Episodic Memories Generation and Evaluation Benchmark for Large Language Models
作者: Alexis Huet, Zied Ben Houidi, Dario Rossi
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-01-21
💡 一句话要点
提出LLM情景记忆生成与评估基准,揭示现有模型在复杂时空推理上的不足。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 情景记忆 大型语言模型 时空推理 知识表示 基准测试
📋 核心要点
- 现有LLM缺乏有效的情景记忆机制,导致在需要时空推理的任务中表现不佳,容易产生幻觉。
- 论文构建了一个全面的框架,用于建模和评估LLM的情景记忆能力,并合成了无污染的情景记忆基准。
- 实验结果表明,即使是最先进的LLM在处理复杂时空关系的情景记忆任务中仍然面临挑战。
📝 摘要(中文)
情景记忆是人类认知的基础,它使我们能够回忆起发生在特定时间和地点的事件,并支持连贯的叙事、规划和决策。尽管大型语言模型(LLM)具有卓越的能力,但它们缺乏强大的情景记忆机制。本文认为,将情景记忆能力整合到LLM中对于推动人工智能向类人认知发展至关重要,从而提高其一致推理和基于真实情景事件输出的能力,避免捏造事实。为了解决这一挑战,本文提出了一个全面的框架来建模和评估LLM的情景记忆能力。借鉴认知科学,开发了一种结构化的方法来表示情景事件,包括时间、空间背景、相关实体和详细描述。合成了一个独特的情景记忆基准,避免了数据污染,并发布了开源代码和数据集,以评估LLM在各种回忆和情景推理任务中的表现。对包括GPT-4、Claude变体、Llama 3.1和o1-mini在内的最先进模型的评估表明,即使是最先进的LLM在情景记忆任务中也表现不佳,尤其是在处理多个相关事件或复杂的时空关系时,即使在10k-100k tokens的短上下文中也是如此。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)缺乏有效情景记忆的问题。现有LLM在处理需要回忆特定时间和地点发生的事件,以及进行时空推理的任务时,容易产生幻觉和不一致的输出。现有的评估方法缺乏对LLM情景记忆能力的针对性测试。
核心思路:论文的核心思路是借鉴认知科学,构建一个结构化的情景事件表示方法,并基于此生成一个无污染的情景记忆基准。通过评估LLM在不同类型的情景记忆任务中的表现,来衡量其情景记忆能力。
技术框架:该框架包含以下几个主要部分: 1. 情景事件表示:使用结构化的方法表示情景事件,包括时间、空间背景、相关实体和详细描述。 2. 情景记忆基准生成:合成一个独特的情景记忆基准,确保数据无污染,并涵盖各种回忆和情景推理任务。 3. 评估任务设计:设计多种评估任务,例如简单回忆、时序推理、空间推理等,以全面评估LLM的情景记忆能力。 4. 模型评估:使用基准数据集评估各种LLM(如GPT-4、Claude、Llama 3.1等)在不同任务上的表现。
关键创新:论文的关键创新在于: 1. 提出了一个结构化的情景事件表示方法,能够有效地捕捉事件的时空信息和实体关系。 2. 合成了一个无污染的情景记忆基准,避免了LLM在训练过程中可能接触到相关数据的问题。 3. 设计了一系列评估任务,能够全面评估LLM在不同类型的情景记忆任务中的表现。
关键设计:论文的关键设计包括: 1. 情景事件表示:使用JSON格式表示情景事件,包含时间戳、地点坐标、参与实体列表、事件描述等字段。 2. 基准数据集生成:使用规则和模板生成情景事件,并进行人工校验,确保数据质量。 3. 评估指标:使用准确率、召回率、F1值等指标评估LLM在不同任务上的表现。
🖼️ 关键图片

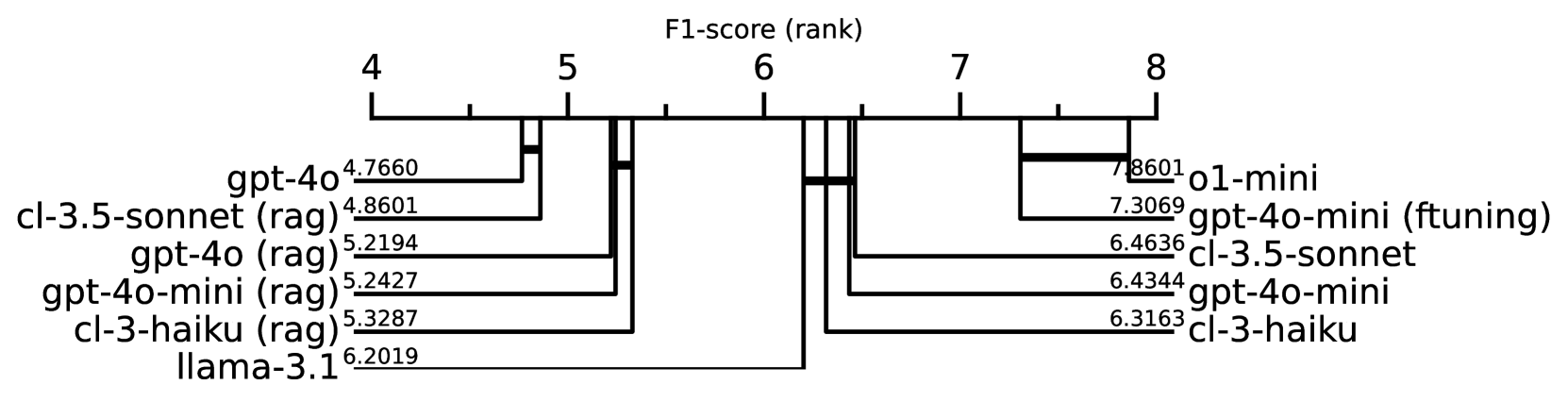
