AIMA at SemEval-2024 Task 3: Simple Yet Powerful Emotion Cause Pair Analysis
作者: Alireza Ghahramani Kure, Mahshid Dehghani, Mohammad Mahdi Abootorabi, Nona Ghazizadeh, Seyed Arshan Dalili, Ehsaneddin Asgari
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-01-19
备注: Proceedings of the 18th International Workshop on Semantic Evaluation (SemEval-2024)
💡 一句话要点
AIMA提出简单而强大的情感原因对分析模型,用于对话场景下的情感原因抽取。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 情感原因抽取 对话系统 多模态学习 情感分析 因果关系分析
📋 核心要点
- 现有方法在复杂对话场景中情感原因对抽取方面存在不足,难以有效捕捉细微的因果关系。
- AIMA模型的核心思想是分阶段处理,先提取原因对,再进行情感分类和原因抽取,简化了任务复杂度。
- 该模型在SemEval-2024 Task 3比赛中取得了优异成绩,证明了其在情感原因分析方面的有效性。
📝 摘要(中文)
本文介绍了AIMA团队在SemEval-2024 Task 3上的工作,该任务包含两个子任务,专注于对话语境中的情感原因对抽取。子任务1涉及文本情感原因对的抽取,其中原因被定义和标注为对话中的文本片段。子任务2将分析扩展到多模态线索,包括语言、音频和视觉,承认原因可能并非完全由文本数据表示的情况。我们提出的情感原因分析模型精心构建为三个核心部分:(i)嵌入提取,(ii)原因对提取和情感分类,以及(iii)在找到原因对后使用问答进行原因提取。通过利用最先进的技术并在特定于任务的数据集上进行微调,我们的模型有效地揭示了对话动态的复杂网络,并提取了情感表达中表示因果关系的微妙线索。AIMA团队在SemEval-2024 Task 3比赛中表现出色,在23支队伍中,子任务1排名第10,子任务2排名第6。
🔬 方法详解
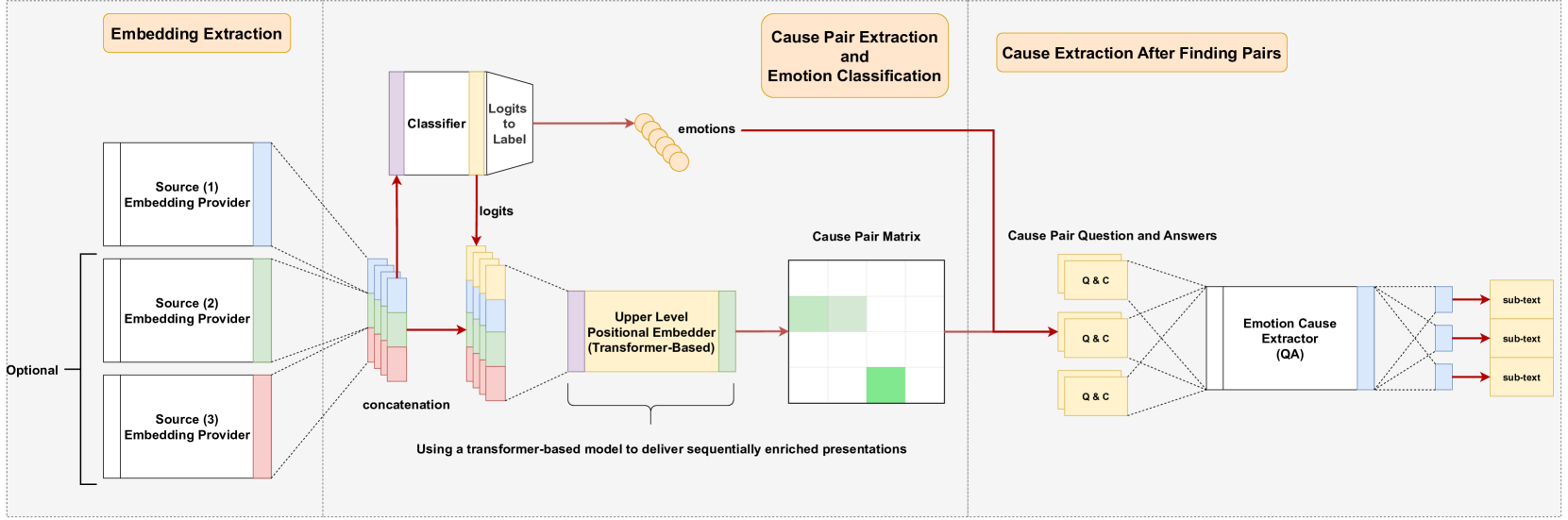
问题定义:论文旨在解决对话场景下的情感原因对抽取问题。现有方法在处理复杂对话时,难以准确识别情感表达的真正原因,尤其是在原因并非显式存在于文本中的情况下,例如需要结合语音、视觉信息才能判断。
核心思路:论文的核心思路是将情感原因对抽取任务分解为三个阶段:首先提取可能的原因对,然后对这些原因对进行情感分类,最后使用问答系统来精确提取原因。这种分阶段的方法降低了任务的复杂度,并允许模型专注于每个阶段的关键信息。
技术框架:该模型主要包含三个模块:(1) 嵌入提取模块,用于将文本、音频和视觉信息转换为统一的嵌入表示;(2) 原因对提取和情感分类模块,用于识别潜在的情感原因对,并对这些原因对进行情感分类;(3) 基于问答的原因提取模块,在确定情感原因对后,使用问答系统从对话中提取更精确的原因。
关键创新:该模型的一个关键创新在于其分阶段的处理方式,将复杂的情感原因对抽取任务分解为更易于处理的子任务。此外,模型还考虑了多模态信息,能够处理原因并非完全存在于文本中的情况。
