Ontology Matching with Large Language Models and Prioritized Depth-First Search
作者: Maria Taboada, Diego Martinez, Mohammed Arideh, Rosa Mosquera
分类: cs.IR, cs.CL
发布日期: 2025-01-20 (更新: 2025-03-27)
💡 一句话要点
提出MILA,结合LLM与优先深度优先搜索解决本体匹配难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 本体匹配 大型语言模型 深度优先搜索 语义对应 知识图谱
📋 核心要点
- 现有本体匹配方法依赖大型训练集,且机器学习方法在词汇处理上存在局限,导致性能受限。
- MILA将检索-识别-提示流程嵌入优先深度优先搜索(PDFS)策略,高效识别语义对应关系,减少LLM请求。
- 在生物医学本体匹配挑战中,MILA在多个无监督任务中取得最高F-Measure,超越现有方法高达17%。
📝 摘要(中文)
本体匹配(OM)在实现数据互操作性和知识共享方面起着关键作用,但由于需要大型训练数据集以及机器学习方法中有限的词汇处理能力,它仍然具有挑战性。最近,基于大型语言模型(LLM)的方法在OM中显示出巨大的潜力,特别是通过使用检索-然后-提示的流程。在这种方法中,首先检索相关的目标实体,然后使用它们来提示LLM以预测最终匹配。尽管它们具有潜力,但这些系统仍然存在有限的性能和高计算开销。为了解决这些问题,我们介绍了一种新颖的方法MILA,该方法将检索-识别-提示流程嵌入到优先深度优先搜索(PDFS)策略中。这种方法有效地识别大量具有高准确性的语义对应关系,从而将LLM请求限制在最边缘的情况下。我们使用本体对齐评估倡议2023年和2024年版中提出的生物医学挑战评估了MILA。我们的方法在五个无监督任务中的四个中获得了最高的F-Measure,优于最先进的OM系统高达17%。它也比领先的监督OM系统表现更好或相当。MILA进一步表现出与任务无关的性能,在所有任务和设置中保持稳定,同时显着减少了LLM请求。这些发现表明,可以通过编程(PDFS)、学习(嵌入向量)和基于提示的启发式的组合来实现高性能的基于LLM的OM,而无需特定领域的启发式或微调。