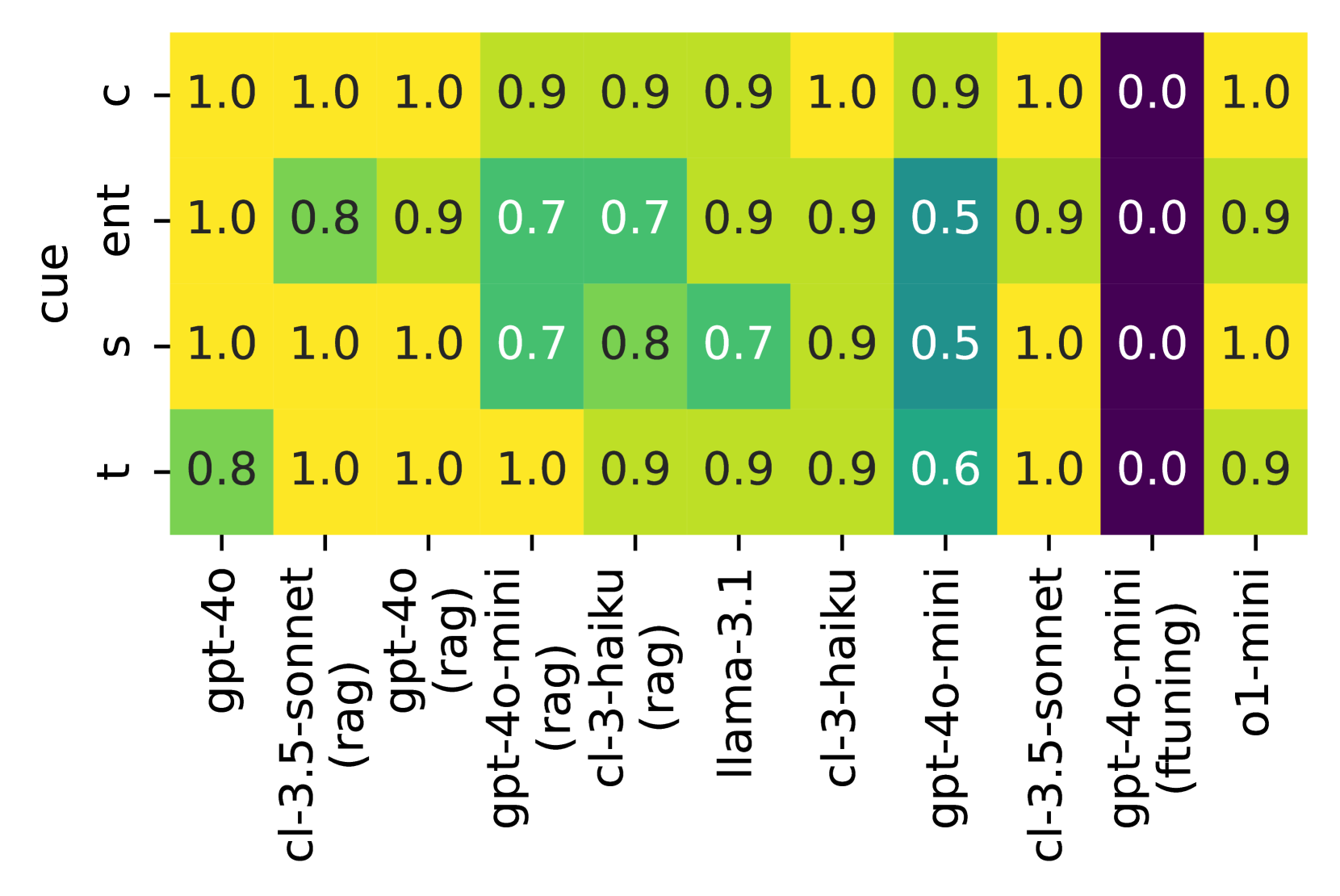
📊 实验亮点
实验结果表明,即使是GPT-4等最先进的LLM在情景记忆任务中也表现不佳,尤其是在处理多个相关事件或复杂的时空关系时。例如,在时序推理任务中,LLM的准确率仅为60%左右,远低于人类水平。这表明现有LLM在情景记忆方面仍有很大的提升空间。
🎯 应用场景
该研究成果可应用于开发更可靠、更可信的LLM,尤其是在需要基于真实事件进行推理和决策的场景中,例如智能助手、医疗诊断、金融分析等。通过提高LLM的情景记忆能力,可以减少幻觉,提高输出的一致性和可解释性,从而增强用户对LLM的信任。
📄 摘要(原文)
Episodic memory -- the ability to recall specific events grounded in time and space -- is a cornerstone of human cognition, enabling not only coherent storytelling, but also planning and decision-making. Despite their remarkable capabilities, Large Language Models (LLMs) lack a robust mechanism for episodic memory: we argue that integrating episodic memory capabilities into LLM is essential for advancing AI towards human-like cognition, increasing their potential to reason consistently and ground their output in real-world episodic events, hence avoiding confabulations. To address this challenge, we introduce a comprehensive framework to model and evaluate LLM episodic memory capabilities. Drawing inspiration from cognitive science, we develop a structured approach to represent episodic events, encapsulating temporal and spatial contexts, involved entities, and detailed descriptions. We synthesize a unique episodic memory benchmark, free from contamination, and release open source code and datasets to assess LLM performance across various recall and episodic reasoning tasks. Our evaluation of state-of-the-art models, including GPT-4 and Claude variants, Llama 3.1, and o1-mini, reveals that even the most advanced LLMs struggle with episodic memory tasks, particularly when dealing with multiple related events or complex spatio-temporal relationships -- even in contexts as short as 10k-100k tokens.