Trojan Detection Through Pattern Recognition for Large Language Models
作者: Vedant Bhasin, Matthew Yudin, Razvan Stefanescu, Rauf Izmailov
分类: cs.CL, cs.LG
发布日期: 2025-01-20
备注: 20 pages, 11 Figures
💡 一句话要点
提出一种多阶段框架,通过模式识别检测大型语言模型中的特洛伊木马后门。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 特洛伊木马检测 大型语言模型 后门攻击 触发器反演 模式识别
📋 核心要点
- 大型语言模型易受特洛伊木马攻击,现有方法难以在巨大搜索空间中有效检测恶意触发器。
- 论文提出多阶段检测框架,包含令牌过滤、触发器识别和验证,以提升检测准确性。
- 实验结果表明,该方法在TrojAI和RLHF中毒模型数据集上表现出良好的特洛伊木马检测能力。
📝 摘要(中文)
特洛伊木马后门可以在大型语言模型的各个阶段被注入,包括预训练、微调和上下文学习,对模型的对齐构成重大威胁。由于因果语言建模的性质,鉴于庞大的搜索空间,检测这些触发器具有挑战性。在本研究中,我们提出了一种多阶段框架,用于检测大型语言模型中的特洛伊木马触发器,该框架包括令牌过滤、触发器识别和触发器验证。我们讨论了现有的触发器识别方法,并提出了两种黑盒触发器反演方法的变体,这些方法依赖于输出logits,分别利用集束搜索和贪婪解码。我们表明,验证阶段在此过程中至关重要,并提出了语义保留提示和特殊扰动,以区分实际的特洛伊木马触发器和其他表现出类似特征的对抗性字符串。我们在TrojAI和RLHF中毒模型数据集上评估了我们的方法,结果显示出良好的前景。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中特洛伊木马后门触发器的检测问题。现有的检测方法在面对庞大的搜索空间时效率低下,难以有效识别隐藏的恶意触发器。此外,区分真正的特洛伊木马触发器和具有相似特征的对抗性字符串也是一个挑战。
核心思路:论文的核心思路是通过一个多阶段的框架,逐步缩小搜索范围并提高检测精度。首先进行令牌过滤,减少需要分析的令牌数量;然后利用触发器反演方法识别潜在的触发器;最后,通过验证阶段区分真正的特洛伊木马触发器和对抗性样本。这种分阶段的方法旨在提高检测效率和准确性。
技术框架:该框架包含三个主要阶段:1) 令牌过滤:减少需要分析的令牌数量,降低计算复杂度。2) 触发器识别:利用黑盒触发器反演方法,基于输出logits生成候选触发器。论文提出了两种变体:集束搜索和贪婪解码。3) 触发器验证:使用语义保留提示和特殊扰动来区分真正的特洛伊木马触发器和对抗性字符串。
关键创新:该方法的关键创新在于结合了触发器反演和验证阶段,并提出了语义保留提示和特殊扰动来提高验证的准确性。与传统的触发器检测方法相比,该方法能够更有效地识别和区分真正的特洛伊木马触发器。
关键设计:在触发器识别阶段,论文提出了两种黑盒触发器反演方法的变体:集束搜索和贪婪解码。集束搜索旨在探索更广泛的搜索空间,而贪婪解码则更注重效率。在验证阶段,语义保留提示用于在不改变句子含义的情况下测试触发器的有效性,特殊扰动则用于区分特洛伊木马触发器和对抗性样本。具体的参数设置和损失函数细节在论文中未明确给出,可能需要参考相关文献或实验设置。
🖼️ 关键图片

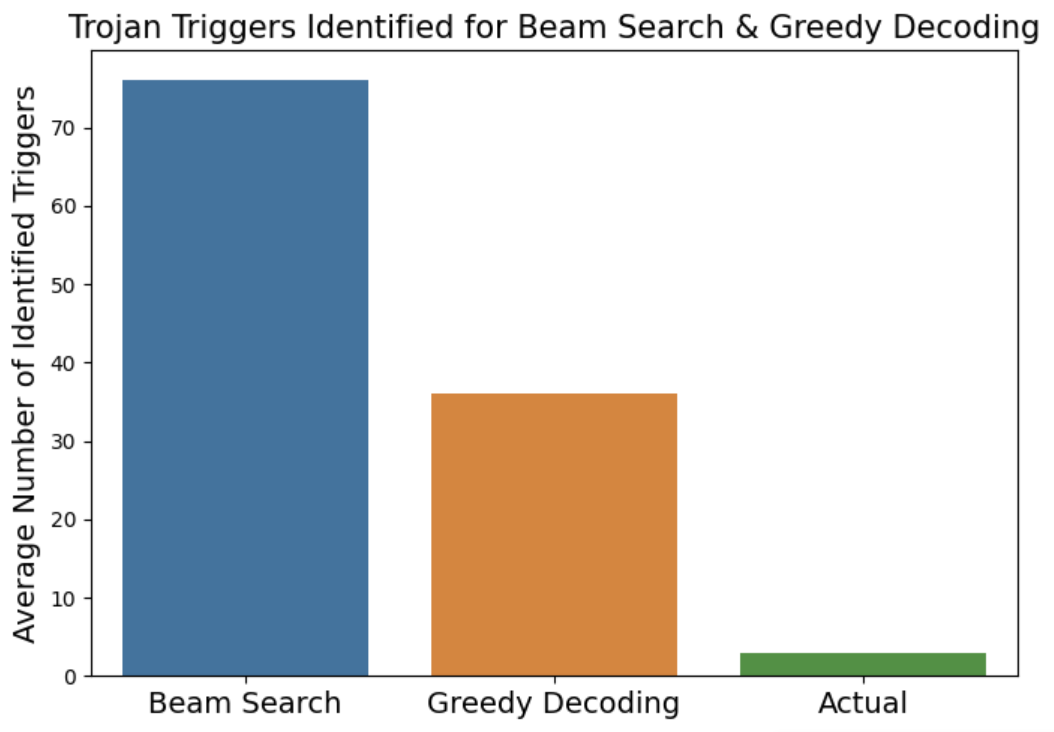

📊 实验亮点
该方法在TrojAI和RLHF中毒模型数据集上进行了评估,结果显示出良好的前景。通过语义保留提示和特殊扰动,该方法能够有效区分真正的特洛伊木马触发器和对抗性字符串,提高了检测的准确性。具体的性能数据和提升幅度需要在论文中查找,但摘要表明该方法具有一定的优势。
🎯 应用场景
该研究成果可应用于提高大型语言模型的安全性,防止恶意攻击者通过特洛伊木马后门操纵模型行为。该方法可以集成到模型的开发和部署流程中,用于检测和防御潜在的后门攻击,保障模型的可靠性和安全性。未来,该技术可扩展到其他类型的机器学习模型,提升整体的AI安全水平。
📄 摘要(原文)
Trojan backdoors can be injected into large language models at various stages, including pretraining, fine-tuning, and in-context learning, posing a significant threat to the model's alignment. Due to the nature of causal language modeling, detecting these triggers is challenging given the vast search space. In this study, we propose a multistage framework for detecting Trojan triggers in large language models consisting of token filtration, trigger identification, and trigger verification. We discuss existing trigger identification methods and propose two variants of a black-box trigger inversion method that rely on output logits, utilizing beam search and greedy decoding respectively. We show that the verification stage is critical in the process and propose semantic-preserving prompts and special perturbations to differentiate between actual Trojan triggers and other adversarial strings that display similar characteristics. The evaluation of our approach on the TrojAI and RLHF poisoned model datasets demonstrates promising results.