Synthetic Data Can Mislead Evaluations: Membership Inference as Machine Text Detection
作者: Ali Naseh, Niloofar Mireshghallah
分类: cs.CL, cs.CR, cs.LG
发布日期: 2025-01-20
💡 一句话要点
揭示合成数据在LLM成员推断评估中的误导性:MIA作为机器文本检测器
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 成员推断攻击 合成数据 大型语言模型 模型评估 数据泄露 机器文本检测 隐私保护
📋 核心要点
- 现有成员推断攻击(MIA)在大型语言模型(LLM)上结果不确定,缺乏可靠的非成员数据集是主要挑战。
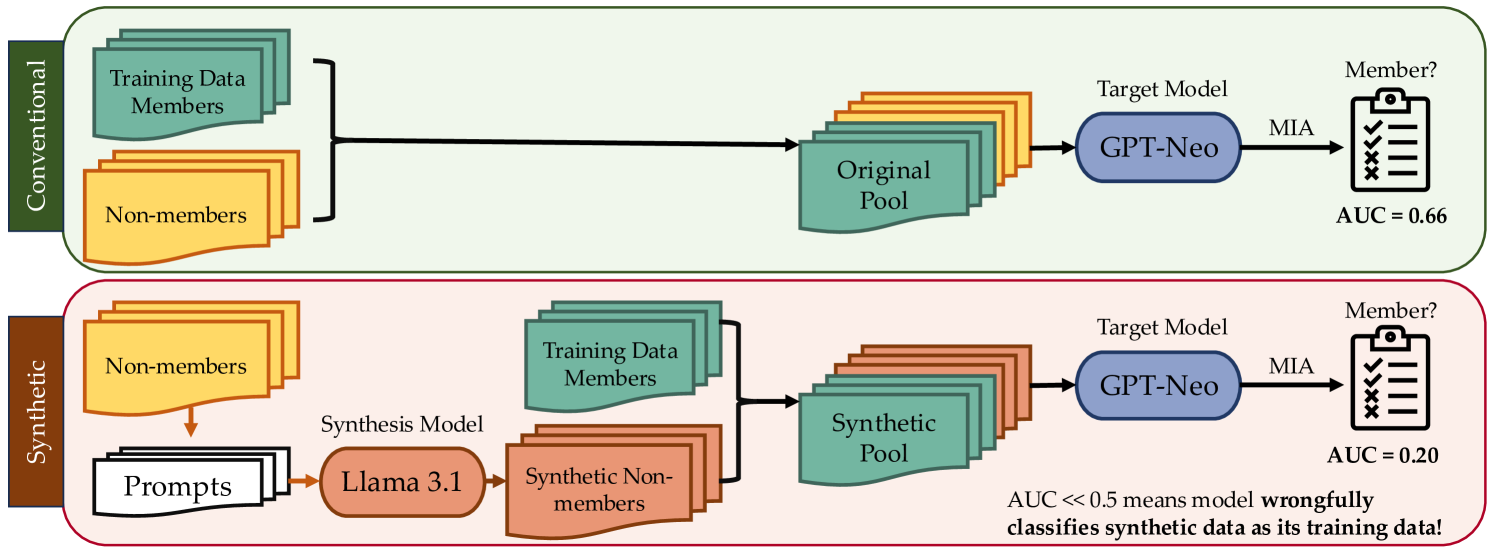
- 该论文指出使用合成数据进行MIA评估会产生误导,MIA实际上将合成数据识别为训练数据,而非区分成员与非成员。
- 实验表明,这种现象在不同架构和规模的LLM中普遍存在,即使使用更强大的模型生成的合成数据也无法避免。
📝 摘要(中文)
最近的研究表明,对大型语言模型(LLM)的成员推断攻击(MIA)产生的结果不确定,部分原因是难以创建没有时间偏移的非成员数据集。虽然研究人员已经转向使用合成数据作为替代方案,但我们表明这种方法可能从根本上具有误导性。我们的实验表明,MIA的功能类似于机器生成的文本检测器,错误地将合成数据识别为训练样本,而与数据来源无关。这种行为在不同的模型架构和大小(从开源模型到GPT-3.5等商业模型)中持续存在。即使是由不同的、可能更大的模型生成的合成文本,也会被目标模型分类为训练数据。我们的发现突出了一个严重的问题:在成员评估中使用合成数据可能会导致关于模型记忆和数据泄露的错误结论。我们警告说,这个问题可能会影响使用模型信号(如损失)的其他评估,在这些评估中,合成或机器翻译的数据取代了真实世界的样本。
🔬 方法详解
问题定义:论文旨在解决使用合成数据评估大型语言模型(LLM)的成员推断攻击(MIA)时产生的误导性问题。现有方法依赖合成数据来构建非成员数据集,但这种方法的有效性受到质疑,因为合成数据可能与真实训练数据存在显著差异,导致评估结果偏差。
核心思路:论文的核心思路是揭示MIA实际上倾向于将合成数据识别为训练数据,无论其来源如何。这意味着MIA的行为更像是一个机器生成文本的检测器,而不是一个真正的成员推断工具。因此,使用合成数据进行MIA评估可能会高估模型的记忆能力和数据泄露风险。
技术框架:论文通过一系列实验来验证其核心思路。这些实验包括: 1. 使用不同的LLM(包括开源模型和商业模型,如GPT-3.5)作为目标模型。 2. 使用不同的方法生成合成数据,包括使用不同的模型和不同的生成策略。 3. 使用标准的MIA方法来判断给定的样本是否属于目标模型的训练集。 4. 分析MIA的输出,以确定其是否能够区分真实训练数据和合成数据。
关键创新:论文的关键创新在于发现了MIA在评估LLM时的一个潜在陷阱:MIA可能会将合成数据错误地识别为训练数据。这一发现挑战了使用合成数据进行MIA评估的有效性,并提出了对模型记忆和数据泄露评估的新视角。
