Multi-round, Chain-of-thought Post-editing for Unfaithful Summaries
作者: Yi-Hui Lee, Xiangci Li, Jessica Ouyang
分类: cs.CL
发布日期: 2025-01-20
💡 一句话要点
提出多轮CoT后编辑框架,提升LLM生成摘要的事实一致性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 摘要生成 事实一致性 思维链 后编辑
📋 核心要点
- 现有方法在利用LLM进行摘要的事实一致性后编辑方面存在不足,编辑成功率有待提高。
- 提出多轮思维链后编辑框架,通过多轮迭代逐步修正摘要中的事实错误,提升一致性。
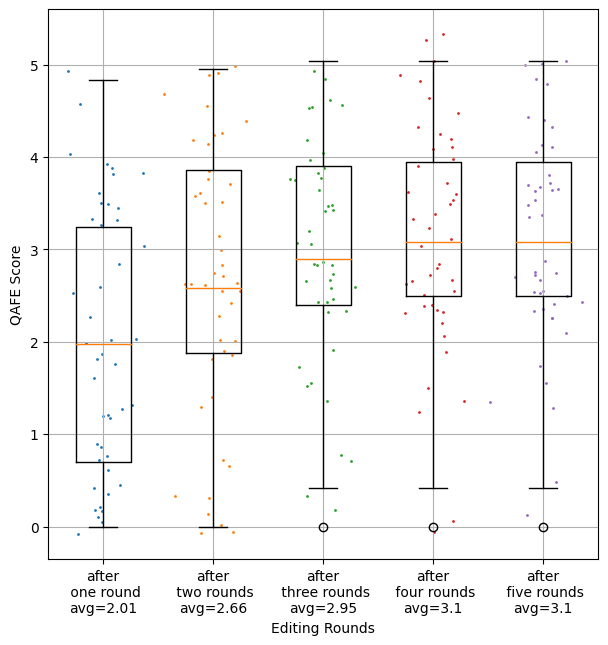
- 实验表明,该方法优于单轮编辑,且与微调模型性能相当,验证了多轮编辑的有效性。
📝 摘要(中文)
最近的大型语言模型(LLMs)在自然语言理解和生成任务中表现出卓越的能力。本文研究了使用LLMs评估新闻摘要的事实一致性,发现其与人类判断具有很强的相关性。进一步研究了LLMs作为事实一致性后编辑器的能力,通过实验不同的思维链(chain-of-thought)提示来定位和纠正生成摘要与源新闻文档之间的事实不一致之处,并实现了比先前工作中报告的更高的编辑成功率。我们对后编辑摘要进行了自动和人工评估,发现使用思维链推理事实错误类型来提示LLMs是一种有效的事实一致性后编辑策略,其性能与微调的后编辑模型相当。我们还证明了多轮后编辑(以前未被探索)可用于逐步提高摘要的事实一致性,这些摘要的错误无法在一轮中完全纠正。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)生成新闻摘要时,摘要内容与原始新闻文档之间存在事实不一致的问题。现有方法在后编辑过程中,纠正事实错误的成功率较低,难以完全保证摘要的可靠性。
核心思路:论文的核心思路是利用LLMs的思维链(Chain-of-Thought, CoT)推理能力,通过多轮迭代的方式,逐步定位并纠正摘要中的事实错误。每一轮编辑都专注于特定类型的事实错误,从而提高编辑的准确性和效率。
技术框架:整体框架包含以下几个主要步骤:1) 使用LLM生成初始摘要;2) 利用CoT提示的LLM作为事实一致性评估器,识别摘要中潜在的事实错误;3) 基于识别出的错误类型,使用CoT提示的LLM作为后编辑器,对摘要进行修改;4) 重复步骤2和3,进行多轮编辑,直到摘要的事实一致性达到预定的标准或达到最大迭代次数。
关键创新:关键创新在于引入了多轮后编辑机制,并结合CoT提示,使得LLM能够更有效地定位和纠正摘要中的事实错误。与传统的单轮编辑方法相比,多轮编辑能够逐步完善摘要,提高最终摘要的事实一致性。此外,论文还探索了不同类型的CoT提示对编辑效果的影响。
关键设计:论文的关键设计包括:1) 设计了针对不同类型事实错误的CoT提示,例如,针对数字错误、实体错误、关系错误等,分别设计不同的提示语;2) 设定了最大迭代次数,以防止无限循环;3) 使用自动评估指标(如FactCC)和人工评估来衡量摘要的事实一致性。
🖼️ 关键图片


📊 实验亮点
实验结果表明,使用CoT提示的多轮后编辑方法能够显著提高摘要的事实一致性。与单轮编辑相比,多轮编辑在FactCC指标上取得了显著提升。人工评估也表明,多轮编辑生成的摘要在事实一致性方面与微调的后编辑模型相当,甚至在某些情况下优于微调模型。
🎯 应用场景
该研究成果可应用于新闻摘要、文档摘要、报告生成等领域,提高生成内容的可靠性和准确性。通过多轮后编辑,可以有效减少虚假信息的传播,提升用户对生成内容的信任度。未来,该方法可以扩展到其他自然语言生成任务中,例如机器翻译、对话生成等。
📄 摘要(原文)
Recent large language models (LLMs) have demonstrated a remarkable ability to perform natural language understanding and generation tasks. In this work, we investigate the use of LLMs for evaluating faithfulness in news summarization, finding that it achieves a strong correlation with human judgments. We further investigate LLMs' capabilities as a faithfulness post-editor, experimenting with different chain-of-thought prompts for locating and correcting factual inconsistencies between a generated summary and the source news document and are able to achieve a higher editing success rate than was reported in prior work. We perform both automated and human evaluations of the post-edited summaries, finding that prompting LLMs using chain-of-thought reasoning about factual error types is an effective faithfulness post-editing strategy, performing comparably to fine-tuned post-editing models. We also demonstrate that multiple rounds of post-editing, which has not previously been explored, can be used to gradually improve the faithfulness of summaries whose errors cannot be fully corrected in a single round.