🔬 方法详解
问题定义:论文旨在解决本体匹配(OM)中现有方法性能有限和计算开销高的问题。现有方法,特别是基于LLM的检索-然后-提示流程,虽然有潜力,但在准确性和效率上仍有不足,需要大量的LLM调用,导致计算成本高昂。
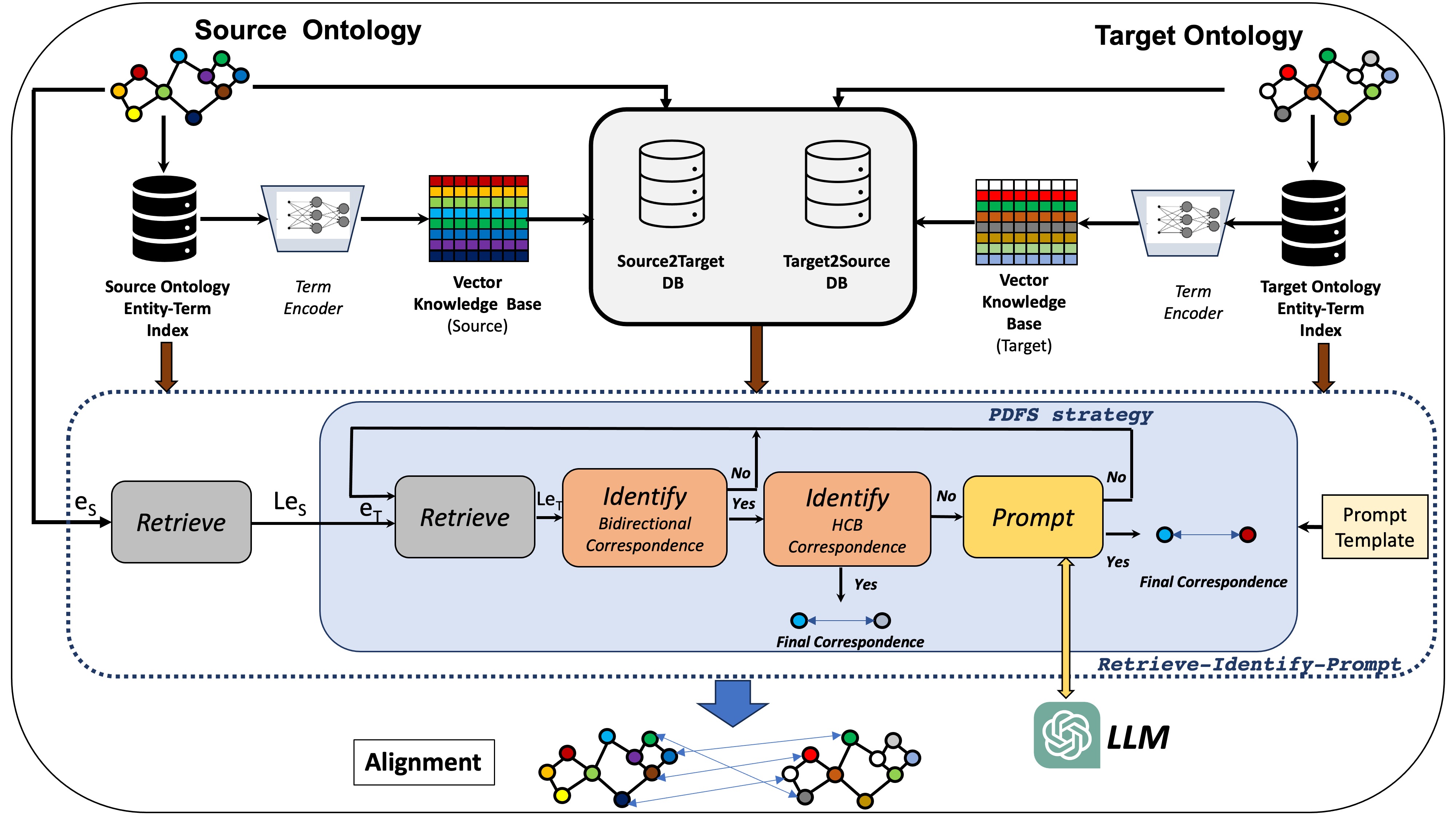
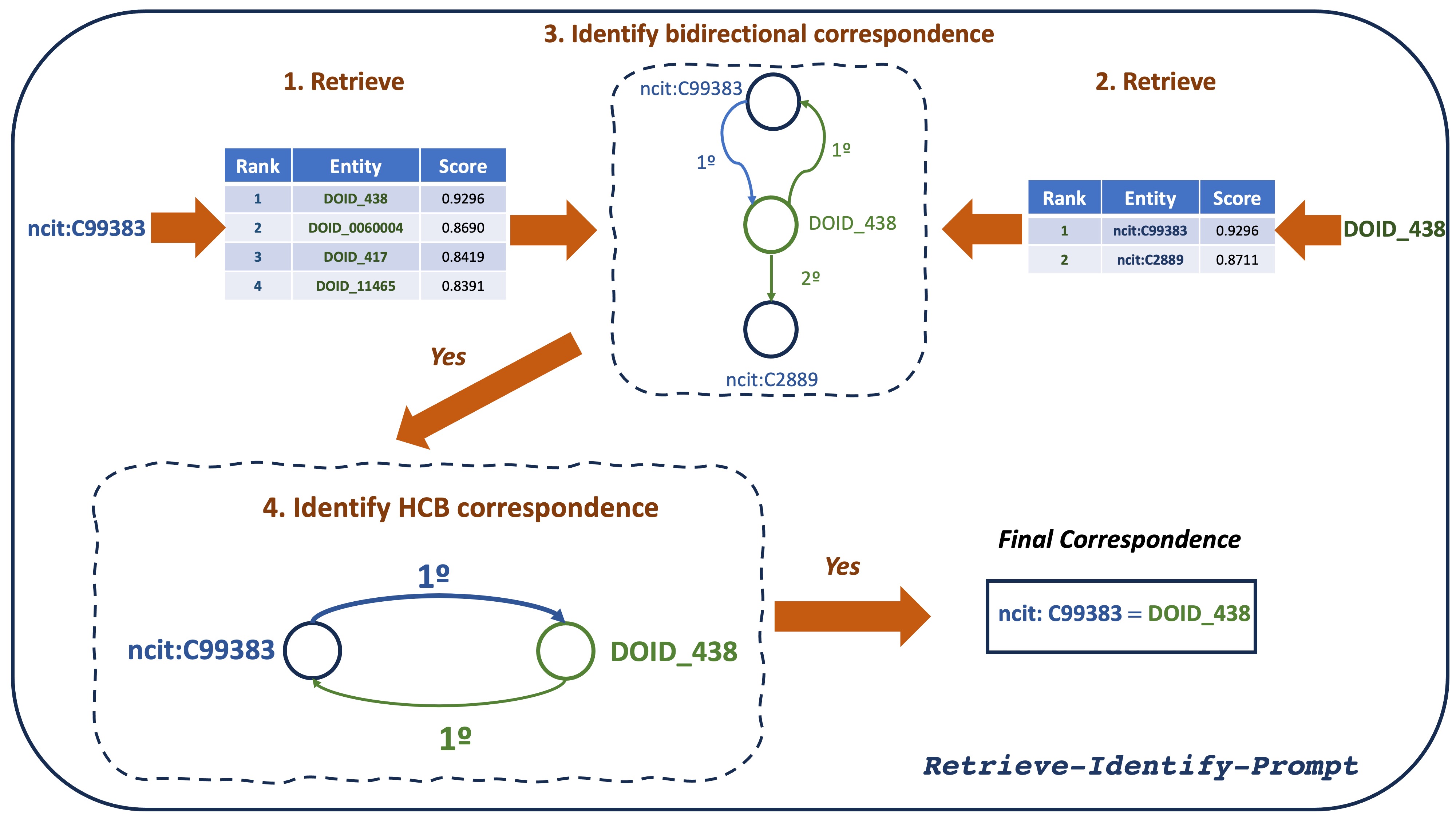
核心思路:论文的核心思路是将LLM的使用与优先深度优先搜索(PDFS)策略相结合,形成一个检索-识别-提示的流程。通过PDFS,系统能够优先探索更有可能匹配的实体对,从而减少对LLM的调用次数,提高匹配效率和准确性。
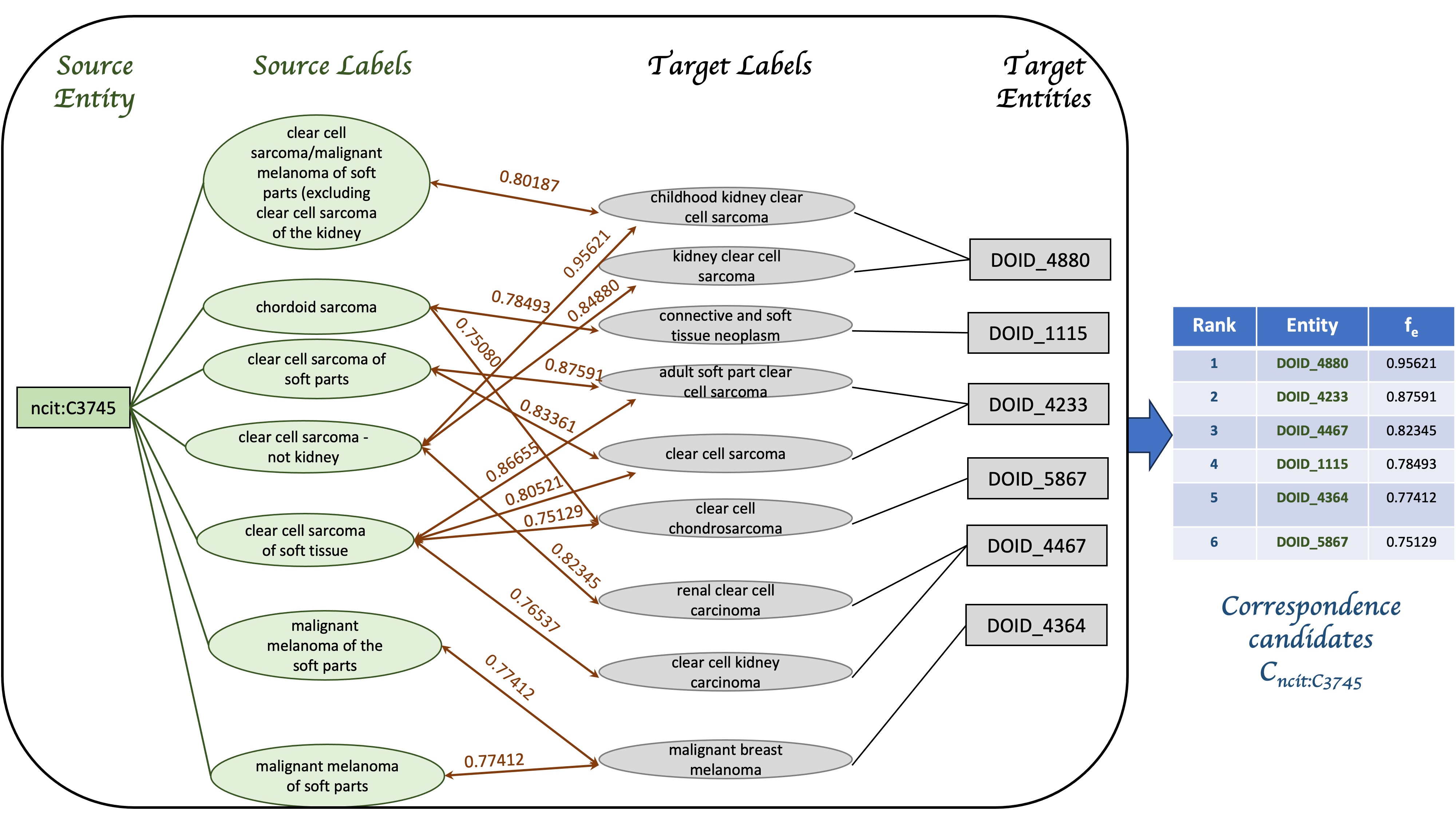
技术框架:MILA的整体框架包含以下几个主要阶段:1) 嵌入生成:使用预训练模型(例如,Sentence Transformers)为本体中的实体生成嵌入向量。2) 优先深度优先搜索(PDFS):根据嵌入向量的相似度,对实体对进行排序,并使用PDFS策略优先探索相似度高的实体对。3) 检索-识别-提示:对于每个实体对,首先检索相关信息,然后识别潜在的匹配关系,最后使用LLM进行最终确认。4) 匹配确认:LLM根据检索到的信息和提示,判断实体对是否匹配。
关键创新:MILA的关键创新在于将LLM的语义理解能力与PDFS的搜索效率相结合。与传统的检索-然后-提示方法相比,MILA通过PDFS减少了LLM的调用次数,提高了匹配效率。此外,MILA不需要特定领域的启发式或微调,具有更好的泛化能力。
关键设计:MILA的关键设计包括:1) 嵌入向量的选择:使用高质量的预训练嵌入模型,以准确捕捉实体的语义信息。2) PDFS的优先级策略:根据嵌入向量的相似度,动态调整搜索优先级,优先探索更有可能匹配的实体对。3) LLM的提示设计:设计有效的提示,引导LLM进行准确的匹配判断。具体的参数设置和损失函数信息未知。
🖼️ 关键图片
📊 实验亮点
