Benchmarking LLMs' Mathematical Reasoning with Unseen Random Variables Questions
作者: Zijin Hong, Hao Wu, Su Dong, Junnan Dong, Yilin Xiao, Yujing Zhang, Zhu Wang, Feiran Huang, Linyi Li, Hongxia Yang, Xiao Huang
分类: cs.CL, cs.AI
发布日期: 2025-01-20 (更新: 2025-08-13)
💡 一句话要点
提出RV-Bench,用于评估LLM在随机变量数学问题上的推理能力。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数学推理 基准测试 随机变量 泛化能力
📋 核心要点
- 现有数学基准测试设计过于简单,且存在数据污染问题,难以有效评估LLM的真实数学推理能力。
- 论文提出RV-Bench,通过生成具有随机变量组合的数学问题,评估LLM在“未见”数据上的推理能力。
- 实验表明,LLM在已见和未见数据上表现出能力不平衡,但可以通过测试时缩放来提升泛化能力。
📝 摘要(中文)
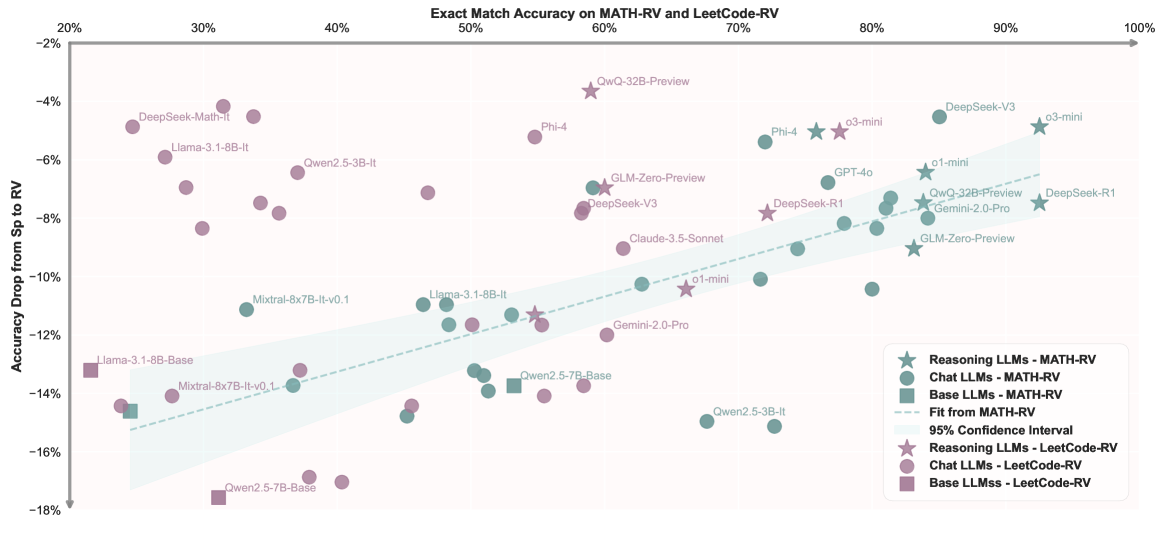
当前数学基准测试的可靠性备受质疑,存在设计简单和数据污染等问题。为了解决这些问题,本文提出了一种新的评估方法RV-Bench,用于评估大型语言模型(LLM)在数学推理中处理随机变量的能力。具体来说,我们构建了问题生成函数来生成随机变量问题(RVQ),其背景内容与原始基准问题相似,但具有随机化的变量组合,这使得LLM难以直接从训练数据中找到答案。模型必须完全理解内在的问题模式,才能正确回答具有不同变量组合的RVQ。因此,LLM在RV-Bench上的准确性和鲁棒性反映了其真正的推理能力。我们对30多个具有代表性的LLM进行了超过1000个RVQ的广泛实验。我们的研究结果表明,LLM在已遇到和“未见”数据分布之间表现出能力不平衡。此外,RV-Bench揭示了相似数学推理任务之间的熟练程度泛化能力有限,但我们验证了可以通过测试时缩放有效地激发这种能力。
🔬 方法详解
问题定义:现有数学基准测试存在数据泄露和题目过于简单的问题,导致LLM可能通过记忆而非真正的推理来解决问题。这使得评估LLM的真实数学推理能力变得困难。因此,需要一种新的基准测试,能够有效区分LLM的记忆能力和推理能力。
核心思路:核心思路是生成“未见”的数学问题,即LLM在训练数据中没有直接遇到过的题目。通过随机化问题中的变量组合,使得LLM无法简单地通过记忆来解决问题,而必须真正理解问题的内在逻辑和推理模式。
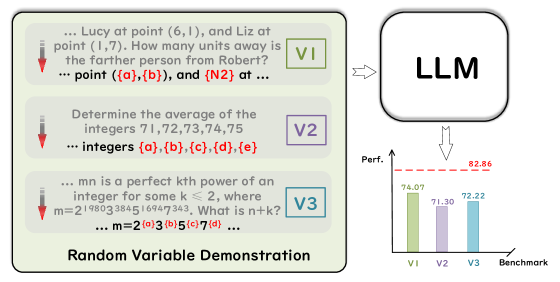
技术框架:RV-Bench的技术框架主要包括以下几个步骤:1) 选择现有的数学基准测试作为基础;2) 构建问题生成函数,该函数能够根据原始问题生成具有随机变量组合的新问题(RVQ);3) 使用生成的RVQ对LLM进行评估;4) 分析LLM在RVQ上的表现,从而评估其真实的数学推理能力。
关键创新:关键创新在于使用问题生成函数来生成具有随机变量组合的“未见”问题。这种方法能够有效地避免数据泄露问题,并迫使LLM进行真正的推理。与现有方法相比,RV-Bench能够更准确地评估LLM的数学推理能力。
关键设计:问题生成函数的关键设计在于如何保证生成的问题与原始问题在语义上相似,但变量组合是随机的。这需要仔细设计变量替换规则,并确保替换后的问题仍然具有数学意义。此外,还需要考虑如何控制生成问题的难度,以确保能够有效区分不同LLM的推理能力。
🖼️ 关键图片

📊 实验亮点
