From Drafts to Answers: Unlocking LLM Potential via Aggregation Fine-Tuning
作者: Yafu Li, Zhilin Wang, Tingchen Fu, Ganqu Cui, Sen Yang, Yu Cheng
分类: cs.CL, cs.AI
发布日期: 2025-01-21
备注: 20 pages; work in progress
💡 一句话要点
提出聚合微调(AFT)方法,通过学习整合草稿答案提升大语言模型性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 聚合微调 大语言模型 提案-聚合 监督学习 模型优化
📋 核心要点
- 现有大语言模型依赖于扩大数据和模型规模来提升性能,但成本高昂,测试时增加计算资源是另一种有效途径。
- AFT方法通过让模型学习整合多个草稿回复,生成更精炼的答案,从而提升模型性能,无需增加数据或模型规模。
- 实验表明,AFT训练的模型显著优于标准SFT模型,甚至超越了更大的LLM,证明了AFT的有效性。
📝 摘要(中文)
本文提出了一种名为聚合微调(AFT)的监督微调范式,该方法使模型学习将多个草稿回复(称为提案)合成为一个精炼的答案(称为聚合)。在推理时,一种“提案-聚合”策略通过迭代生成提案并聚合它们来进一步提高性能。在基准数据集上的实验评估表明,经过AFT训练的模型显著优于标准监督微调(SFT)模型。值得注意的是,一个基于Llama3.1-8B-Base进行AFT微调的模型,仅使用64k数据,在AlpacaEval 2上实现了41.3%的LC胜率,超过了Llama3.1-405B-Instruct和GPT4等更大的LLM。通过结合顺序细化和并行采样,“提案-聚合”框架以灵活的方式扩展了推理时的计算量。总而言之,这些发现表明AFT是一种有前景的方法,可以在不增加数据量或模型大小的情况下释放LLM的额外能力。
🔬 方法详解
问题定义:现有大语言模型提升性能主要依赖于扩大数据和模型规模,这带来了更高的训练和部署成本。如何在不显著增加数据或模型规模的前提下,进一步提升大语言模型的性能是一个关键问题。现有方法在推理时计算资源利用率较低,未能充分挖掘模型的潜力。
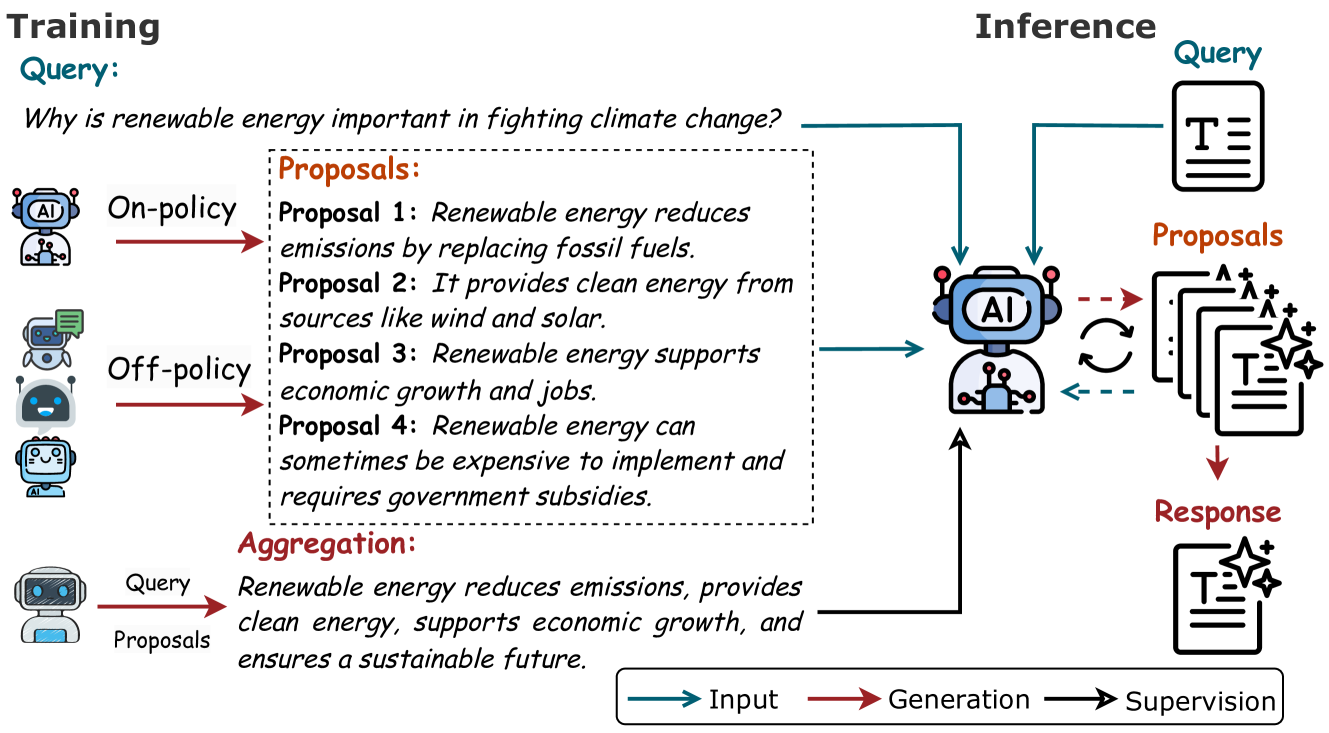
核心思路:AFT的核心思路是让模型学习如何有效地利用更多的计算资源,通过生成多个“草稿”答案(提案),然后将这些提案聚合为一个更精炼、更准确的最终答案。这种“提案-聚合”的模式模拟了人类思考的过程,即先产生多个想法,然后进行综合和提炼。
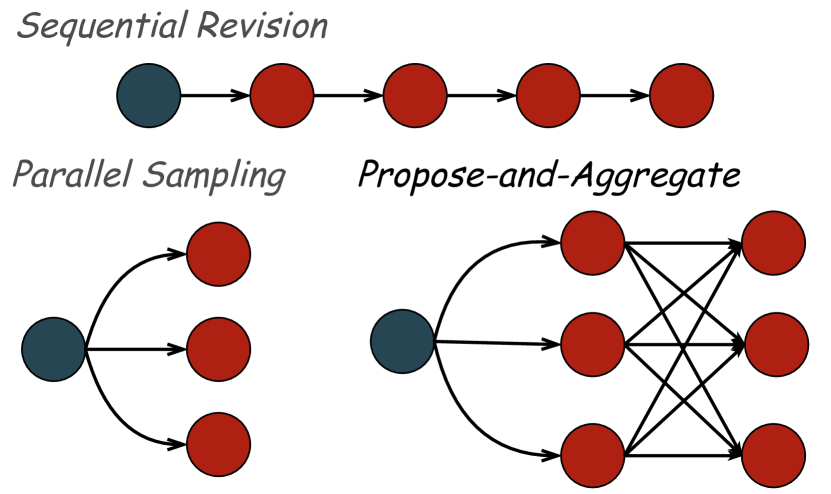
技术框架:AFT包含两个主要阶段:微调阶段和推理阶段。在微调阶段,模型接受监督学习,学习将多个提案合成为一个高质量的聚合答案。微调数据由多个提案及其对应的聚合答案组成。在推理阶段,模型首先生成多个提案,然后使用微调后的模型将这些提案聚合为一个最终答案。这个过程可以迭代进行,即可以将聚合后的答案再次作为提案,进行下一轮的聚合。
关键创新:AFT的关键创新在于它将“聚合”的概念引入到大语言模型的微调和推理过程中。与传统的监督微调不同,AFT不仅学习生成答案,还学习如何整合多个答案,从而更好地利用模型内部的知识和推理能力。此外,“提案-聚合”框架允许灵活地扩展推理时的计算量,通过增加提案的数量或迭代的次数,可以进一步提高性能。
关键设计:AFT的关键设计包括:1) 如何生成高质量的提案:可以使用不同的采样策略,例如top-k sampling或nucleus sampling,来生成多样化的提案。2) 如何有效地聚合提案:可以使用不同的聚合函数,例如平均、加权平均或使用一个专门的聚合模型。3) 如何构建微调数据集:需要收集或生成包含多个提案及其对应聚合答案的数据集。论文中使用了64k的数据集进行微调,并取得了显著的效果。