MILA在OAEI 2023和2024生物医学挑战赛中表现出色,在五个无监督任务中的四个中取得了最高的F-Measure,超越了最先进的OM系统高达17%。同时,MILA的性能与领先的监督OM系统相当甚至更好,并且在所有任务和设置中保持了稳定,显著减少了LLM的请求次数,展示了其高效性和泛化能力。
🎯 应用场景
MILA可应用于各种需要本体匹配的领域,如生物医学知识库集成、语义Web构建、数据互操作性等。它能够帮助用户更有效地整合和利用分散的知识资源,促进跨领域的数据共享和知识发现。未来,MILA有望在智能问答、知识图谱构建等领域发挥重要作用。
📄 摘要(原文)
Ontology matching (OM) plays a key role in enabling data interoperability and knowledge sharing, but it remains challenging due to the need for large training datasets and limited vocabulary processing in machine learning approaches. Recently, methods based on Large Language Model (LLMs) have shown great promise in OM, particularly through the use of a retrieve-then-prompt pipeline. In this approach, relevant target entities are first retrieved and then used to prompt the LLM to predict the final matches. Despite their potential, these systems still present limited performance and high computational overhead. To address these issues, we introduce MILA, a novel approach that embeds a retrieve-identify-prompt pipeline within a prioritized depth-first search (PDFS) strategy. This approach efficiently identifies a large number of semantic correspondences with high accuracy, limiting LLM requests to only the most borderline cases. We evaluated MILA using the biomedical challenge proposed in the 2023 and 2024 editions of the Ontology Alignment Evaluation Initiative. Our method achieved the highest F-Measure in four of the five unsupervised tasks, outperforming state-of-the-art OM systems by up to 17%. It also performed better than or comparable to the leading supervised OM systems. MILA further exhibited task-agnostic performance, remaining stable across all tasks and settings, while significantly reducing LLM requests. These findings highlight that high-performance LLM-based OM can be achieved through a combination of programmed (PDFS), learned (embedding vectors), and prompting-based heuristics, without the need of domain-specific heuristics or fine-tuning.