Automatic Labelling with Open-source LLMs using Dynamic Label Schema Integration
作者: Thomas Walshe, Sae Young Moon, Chunyang Xiao, Yawwani Gunawardana, Fran Silavong
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-01-21
备注: 11 pages, 1 figure
💡 一句话要点
提出基于动态标签模式集成的检索增强分类(RAC),提升开源LLM自动标注性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动标注 大型语言模型 开源LLM 检索增强分类 动态标签模式 高基数任务 数据质量 标签覆盖率
📋 核心要点
- 现有自动标注方法在高基数任务中,直接使用标签描述进行分类,导致性能不佳。
- 提出检索增强分类(RAC)方法,动态集成标签描述,每次只对一个标签进行推理,提升标注性能。
- 实验表明,RAC方法在标签质量和覆盖率之间取得了良好的平衡,并成功应用于内部数据集的自动标注。
📝 摘要(中文)
在现实世界的机器学习项目中,获取高质量和足量的标注数据仍然是一项昂贵的任务。最近,大型语言模型(LLMs),特别是GPT-4,在数据标注方面表现出巨大的潜力,并具有很高的准确性。然而,隐私和成本问题阻碍了GPT-4的广泛使用。本文探讨了如何有效地利用开源模型进行自动标注。我们发现集成标签模式是一种很有前途的技术,但直接使用标签描述进行分类会导致高基数任务的性能不佳。为了解决这个问题,我们提出了检索增强分类(RAC),其中LLM使用相应的标签模式一次对一个标签执行推理;我们从最相关的标签开始,迭代直到LLM选择一个标签。我们表明,我们的方法动态地集成标签描述,从而提高了标注任务的性能。我们进一步表明,通过只关注最有希望的标签,RAC可以在标签质量和覆盖率之间进行权衡——我们利用这一特性来自动标注我们的内部数据集。
🔬 方法详解
问题定义:论文旨在解决使用开源LLM进行自动数据标注时,在高基数(high cardinality)任务中性能不佳的问题。现有方法直接将标签描述用于分类,忽略了标签之间的关联性,导致分类准确率下降,尤其是在标签数量较多时。此外,隐私和成本限制了GPT-4等闭源模型的广泛应用,因此需要探索更有效的开源LLM标注方法。
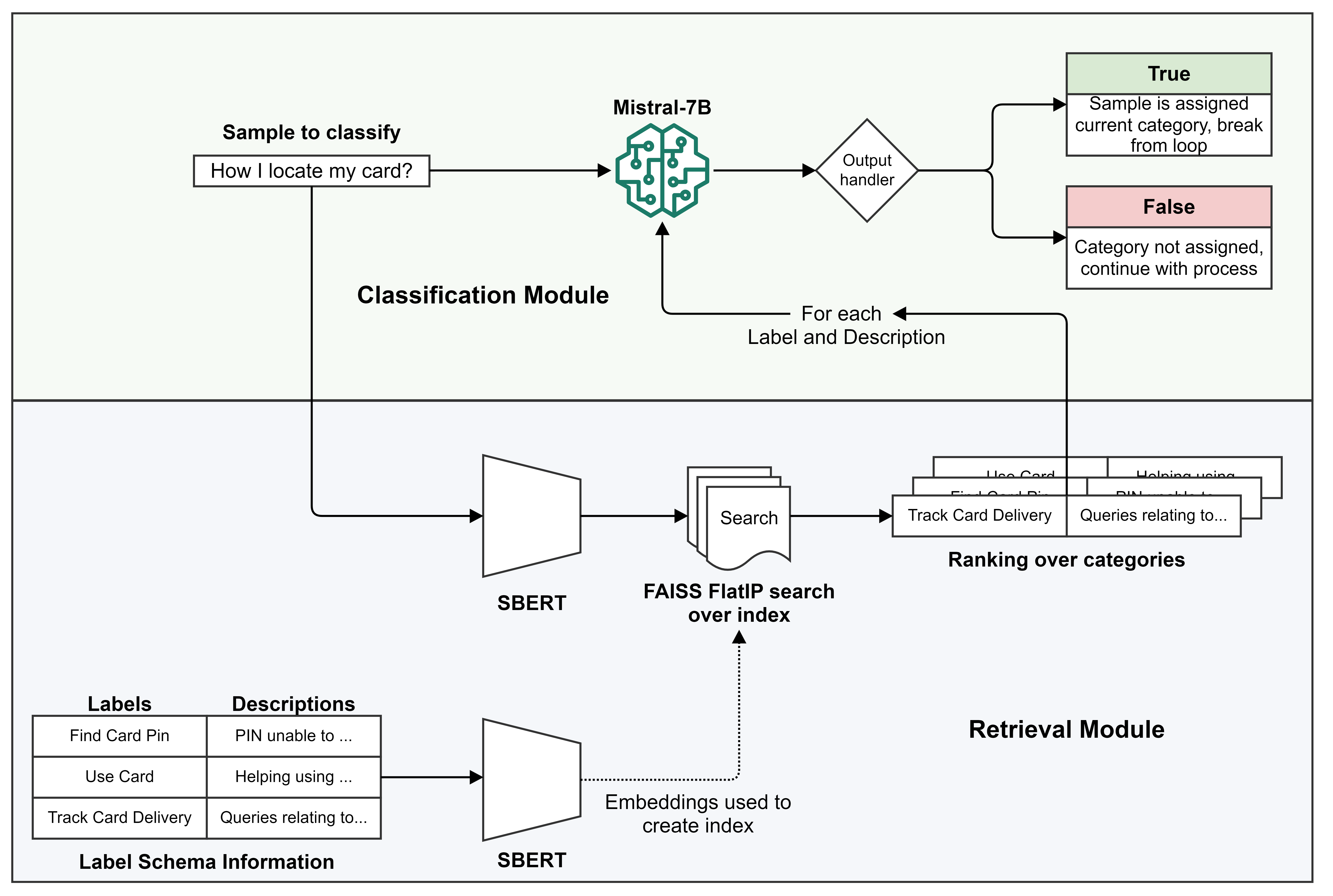
核心思路:论文的核心思路是利用检索增强分类(RAC)动态地集成标签描述,并逐个标签进行推理。RAC方法不再一次性预测所有标签,而是从最相关的标签开始,迭代地进行推理,直到LLM选择一个合适的标签。这种方法能够更好地利用标签之间的关联性,并减少LLM的搜索空间,从而提高标注的准确性和效率。
技术框架:RAC方法主要包含以下几个阶段: 1. 标签检索:根据输入数据,检索与该数据最相关的标签。 2. 标签推理:使用LLM和检索到的标签描述,对该标签进行推理,判断该标签是否适用于输入数据。 3. 标签选择:如果LLM认为该标签适用,则选择该标签;否则,继续检索下一个最相关的标签,并重复标签推理过程。 4. 迭代优化:通过调整检索策略和推理阈值,优化标签质量和覆盖率之间的平衡。
关键创新:RAC方法的关键创新在于动态标签模式集成和逐个标签推理。与现有方法直接使用标签描述进行分类不同,RAC方法能够根据输入数据动态地选择最相关的标签描述,并逐个标签进行推理,从而更好地利用标签之间的关联性,并减少LLM的搜索空间。这种方法能够显著提高高基数任务的标注准确率。