关键设计:论文没有提出新的MIA方法,而是侧重于分析现有MIA方法在合成数据上的表现。关键的设计在于实验设置,包括选择具有代表性的LLM、使用多样化的合成数据生成方法,以及采用标准的MIA评估流程。论文通过控制变量,例如合成数据的来源和生成方式,来验证MIA对合成数据的偏好。
🖼️ 关键图片
📊 实验亮点
实验结果表明,无论目标模型的大小和架构,MIA都倾向于将合成数据识别为训练数据。即使使用比目标模型更大的模型生成的合成数据,也无法避免被错误分类。这表明MIA的行为更像是一个机器生成文本的检测器,而非真正的成员推断工具。该发现对使用合成数据进行LLM安全评估提出了质疑。
🎯 应用场景
该研究成果对LLM的安全评估具有重要意义,尤其是在数据隐私保护方面。它警示研究人员在使用合成数据进行模型评估时需要谨慎,避免得出错误的结论。未来的研究可以探索更可靠的非成员数据集构建方法,或者开发更鲁棒的MIA方法,以更准确地评估LLM的记忆能力和数据泄露风险。
📄 摘要(原文)
Recent work shows membership inference attacks (MIAs) on large language models (LLMs) produce inconclusive results, partly due to difficulties in creating non-member datasets without temporal shifts. While researchers have turned to synthetic data as an alternative, we show this approach can be fundamentally misleading. Our experiments indicate that MIAs function as machine-generated text detectors, incorrectly identifying synthetic data as training samples regardless of the data source. This behavior persists across different model architectures and sizes, from open-source models to commercial ones such as GPT-3.5. Even synthetic text generated by different, potentially larger models is classified as training data by the target model. Our findings highlight a serious concern: using synthetic data in membership evaluations may lead to false conclusions about model memorization and data leakage. We caution that this issue could affect other evaluations using model signals such as loss where synthetic or machine-generated translated data substitutes for real-world samples.