Revealing emergent human-like conceptual representations from language prediction
作者: Ningyu Xu, Qi Zhang, Chao Du, Qiang Luo, Xipeng Qiu, Xuanjing Huang, Menghan Zhang
分类: cs.CL, cs.AI
发布日期: 2025-01-21 (更新: 2025-11-08)
备注: 66 pages. Accepted manuscript. Final version published in Proceedings of the National Academy of Sciences (PNAS): https://www.pnas.org/doi/10.1073/pnas.2512514122
期刊: Proceedings of the National Academy of Sciences, U.S.A., 122 (44) e2512514122 (2025)
💡 一句话要点
揭示:大型语言模型通过语言预测涌现类人概念表征
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 概念表征 上下文学习 语言预测 类人智能
📋 核心要点
- 现有大型语言模型缺乏与现实世界的直接交互,其概念理解能力受到质疑。
- 该研究通过上下文概念推理任务,分析LLM在语言预测中形成的表征,揭示其概念学习机制。
- 实验表明,LLM能涌现类人概念表征,与人类行为判断和脑神经活动模式高度一致。
📝 摘要(中文)
人们通过丰富的物理和社会经验获得概念,并用它们来理解和探索世界。相比之下,大型语言模型(LLM)仅通过文本上的下一个token预测进行训练,却表现出惊人地类人行为。这些模型是否发展出了类似于人类的概念?如果是,这些概念是如何表示、组织以及与行为相关的?本文通过研究LLM在上下文概念推理任务中形成的表征来解决这些问题。研究发现,LLM可以灵活地从语言描述中推导出概念,并将其与关于其他概念的上下文线索联系起来。导出的表征收敛于一个共享的、与上下文无关的结构,并且与该结构的对齐能够可靠地预测模型在各种理解和推理任务中的表现。此外,收敛的表征有效地捕捉了人类的行为判断,并与人脑中的神经活动模式紧密对齐,为生物合理性提供了证据。总之,这些发现表明,结构化的、类人概念表征可以纯粹从语言预测中涌现,而无需现实世界的 grounding,突出了概念结构在理解智能行为中的作用。更广泛地说,这项工作表明,LLM为理解人类概念的本质提供了一个有形的窗口,并为推进人工智能与人类智能的对齐奠定了基础。
🔬 方法详解
问题定义:论文旨在探究大型语言模型(LLM)是否以及如何发展出类似于人类的概念表征。现有方法主要关注LLM在特定任务上的表现,而忽略了对其内部概念表征的深入理解。现有研究缺乏对LLM概念表征的结构、组织方式以及与人类概念表征的关联性的系统性分析。
核心思路:论文的核心思路是通过设计一个上下文概念推理任务,观察LLM在学习和使用概念时的内部表征变化。通过分析这些表征,揭示LLM是否能够从语言描述中灵活地推导出概念,并形成与人类相似的概念结构。这种方法强调从表征层面理解LLM的智能行为,而非仅仅关注其外部表现。
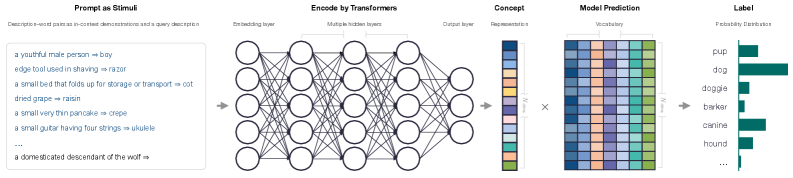
技术框架:论文的技术框架主要包括以下几个阶段:1) 设计上下文概念推理任务,该任务要求LLM根据上下文线索推断新概念的含义。2) 使用LLM完成该任务,并提取其内部表征。3) 分析LLM的表征,包括其结构、组织方式以及与其他概念的关系。4) 将LLM的表征与人类的行为判断和脑神经活动模式进行比较,评估其生物合理性。
关键创新:论文最重要的技术创新点在于揭示了LLM可以通过纯粹的语言预测涌现出结构化的、类人概念表征。这表明,即使没有现实世界的 grounding,LLM也能够学习到与人类相似的概念结构。这一发现挑战了传统的人工智能观点,即概念学习必须依赖于感知和交互。
关键设计:论文的关键设计包括:1) 精心设计的上下文概念推理任务,该任务能够有效地激发LLM的概念学习能力。2) 使用表征相似性分析方法,量化LLM表征的结构和组织方式。3) 将LLM表征与人类行为判断和脑神经活动模式进行对齐,评估其生物合理性。具体参数设置和网络结构信息未知。
