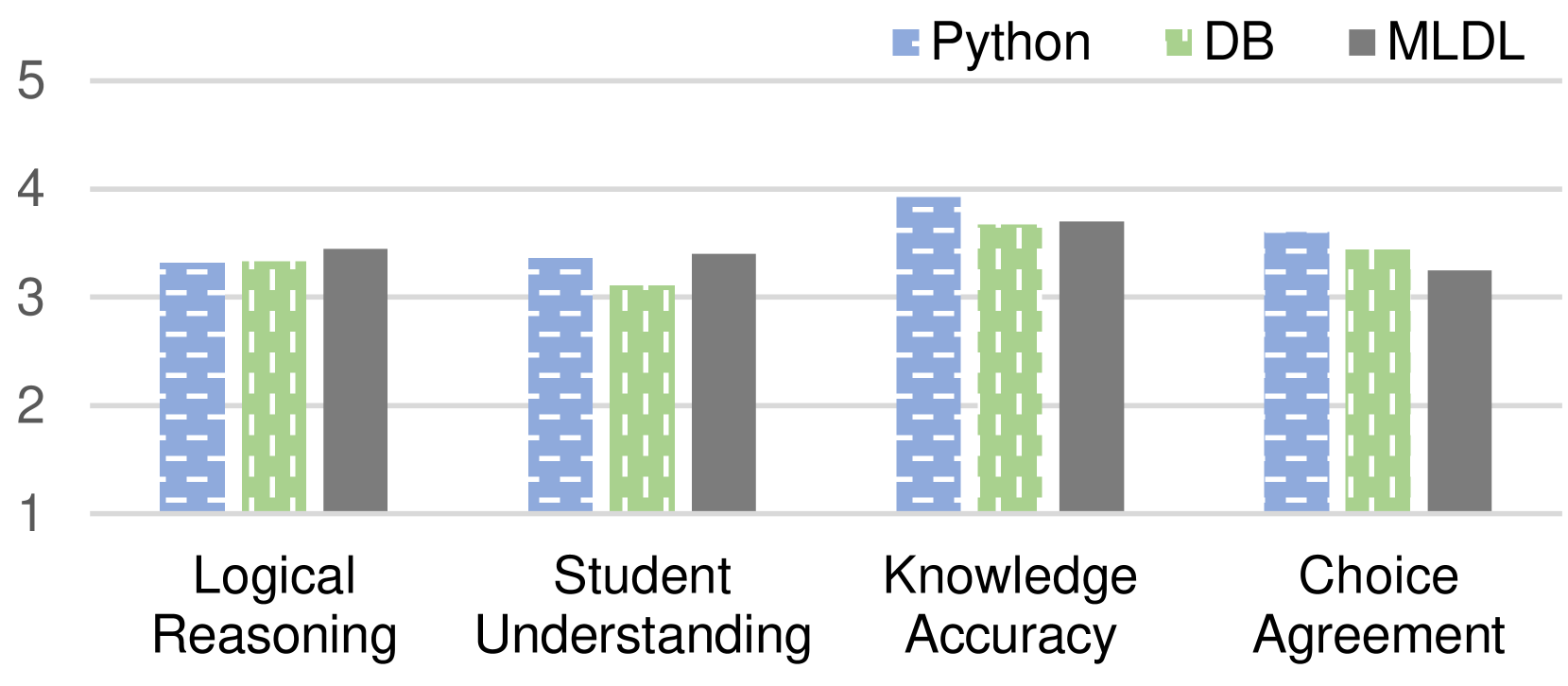
实验结果表明,该方法在计算机科学科目(Python、DB、MLDL)上表现出色。Pairwise排序器实现了与人类专家相当的排序准确率。干扰项生成器生成的干扰项更合理,多选题的区分度指数(DI)更高,表明该方法能够有效提高多选题的评估效果。
🎯 应用场景
该研究成果可应用于在线教育平台、智能题库系统和自动阅卷系统等领域,能够自动生成高质量的多选题,提高教学效率和评估的准确性。此外,该方法还可以扩展到其他需要生成迷惑性选项的场景,例如安全领域的对抗样本生成。
📄 摘要(原文)
In designing multiple-choice questions (MCQs) in education, creating plausible distractors is crucial for identifying students' misconceptions and gaps in knowledge and accurately assessing their understanding. However, prior studies on distractor generation have not paid sufficient attention to enhancing the difficulty of distractors, resulting in reduced effectiveness of MCQs. This study presents a pipeline for training a model to generate distractors that are more likely to be selected by students. First, we train a pairwise ranker to reason about students' misconceptions and assess the relative plausibility of two distractors. Using this model, we create a dataset of pairwise distractor ranks and then train a distractor generator via Direct Preference Optimization (DPO) to generate more plausible distractors. Experiments on computer science subjects (Python, DB, MLDL) demonstrate that our pairwise ranker effectively identifies students' potential misunderstandings and achieves ranking accuracy comparable to human experts. Furthermore, our distractor generator outperforms several baselines in generating plausible distractors and produces questions with a higher item discrimination index (DI).