Improving Influence-based Instruction Tuning Data Selection for Balanced Learning of Diverse Capabilities
作者: Qirun Dai, Dylan Zhang, Jiaqi W. Ma, Hao Peng
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-01-21
💡 一句话要点
提出BIDS算法,通过平衡数据选择提升指令微调后LLM的多样能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 指令微调 数据选择 影响力函数 大型语言模型 平衡学习
📋 核心要点
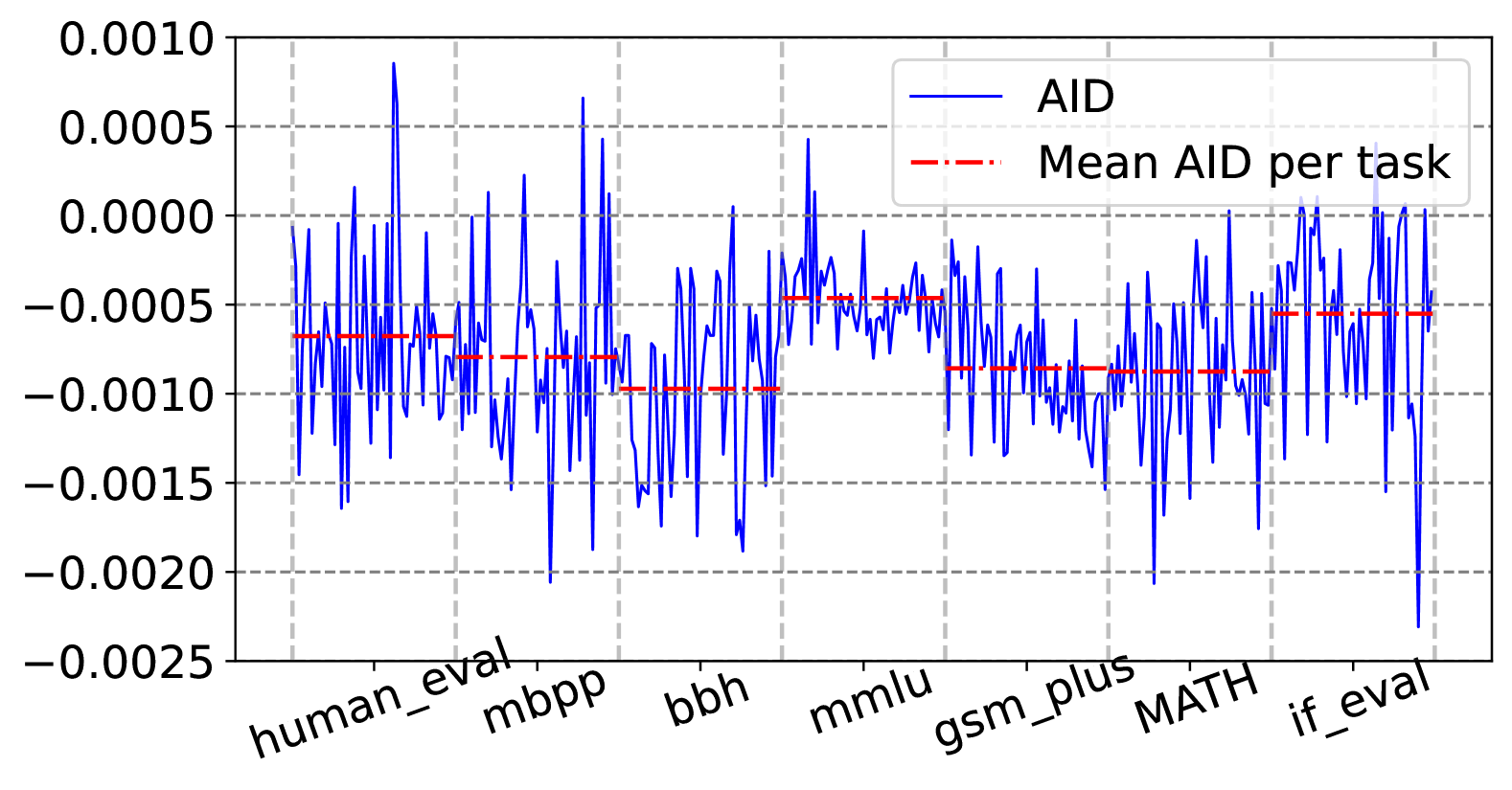
- 现有基于影响的数据选择方法在指令微调中存在偏差,导致模型在不同任务上的表现不均衡。
- BIDS算法通过归一化影响分数并迭代选择对代表性不足任务影响最大的样本,实现数据选择的平衡。
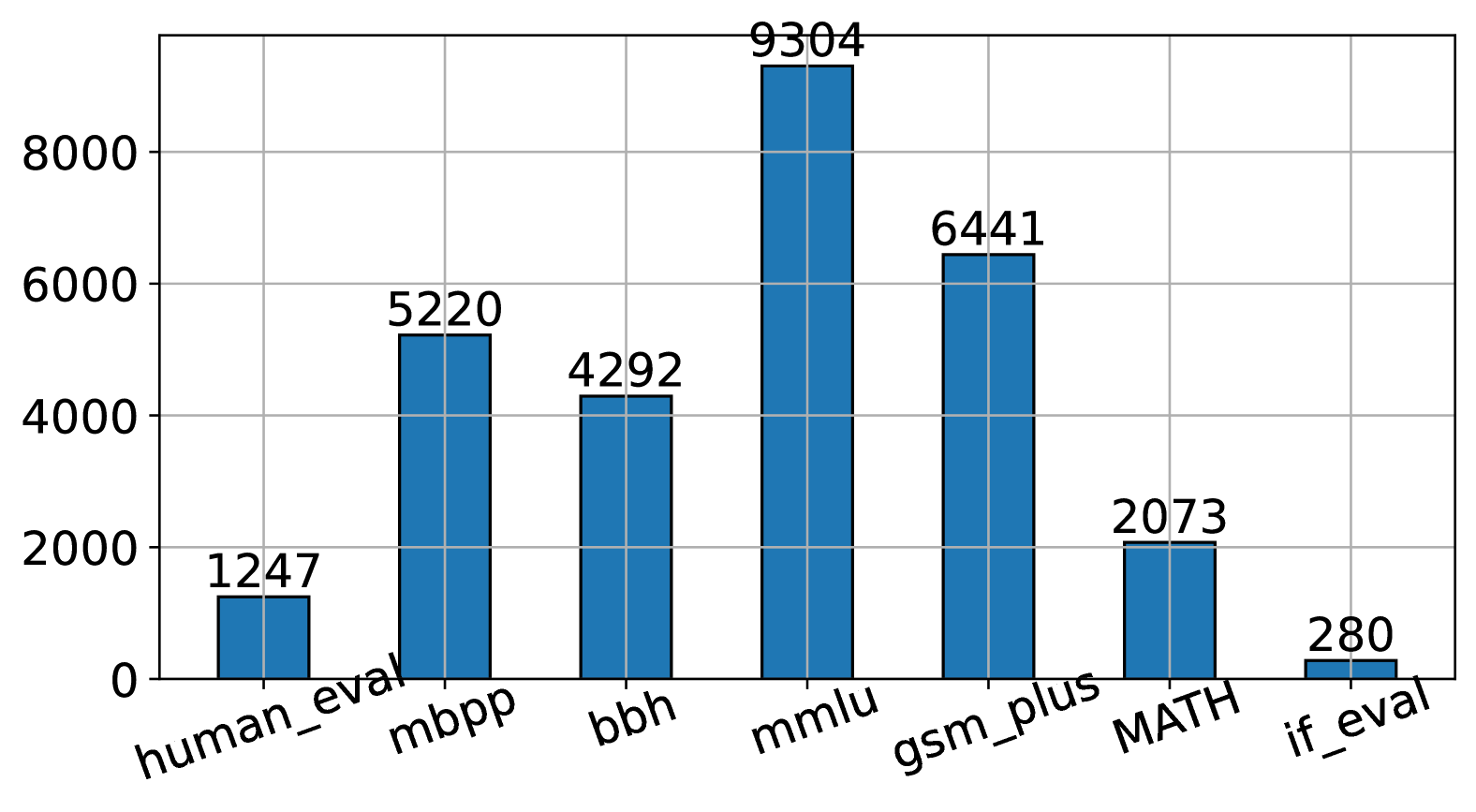
- 实验表明,BIDS在多种基准测试中优于现有方法,甚至在15%的数据子集上训练就能超越全数据集训练。
📝 摘要(中文)
指令微调大型语言模型(LLM)的关键在于选择合适的训练数据,以期(1)激发强大的能力,(2)在各种任务中实现均衡的性能。基于影响的方法在实现(1)方面显示出潜力,但常常难以实现(2)。我们的系统性研究表明,这种不足可归因于固有的偏差,即某些任务本质上比其他任务具有更大的影响力。因此,数据选择常常偏向于这些任务,不仅损害了模型在其他任务上的性能,而且适得其反地损害了模型在这些高影响力任务上的性能。作为补救措施,我们提出了BIDS,一种平衡且有影响的数据选择算法。BIDS首先对训练数据的影响力得分进行归一化,然后通过选择对代表性不足的任务影响最大的训练样本来迭代地平衡数据选择。在Llama-3和Mistral-v0.3上,对涵盖五种不同能力的七个基准的实验表明,BIDS始终优于最先进的基于影响的算法和其他非基于影响的选择框架。令人惊讶的是,在BIDS选择的15%子集上进行训练甚至可以胜过在完整数据集上进行训练,并获得更加平衡的性能。我们的分析进一步强调了实例级归一化和所选数据的迭代优化对于平衡学习各种能力的重要性。