🖼️ 关键图片

📊 实验亮点
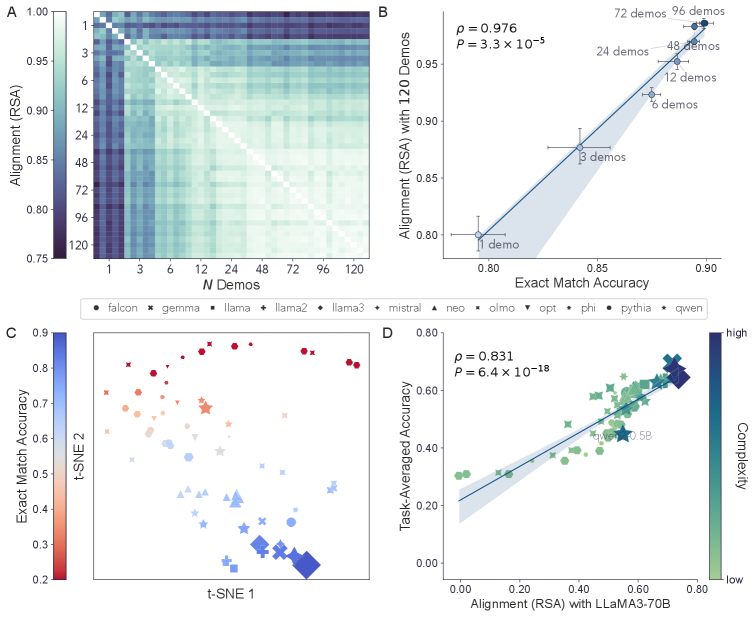
研究发现,LLM导出的概念表征收敛于一个共享的、与上下文无关的结构,并且与该结构的对齐能够可靠地预测模型在各种理解和推理任务中的表现。此外,收敛的表征有效地捕捉了人类的行为判断,并与人脑中的神经活动模式紧密对齐,为生物合理性提供了证据。具体性能数据未知。
🎯 应用场景
该研究成果可应用于提升LLM的通用性和泛化能力,使其在各种理解和推理任务中表现更佳。通过理解LLM的概念表征,可以更好地控制和引导其行为,减少潜在的偏见和错误。此外,该研究为开发更具生物合理性的人工智能系统提供了新的思路。
📄 摘要(原文)
People acquire concepts through rich physical and social experiences and use them to understand and navigate the world. In contrast, large language models (LLMs), trained solely through next-token prediction on text, exhibit strikingly human-like behaviors. Are these models developing concepts akin to those of humans? If so, how are such concepts represented, organized, and related to behavior? Here, we address these questions by investigating the representations formed by LLMs during an in-context concept inference task. We found that LLMs can flexibly derive concepts from linguistic descriptions in relation to contextual cues about other concepts. The derived representations converge toward a shared, context-independent structure, and alignment with this structure reliably predicts model performance across various understanding and reasoning tasks. Moreover, the convergent representations effectively capture human behavioral judgments and closely align with neural activity patterns in the human brain, providing evidence for biological plausibility. Together, these findings establish that structured, human-like conceptual representations can emerge purely from language prediction without real-world grounding, highlighting the role of conceptual structure in understanding intelligent behavior. More broadly, our work suggests that LLMs offer a tangible window into the nature of human concepts and lays the groundwork for advancing alignment between artificial and human intelligence.