A Hybrid Attention Framework for Fake News Detection with Large Language Models
作者: Xiaochuan Xu, Peiyang Yu, Zeqiu Xu, Jiani Wang
分类: cs.CL
发布日期: 2025-01-21
💡 一句话要点
提出一种基于混合注意力机制和大型语言模型的假新闻检测框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 假新闻检测 大型语言模型 混合注意力机制 文本分类 可解释性 自然语言处理 深度学习
📋 核心要点
- 现有假新闻检测方法难以有效融合文本的统计特征和深层语义信息,导致检测精度受限。
- 该论文提出一种混合注意力框架,利用大型语言模型的上下文理解能力,并关注关键特征组合。
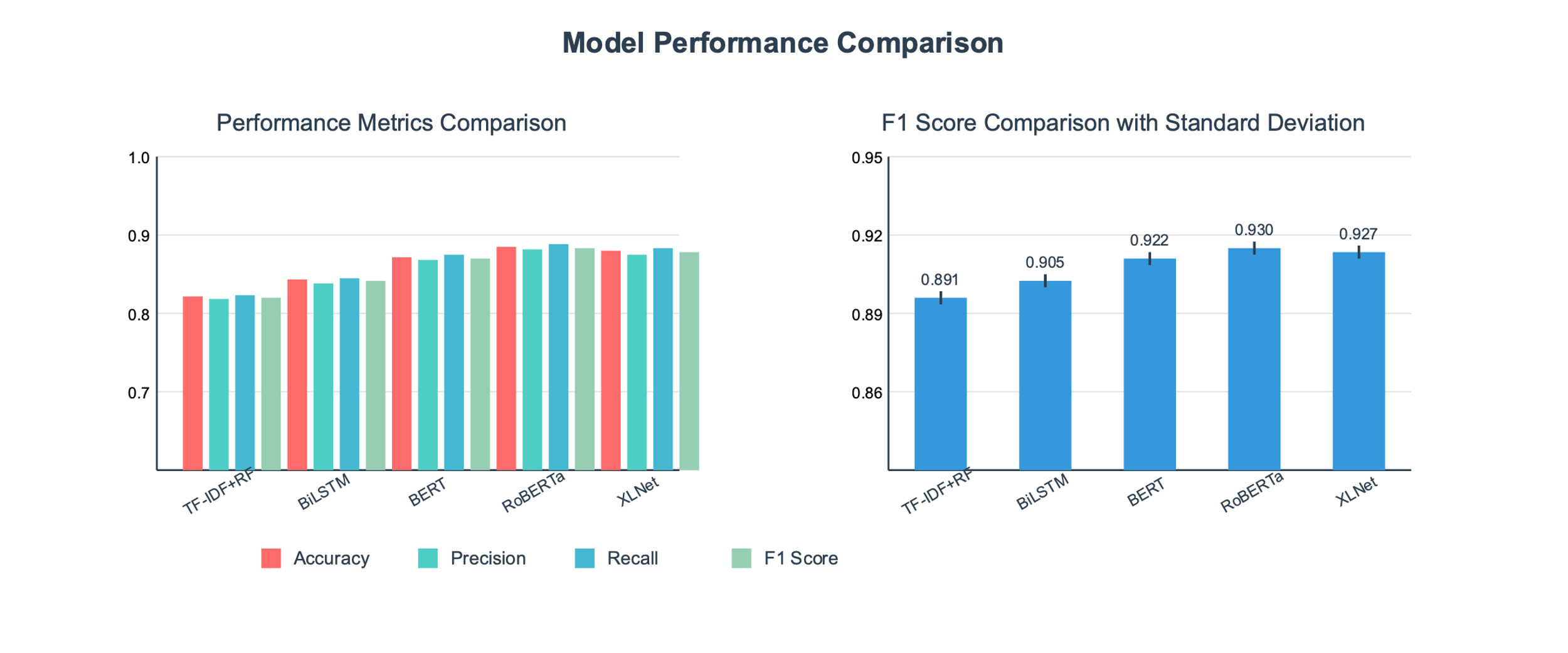
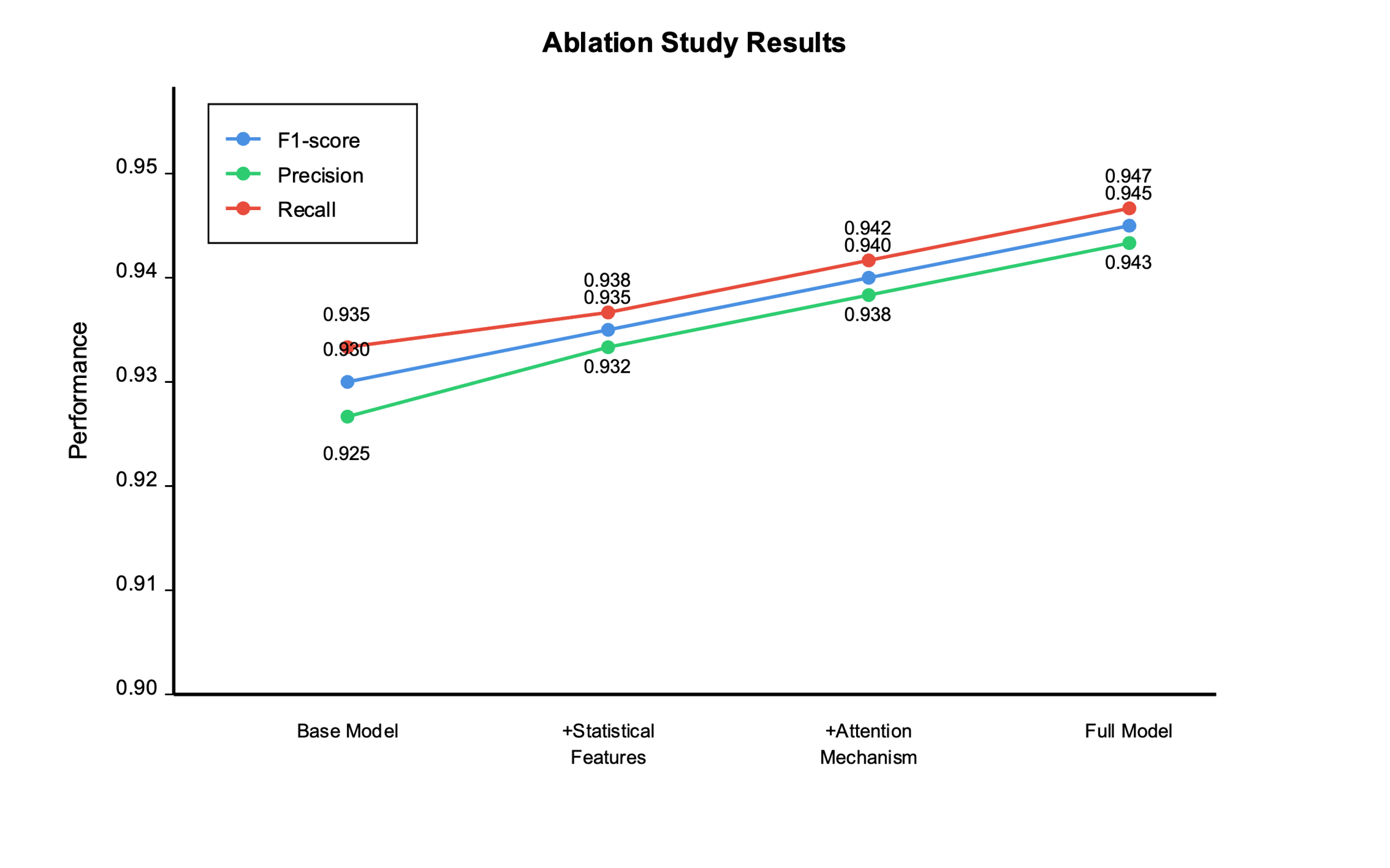
- 实验表明,该模型在WELFake数据集上显著优于现有方法,F1分数提升了1.5%,并具备良好的可解释性。
📝 摘要(中文)
随着在线信息的快速增长,假新闻的传播已成为严重的社会挑战。本研究提出了一种基于大型语言模型(LLMs)的新型检测框架,通过整合文本统计特征和深度语义特征来识别和分类假新闻。该方法利用大型语言模型的上下文理解能力进行文本分析,并引入混合注意力机制来关注对假新闻识别特别重要的特征组合。