🔬 方法详解
问题定义:论文旨在解决指令微调大型语言模型时,由于训练数据选择不平衡导致模型在不同任务上表现差异大的问题。现有基于影响的数据选择方法倾向于选择对某些任务影响大的数据,忽略了其他任务,导致模型整体性能下降,甚至在高影响力任务上的表现也会受到影响。
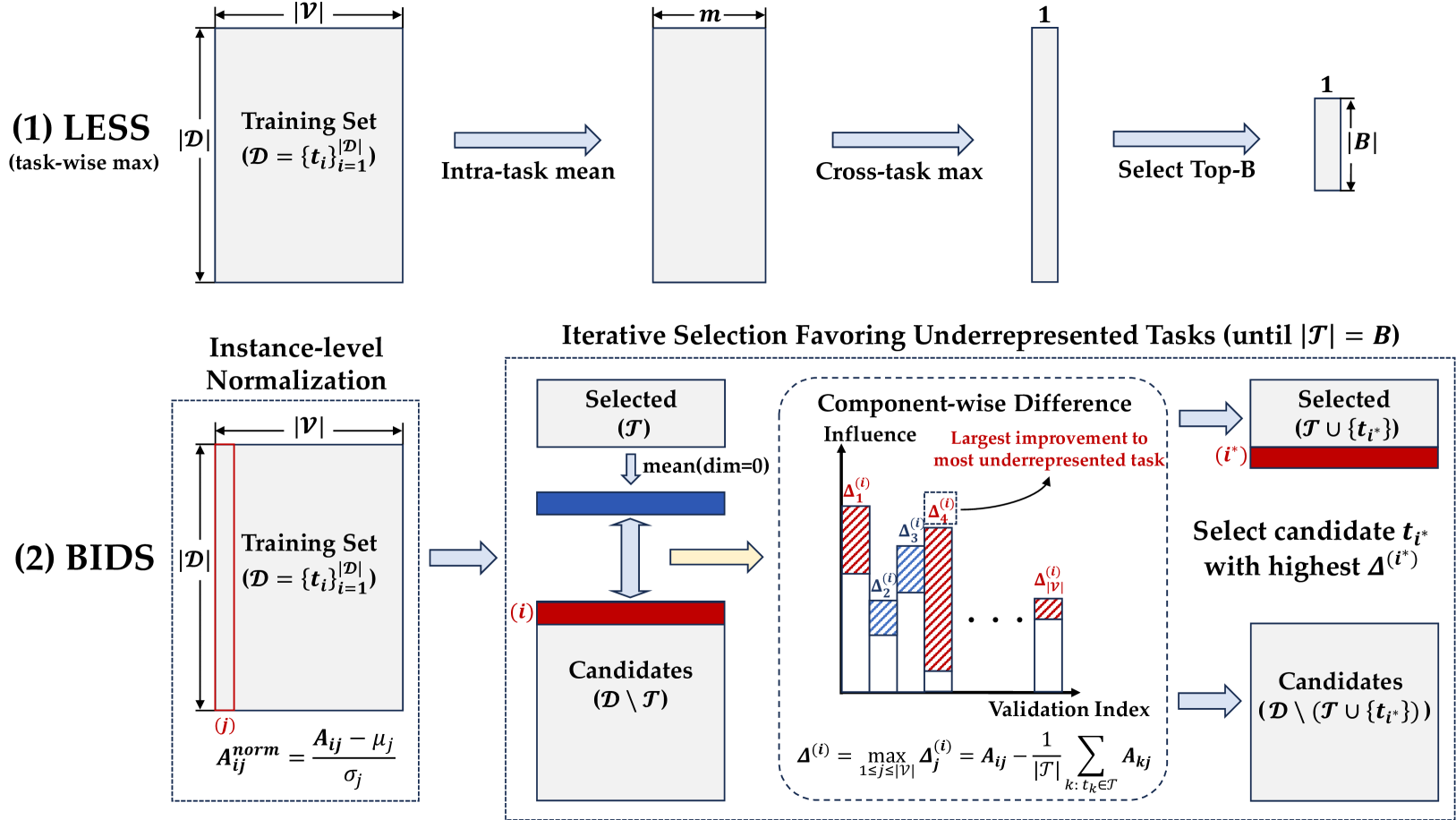
核心思路:论文的核心思路是通过平衡数据选择来提升模型在不同任务上的表现。具体来说,首先对每个训练样本的影响力进行归一化,然后迭代地选择对代表性不足的任务影响最大的样本。这样可以避免数据选择偏向于某些任务,从而实现更均衡的学习。
技术框架:BIDS算法主要包含两个阶段:1) 影响力归一化:对每个训练样本的影响力得分进行归一化,消除不同任务之间固有影响力的差异。2) 迭代数据选择:迭代地选择对当前代表性不足的任务影响最大的训练样本,直到达到预定的数据选择比例。
关键创新:BIDS算法的关键创新在于同时考虑了数据的影响力和任务的代表性。通过影响力归一化,消除了任务固有影响力的偏差;通过迭代选择,保证了每个任务都有足够多的代表性数据。这种平衡的数据选择策略能够提升模型在不同任务上的泛化能力。
关键设计:BIDS算法的关键设计包括:1) 影响力归一化的方法:论文中具体采用何种归一化方法(例如,min-max归一化、Z-score归一化等)未知。2) 任务代表性的度量:论文中如何定义和度量任务的代表性(例如,基于模型在任务上的表现、已选择的数据量等)未知。3) 迭代停止条件:迭代数据选择过程何时停止(例如,达到预定的数据选择比例、模型性能达到饱和等)未知。
🖼️ 关键图片
📊 实验亮点
实验结果表明,BIDS算法在Llama-3和Mistral-v0.3上,对涵盖五种不同能力的七个基准测试中,始终优于最先进的基于影响的算法和其他非基于影响的选择框架。更令人惊讶的是,使用BIDS选择的15%数据子集进行训练,其性能甚至超过了使用完整数据集进行训练,同时实现了更平衡的性能。
