Proverbs Run in Pairs: Evaluating Proverb Translation Capability of Large Language Model
作者: Minghan Wang, Viet-Thanh Pham, Farhad Moghimifar, Thuy-Trang Vu
分类: cs.CL
发布日期: 2025-01-21
💡 一句话要点
评估大语言模型谚语翻译能力,揭示文化元素翻译的挑战与评估难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器翻译 谚语翻译 文化元素 大语言模型 神经机器翻译 自动评估指标 数据集构建
📋 核心要点
- 机器翻译在文化元素翻译方面存在不足,尤其是在谚语等富含文化内涵的表达上。
- 该研究构建谚语翻译数据集,对比神经机器翻译和大语言模型在谚语翻译上的表现。
- 实验表明大语言模型在谚语翻译上优于神经机器翻译,并指出现有评估指标的局限性。
📝 摘要(中文)
尽管机器翻译(MT)取得了显著的性能,但在翻译语言中的文化元素(如习语、谚语和口语表达)方面,机器翻译研究仍未得到充分探索。本文研究了最先进的神经机器翻译(NMT)和大语言模型(LLM)在翻译谚语方面的能力,谚语深深植根于文化背景中。我们构建了一个包含独立谚语和对话中谚语的翻译数据集,涵盖四种语言对。实验表明,所研究的模型可以在具有相似文化背景的语言之间实现良好的翻译,并且LLM在谚语翻译方面通常优于NMT模型。此外,我们发现当前自动评估指标(如BLEU、CHRF++和COMET)不足以可靠地评估谚语翻译的质量,突出了对更具文化意识的评估指标的需求。
🔬 方法详解
问题定义:论文旨在解决机器翻译在处理文化元素,特别是谚语翻译时遇到的困难。现有的机器翻译模型,包括神经机器翻译模型,在翻译谚语时往往无法准确捕捉其文化内涵,导致翻译质量不佳。此外,现有的自动评估指标,如BLEU等,也无法有效评估谚语翻译的质量,因为它们缺乏对文化背景的理解。
核心思路:论文的核心思路是通过构建一个专门的谚语翻译数据集,并对比神经机器翻译模型和大语言模型在该数据集上的表现,来评估它们在谚语翻译方面的能力。同时,论文还探讨了现有自动评估指标在评估谚语翻译质量方面的局限性,并呼吁开发更具文化意识的评估指标。
技术框架:该研究的技术框架主要包括以下几个部分:1)构建谚语翻译数据集,包含独立谚语和对话中的谚语,涵盖四种语言对。2)使用神经机器翻译模型和大语言模型对数据集进行翻译。3)使用现有的自动评估指标(如BLEU、CHRF++和COMET)评估翻译质量。4)分析实验结果,探讨不同模型在谚语翻译方面的优缺点,以及现有评估指标的局限性。
关键创新:该研究的关键创新点在于:1)构建了一个专门用于评估机器翻译模型谚语翻译能力的翻译数据集。2)对比了神经机器翻译模型和大语言模型在谚语翻译方面的表现,揭示了大语言模型在处理文化元素方面的优势。3)指出了现有自动评估指标在评估谚语翻译质量方面的局限性,强调了开发更具文化意识的评估指标的重要性。
关键设计:论文的关键设计包括:1)数据集的构建,需要选择合适的谚语,并进行准确的翻译。2)模型的选择,需要选择具有代表性的神经机器翻译模型和大语言模型。3)评估指标的选择,需要选择常用的自动评估指标,并分析其在评估谚语翻译质量方面的局限性。具体的参数设置、损失函数、网络结构等技术细节在论文中未详细描述,属于模型本身的固有设置。
🖼️ 关键图片
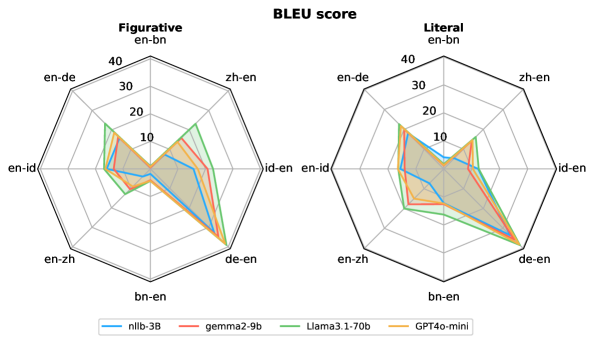


📊 实验亮点
实验结果表明,大语言模型在谚语翻译方面通常优于神经机器翻译模型,尤其是在具有相似文化背景的语言之间。然而,现有的自动评估指标(如BLEU、CHRF++和COMET)在评估谚语翻译质量方面存在局限性,无法准确反映翻译的文化内涵。具体的性能数据和提升幅度在摘要中未给出。
🎯 应用场景
该研究成果可应用于改进机器翻译系统,使其能够更准确地翻译包含文化元素的文本,例如文学作品、电影字幕和跨文化交流材料。此外,该研究也为开发更具文化意识的机器翻译评估指标提供了参考,有助于提高机器翻译的整体质量和用户体验。未来,该研究可以扩展到更多语言和文化,并探索更有效的文化元素翻译方法。
📄 摘要(原文)
Despite achieving remarkable performance, machine translation (MT) research remains underexplored in terms of translating cultural elements in languages, such as idioms, proverbs, and colloquial expressions. This paper investigates the capability of state-of-the-art neural machine translation (NMT) and large language models (LLMs) in translating proverbs, which are deeply rooted in cultural contexts. We construct a translation dataset of standalone proverbs and proverbs in conversation for four language pairs. Our experiments show that the studied models can achieve good translation between languages with similar cultural backgrounds, and LLMs generally outperform NMT models in proverb translation. Furthermore, we find that current automatic evaluation metrics such as BLEU, CHRF++ and COMET are inadequate for reliably assessing the quality of proverb translation, highlighting the need for more culturally aware evaluation metrics.