在WELFake新闻数据集上的大量实验表明,我们的模型显著优于现有方法,F1分数提高了1.5%。此外,我们通过注意力热图和SHAP值评估了模型的可解释性,为内容审查策略提供了可操作的见解。我们的框架为处理假新闻的传播提供了一个可扩展且高效的解决方案,并有助于构建更可靠的在线信息生态系统。
🔬 方法详解
问题定义:该论文旨在解决假新闻检测问题。现有方法通常难以充分利用文本的统计特征和深层语义信息,导致检测性能不佳。此外,现有方法的可解释性较差,难以提供内容审查的有效指导。
核心思路:论文的核心思路是利用大型语言模型(LLMs)强大的上下文理解能力,同时结合文本的统计特征,并通过混合注意力机制来关注对假新闻识别至关重要的特征组合。这种方法旨在更全面地捕捉假新闻的特征,提高检测精度和可解释性。
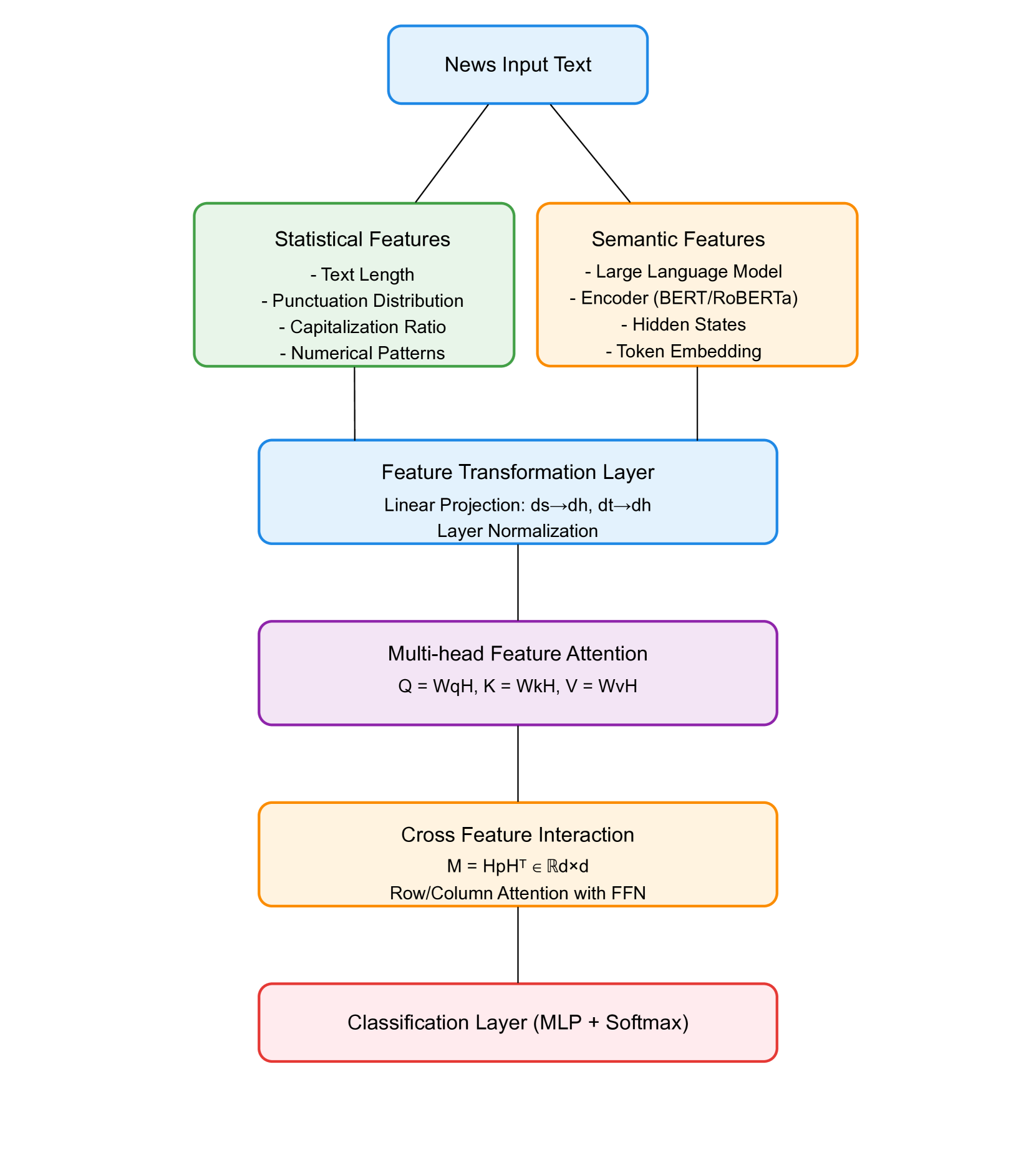
技术框架:该框架主要包含以下几个模块:1) 文本输入模块:接收待检测的新闻文本。2) 特征提取模块:提取文本的统计特征(如词频、句法特征等)和利用大型语言模型提取深层语义特征。3) 混合注意力模块:引入混合注意力机制,学习不同特征组合的重要性,并对特征进行加权融合。4) 分类模块:利用融合后的特征进行假新闻分类。
关键创新:该论文的关键创新在于混合注意力机制的设计,它能够自适应地学习不同特征组合的重要性,从而更有效地识别假新闻。与传统的注意力机制不同,该混合注意力机制能够同时关注文本的统计特征和深层语义特征,从而更全面地捕捉假新闻的特征。
