The Value of Nothing: Multimodal Extraction of Human Values Expressed by TikTok Influencers
作者: Alina Starovolsky-Shitrit, Alon Neduva, Naama Appel Doron, Ella Daniel, Oren Tsur
分类: cs.CL, cs.CY, cs.SI
发布日期: 2025-01-20
💡 一句话要点
提出一种基于多模态的TikTok网红价值观提取方法,用于分析社交平台对青少年价值观的影响。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 价值观提取 多模态分析 TikTok 社交媒体影响 青少年研究
📋 核心要点
- 社交平台日益成为青少年获取信息和娱乐的主要渠道,但现有方法难以有效提取视频内容中隐含的价值观。
- 论文提出一种两步法,首先将视频转换为文本脚本,然后利用Masked语言模型提取价值观,从而提高提取准确率。
- 实验表明,该方法优于直接从视频提取价值观的方法,并构建了首个价值观标注的TikTok视频数据集。
📝 摘要(中文)
本研究旨在提取TikTok网红视频中蕴含的价值观,探讨社交平台对青少年价值观的影响。我们构建了一个包含数百个TikTok视频的数据集,并根据Schwartz个人价值观理论对其进行标注。我们实验了多种Masked语言模型和大型语言模型,探索价值观的检测方法。具体而言,我们考虑了两种pipeline:直接从视频中提取价值观,以及先将视频转换为详细脚本再提取价值观的两步法。实验结果表明,两步法显著优于直接法,并且使用可训练的Masked语言模型作为第二步明显优于大型语言模型的小样本应用。我们进一步讨论了微调的影响,并比较了不同模型在识别TikTok视频中存在或矛盾的价值观方面的性能。最后,我们分享了首个价值观标注的TikTok视频数据集。我们的研究结果为进一步研究基于视频的社交平台中的影响和价值观传播铺平了道路。
🔬 方法详解
问题定义:本研究旨在解决如何从TikTok网红发布的视频中提取隐含的价值观这一问题。现有方法,如直接从视频内容提取,忽略了视频中复杂的视觉和听觉信息,以及文本描述中的细微差别,导致价值观提取的准确率较低。此外,缺乏标注数据也限制了模型的训练和评估。
核心思路:论文的核心思路是将多模态的视频信息转化为文本信息,利用自然语言处理技术提取价值观。具体来说,首先使用语音识别和图像描述技术将视频内容转化为文本脚本,然后利用语言模型分析文本脚本中蕴含的价值观。这种两步法可以更全面地捕捉视频中的信息,提高价值观提取的准确率。