🎯 应用场景
该研究成果可应用于各种需要指令微调大型语言模型的场景,例如对话系统、文本生成、代码生成等。通过BIDS算法,可以更有效地利用有限的训练数据,提升模型在不同任务上的表现,降低模型部署和维护的成本。该方法还有助于提升模型的公平性和鲁棒性,使其在更广泛的应用场景中发挥作用。
📄 摘要(原文)
Selecting appropriate training data is crucial for effective instruction fine-tuning of large language models (LLMs), which aims to (1) elicit strong capabilities, and (2) achieve balanced performance across a diverse range of tasks. Influence-based methods show promise in achieving (1) by estimating the contribution of each training example to the model's predictions, but often struggle with (2). Our systematic investigation reveals that this underperformance can be attributed to an inherent bias where certain tasks intrinsically have greater influence than others. As a result, data selection is often biased towards these tasks, not only hurting the model's performance on others but also, counterintuitively, harms performance on these high-influence tasks themselves. As a remedy, we propose BIDS, a Balanced and Influential Data Selection algorithm. BIDS first normalizes influence scores of the training data, and then iteratively balances data selection by choosing the training example with the highest influence on the most underrepresented task. Experiments with both Llama-3 and Mistral-v0.3 on seven benchmarks spanning five diverse capabilities show that BIDS consistently outperforms both state-of-the-art influence-based algorithms and other non-influence-based selection frameworks. Surprisingly, training on a 15% subset selected by BIDS can even outperform full-dataset training with a much more balanced performance. Our analysis further highlights the importance of both instance-level normalization and iterative optimization of selected data for balanced learning of diverse capabilities.