在超过30个LLM上进行的实验表明,LLM在RV-Bench上表现出显著的性能下降,揭示了LLM在已见和未见数据上的能力不平衡。此外,实验还发现,通过测试时缩放可以有效提升LLM在RV-Bench上的性能,表明可以通过一些技术手段来改善LLM的泛化能力。
🎯 应用场景
RV-Bench可用于评估和比较不同LLM的数学推理能力,帮助研究人员了解LLM在数学领域的优势和不足。此外,该方法还可以用于开发更强大的数学推理模型,并将其应用于科学计算、金融分析等领域。未来,RV-Bench的思路可以推广到其他推理领域,例如逻辑推理、常识推理等。
📄 摘要(原文)
Recent studies have raised significant concerns regarding the reliability of current mathematics benchmarks, highlighting issues such as simplistic design and potential data contamination. Consequently, developing a reliable benchmark that effectively evaluates large language models' (LLMs) genuine capabilities in mathematical reasoning remains a critical challenge. To address these concerns, we propose RV-Bench, a novel evaluation methodology for Benchmarking LLMs with Random Variables in mathematical reasoning. Specifically, we build question-generating functions to produce random variable questions (RVQs), whose background content mirrors original benchmark problems, but with randomized variable combinations, rendering them "unseen" to LLMs. Models must completely understand the inherent question pattern to correctly answer RVQs with diverse variable combinations. Thus, an LLM's genuine reasoning capability is reflected through its accuracy and robustness on RV-Bench. We conducted extensive experiments on over 30 representative LLMs across more than 1,000 RVQs. Our findings propose that LLMs exhibit a proficiency imbalance between encountered and ``unseen'' data distributions. Furthermore, RV-Bench reveals that proficiency generalization across similar mathematical reasoning tasks is limited, but we verified it can still be effectively elicited through test-time scaling.