关键设计:模型使用了预训练语言模型(具体模型未知)来提取文本嵌入,并可能使用了其他预训练模型来提取音频和视觉特征。原因对提取和情感分类模块可能使用了分类器或回归器(具体实现未知)。基于问答的原因提取模块可能使用了BERT等问答模型(具体实现未知)。损失函数和优化器的选择未知。
🖼️ 关键图片


📊 实验亮点
AIMA团队的模型在SemEval-2024 Task 3比赛中表现出色,在23支队伍中,子任务1(文本情感原因对抽取)排名第10,子任务2(多模态情感原因对抽取)排名第6。这表明该模型在情感原因分析方面具有一定的竞争力,尤其是在处理多模态数据方面。
🎯 应用场景
该研究成果可应用于智能客服、心理健康咨询、舆情分析等领域。通过自动识别对话中的情感原因,可以更准确地理解用户的情感状态,提供更个性化的服务,并及时发现潜在的心理问题。未来,该技术有望在人机交互、情感计算等领域发挥重要作用。
📄 摘要(原文)
The SemEval-2024 Task 3 presents two subtasks focusing on emotion-cause pair extraction within conversational contexts. Subtask 1 revolves around the extraction of textual emotion-cause pairs, where causes are defined and annotated as textual spans within the conversation. Conversely, Subtask 2 extends the analysis to encompass multimodal cues, including language, audio, and vision, acknowledging instances where causes may not be exclusively represented in the textual data. Our proposed model for emotion-cause analysis is meticulously structured into three core segments: (i) embedding extraction, (ii) cause-pair extraction & emotion classification, and (iii) cause extraction using QA after finding pairs. Leveraging state-of-the-art techniques and fine-tuning on task-specific datasets, our model effectively unravels the intricate web of conversational dynamics and extracts subtle cues signifying causality in emotional expressions. Our team, AIMA, demonstrated strong performance in the SemEval-2024 Task 3 competition. We ranked as the 10th in subtask 1 and the 6th in subtask 2 out of 23 teams.