关键设计:论文中使用了预训练的大型语言模型(具体模型未明确说明),并针对假新闻检测任务进行了微调。混合注意力机制的具体实现细节(如注意力头的数量、注意力计算方式等)以及损失函数的设计(如交叉熵损失函数)在论文中没有详细描述,属于未知信息。此外,特征提取模块中使用的具体统计特征也没有明确说明。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该模型在WELFake新闻数据集上取得了显著的性能提升,F1分数比现有最佳方法提高了1.5%。此外,通过注意力热图和SHAP值等可视化工具,该模型展现出良好的可解释性,能够为内容审查提供有价值的参考。
🎯 应用场景
该研究成果可应用于在线新闻平台、社交媒体平台等,用于自动检测和过滤假新闻,从而净化网络信息环境,提高信息的可信度。该技术还可以辅助人工内容审查,提高审查效率和准确性,降低假新闻传播带来的负面影响。
📄 摘要(原文)
With the rapid growth of online information, the spread of fake news has become a serious social challenge. In this study, we propose a novel detection framework based on Large Language Models (LLMs) to identify and classify fake news by integrating textual statistical features and deep semantic features. Our approach utilizes the contextual understanding capability of the large language model for text analysis and introduces a hybrid attention mechanism to focus on feature combinations that are particularly important for fake news identification. Extensive experiments on the WELFake news dataset show that our model significantly outperforms existing methods, with a 1.5\% improvement in F1 score. In addition, we assess the interpretability of the model through attention heat maps and SHAP values, providing actionable insights for content review strategies. Our framework provides a scalable and efficient solution to deal with the spread of fake news and helps build a more reliable online information ecosystem.