关键设计:RAC方法的关键设计包括: 1. 标签检索策略:选择合适的检索算法,例如基于向量相似度的检索,以快速找到与输入数据最相关的标签。 2. 推理阈值:设置合适的推理阈值,以控制标签选择的严格程度,从而平衡标签质量和覆盖率。 3. 迭代停止条件:定义迭代停止条件,例如达到最大迭代次数或找到合适的标签,以避免无限循环。
🖼️ 关键图片
📊 实验亮点
论文提出的RAC方法在自动标注任务中取得了显著的性能提升。通过动态集成标签描述和逐个标签推理,RAC方法能够在高基数任务中获得更高的标注准确率和覆盖率。实验结果表明,RAC方法能够有效地平衡标签质量和覆盖率,并成功应用于内部数据集的自动标注。
🎯 应用场景
该研究成果可应用于各种需要大规模数据标注的领域,例如图像识别、自然语言处理、语音识别等。通过利用开源LLM和RAC方法,可以显著降低数据标注的成本和时间,加速机器学习模型的开发和部署。此外,该方法还可以应用于内部数据集的自动标注,提高数据质量和利用率。
📄 摘要(原文)
Acquiring labelled training data remains a costly task in real world machine learning projects to meet quantity and quality requirements. Recently Large Language Models (LLMs), notably GPT-4, have shown great promises in labelling data with high accuracy. However, privacy and cost concerns prevent the ubiquitous use of GPT-4. In this work, we explore effectively leveraging open-source models for automatic labelling. We identify integrating label schema as a promising technology but found that naively using the label description for classification leads to poor performance on high cardinality tasks. To address this, we propose Retrieval Augmented Classification (RAC) for which LLM performs inferences for one label at a time using corresponding label schema; we start with the most related label and iterates until a label is chosen by the LLM. We show that our method, which dynamically integrates label description, leads to performance improvements in labelling tasks. We further show that by focusing only on the most promising labels, RAC can trade off between label quality and coverage - a property we leverage to automatically label our internal datasets.