🖼️ 关键图片

📊 实验亮点
AFT模型在AlpacaEval 2上取得了显著的成果。仅使用64k数据,基于Llama3.1-8B-Base进行AFT微调的模型,实现了41.3%的LC胜率,超过了Llama3.1-405B-Instruct和GPT4等更大的LLM。这表明AFT能够有效地提升模型的性能,并且在数据量有限的情况下也能取得优异的结果。
🎯 应用场景
AFT方法可以广泛应用于各种需要高质量文本生成的场景,例如问答系统、文本摘要、机器翻译等。通过AFT,可以在不增加模型大小或数据量的情况下,显著提升这些应用的性能。此外,AFT还可以用于提升模型的鲁棒性和泛化能力,使其在面对复杂或不确定性输入时,能够生成更可靠的答案。未来,AFT有望成为一种通用的模型优化技术,应用于各种大语言模型。
📄 摘要(原文)
Scaling data and model size has been proven effective for boosting the performance of large language models. In addition to training-time scaling, recent studies have revealed that increasing test-time computational resources can further improve performance. In this work, we introduce Aggregation Fine-Tuning (AFT), a supervised finetuning paradigm where the model learns to synthesize multiple draft responses, referred to as proposals, into a single, refined answer, termed aggregation. At inference time, a propose-and-aggregate strategy further boosts performance by iteratively generating proposals and aggregating them. Empirical evaluations on benchmark datasets show that AFT-trained models substantially outperform standard SFT. Notably, an AFT model, fine-tuned from Llama3.1-8B-Base with only 64k data, achieves a 41.3% LC win rate on AlpacaEval 2, surpassing significantly larger LLMs such as Llama3.1-405B-Instruct and GPT4. By combining sequential refinement and parallel sampling, the propose-and-aggregate framework scales inference-time computation in a flexible manner. Overall, These findings position AFT as a promising approach to unlocking additional capabilities of LLMs without resorting to increasing data volume or model size.