技术框架:整体框架包含两个主要阶段:1) 视频转脚本阶段:利用现有的语音识别(ASR)和图像描述(Image Captioning)技术,将视频的音频和视觉信息转化为文本脚本。2) 价值观提取阶段:利用Masked语言模型(MLM)或大型语言模型(LLM)分析文本脚本,提取其中蕴含的价值观。研究比较了直接从视频提取价值观和两步法的性能。
关键创新:本研究的关键创新在于提出了一个两步法的多模态价值观提取框架,该框架能够有效地利用视频中的音频、视觉和文本信息。此外,研究还构建了首个价值观标注的TikTok视频数据集,为相关研究提供了宝贵的数据资源。研究发现,使用可训练的Masked语言模型作为第二步明显优于大型语言模型的小样本应用。
关键设计:在视频转脚本阶段,研究使用了现有的ASR和Image Captioning模型,没有进行特别的设计。在价值观提取阶段,研究尝试了多种Masked语言模型和大型语言模型,并比较了它们的性能。研究还探索了微调对模型性能的影响。具体而言,研究使用了Schwartz个人价值观理论作为价值观的分类体系,并根据该理论对TikTok视频进行标注。
🖼️ 关键图片
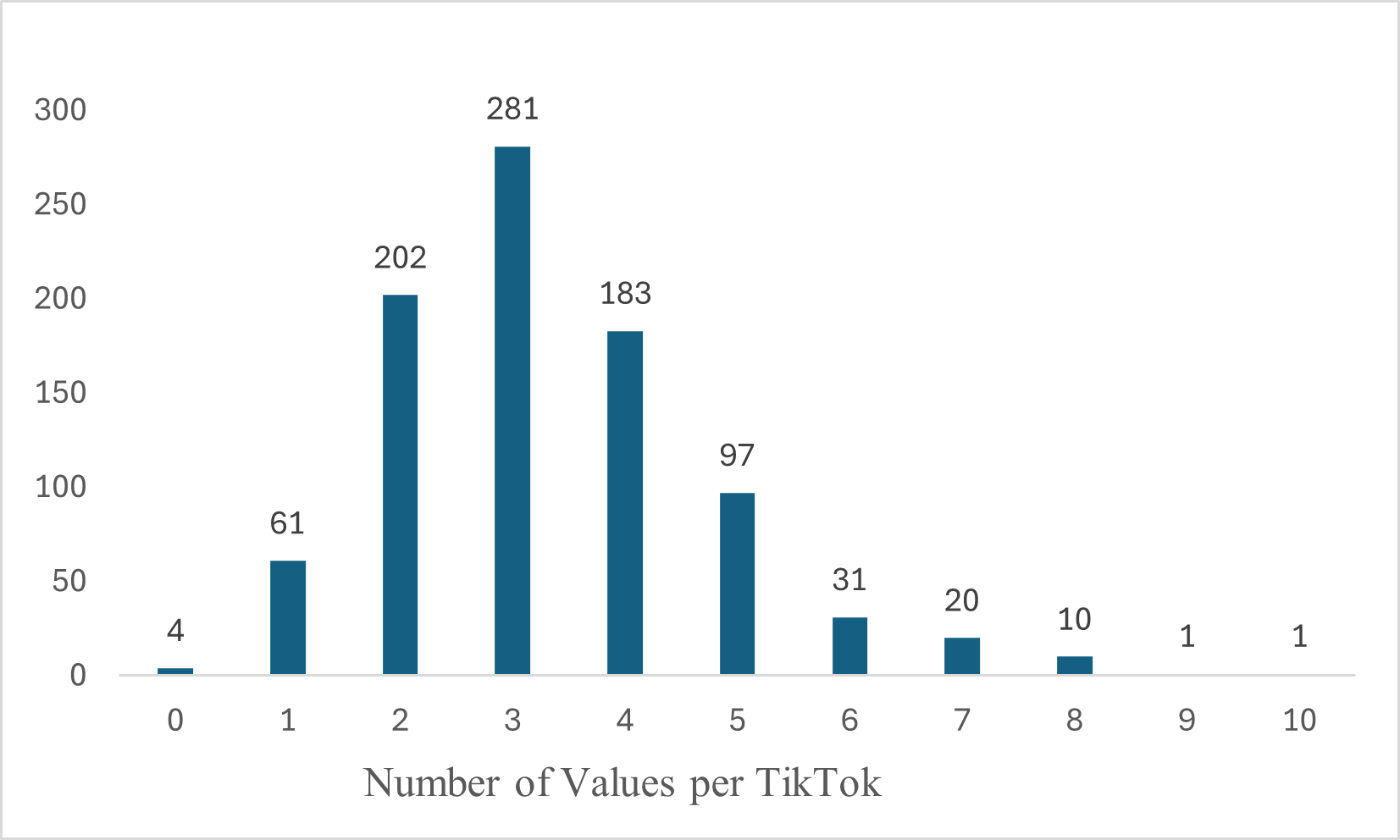
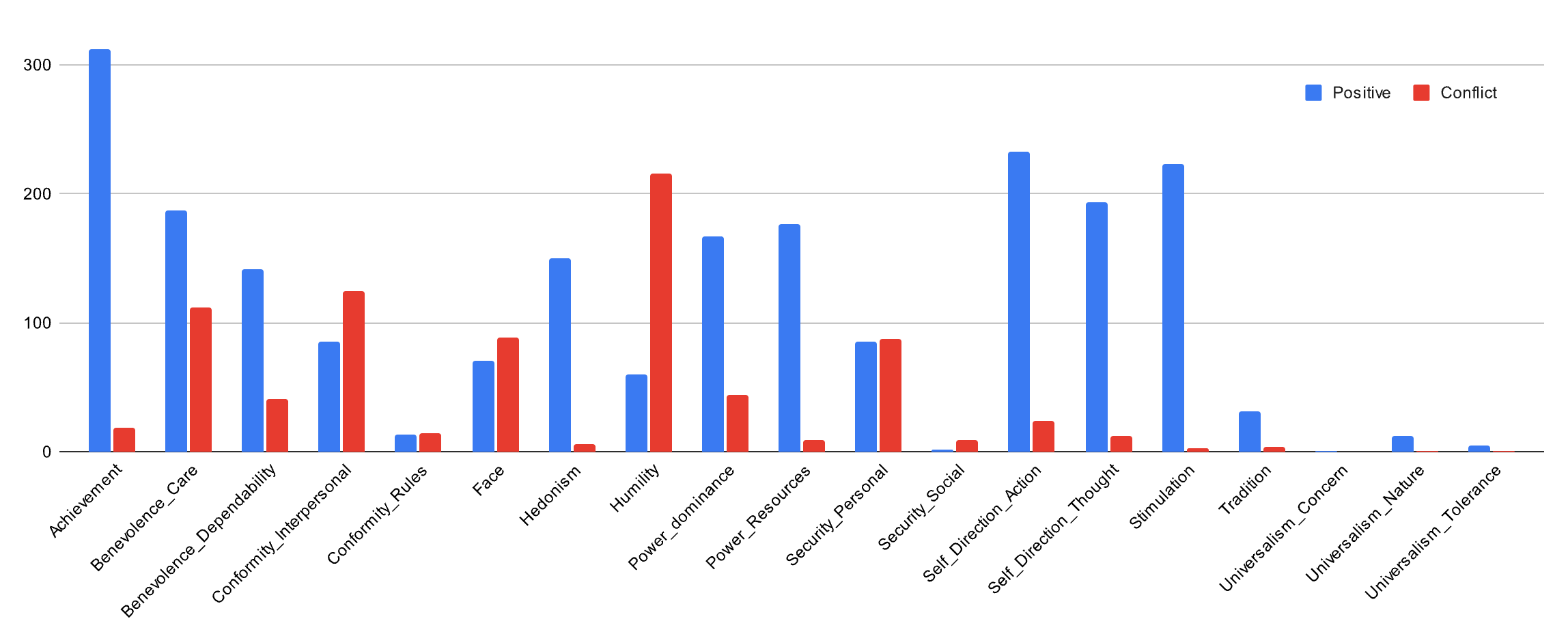

📊 实验亮点
实验结果表明,两步法显著优于直接从视频提取价值观的方法。具体而言,使用可训练的Masked语言模型作为第二步,其性能明显优于大型语言模型的小样本应用。此外,研究还构建了首个价值观标注的TikTok视频数据集,为后续研究提供了基准和数据资源。
🎯 应用场景
该研究成果可应用于分析社交媒体平台对青少年价值观的影响,帮助教育工作者和家长更好地了解青少年所接触的信息,并采取相应的引导措施。此外,该技术还可用于舆情分析、品牌形象管理等领域,帮助企业了解公众对特定话题或品牌的价值观倾向。
📄 摘要(原文)
Societal and personal values are transmitted to younger generations through interaction and exposure. Traditionally, children and adolescents learned values from parents, educators, or peers. Nowadays, social platforms serve as a significant channel through which youth (and adults) consume information, as the main medium of entertainment, and possibly the medium through which they learn different values. In this paper we extract implicit values from TikTok movies uploaded by online influencers targeting children and adolescents. We curated a dataset of hundreds of TikTok movies and annotated them according to the Schwartz Theory of Personal Values. We then experimented with an array of Masked and Large language model, exploring how values can be detected. Specifically, we considered two pipelines -- direct extraction of values from video and a 2-step approach in which videos are first converted to elaborated scripts and then values are extracted. Achieving state-of-the-art results, we find that the 2-step approach performs significantly better than the direct approach and that using a trainable Masked Language Model as a second step significantly outperforms a few-shot application of a number of Large Language Models. We further discuss the impact of fine-tuning and compare the performance of the different models on identification of values present or contradicted in the TikTok. Finally, we share the first values-annotated dataset of TikTok videos. Our results pave the way to further research on influence and value transmission in video-based social platforms.