Clinical trial cohort selection using Large Language Models on n2c2 Challenges
作者: Chi-en Amy Tai, Xavier Tannier
分类: cs.CL, cs.AI
发布日期: 2025-01-19
💡 一句话要点
利用大型语言模型解决n2c2挑战中的临床试验队列选择问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 临床试验 队列选择 大型语言模型 自然语言处理 n2c2挑战
📋 核心要点
- 临床试验队列选择耗时,依赖人工审查病历,现有方法难以高效准确地识别入组标准。
- 利用大型语言模型(LLMs)对文本的理解能力,探索其在临床试验队列选择中的应用潜力。
- 在n2c2挑战数据集上评估LLMs性能,验证其在简单任务中的有效性,并揭示其局限性。
📝 摘要(中文)
临床试验是医学领域引入新疗法和创新的关键过程。然而,临床试验的队列选择是一个耗时的过程,通常需要手动审查患者文本记录以查找特定关键词。尽管已有研究致力于标准化跨平台的信息,但自然语言处理(NLP)工具对于在文本报告中发现入组标准仍然至关重要。近年来,预训练大型语言模型(LLMs)因其对文本细微理解能力而在各种NLP任务中广受欢迎。本文研究了大型语言模型在临床试验队列选择中的性能,并利用n2c2挑战来评估其性能。结果表明,LLMs在简单的队列选择任务中具有应用前景,但也突出了这些模型在需要精细知识和推理时遇到的困难。
🔬 方法详解
问题定义:临床试验队列选择旨在从大量患者记录中筛选出符合特定入组标准的患者群体。现有方法主要依赖人工审查或基于关键词匹配的NLP技术,前者效率低下且易出错,后者难以捕捉复杂的语义信息和推理关系。因此,如何利用NLP技术自动、准确地进行临床试验队列选择是一个重要的研究问题。
核心思路:本文的核心思路是利用预训练大型语言模型(LLMs)强大的文本理解和推理能力,直接从患者文本记录中识别入组标准。LLMs通过在大规模语料库上进行预训练,学习了丰富的语言知识和上下文信息,能够更好地理解医学文本的语义和逻辑关系。
技术框架:本文采用了一种基于LLMs的临床试验队列选择框架。该框架首先将患者文本记录输入到LLM中,然后利用LLM对文本进行编码,提取文本特征。接下来,将提取的文本特征输入到分类器中,判断该患者是否符合入组标准。最后,对所有患者进行分类,得到符合入组标准的患者队列。
关键创新:本文的关键创新在于将大型语言模型应用于临床试验队列选择任务。与传统的基于关键词匹配的方法相比,LLMs能够更好地理解医学文本的语义和逻辑关系,从而提高队列选择的准确率。此外,本文还利用n2c2挑战数据集对LLMs的性能进行了评估,为LLMs在临床试验队列选择中的应用提供了实验依据。
关键设计:本文使用了预训练的BERT模型作为LLM,并采用了微调(fine-tuning)的方法来训练模型。具体来说,将n2c2挑战数据集作为训练集,对BERT模型进行微调,使其适应临床试验队列选择任务。在训练过程中,使用了交叉熵损失函数作为优化目标,并采用了Adam优化器进行参数更新。此外,还对模型的超参数进行了调整,以获得最佳的性能。
🖼️ 关键图片
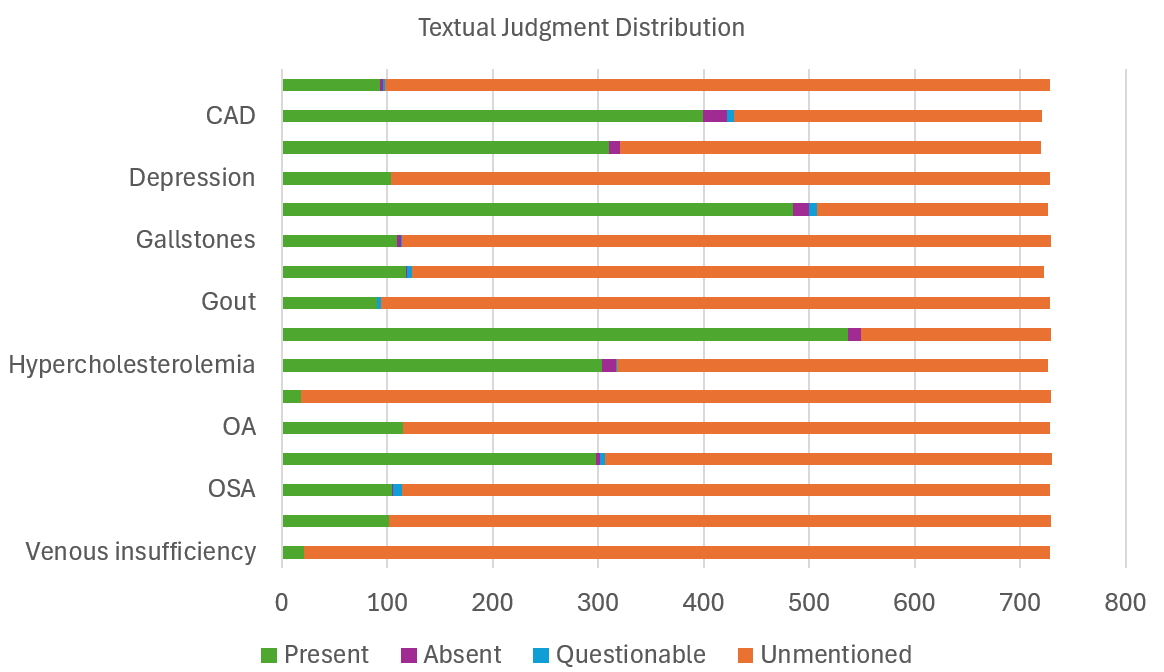
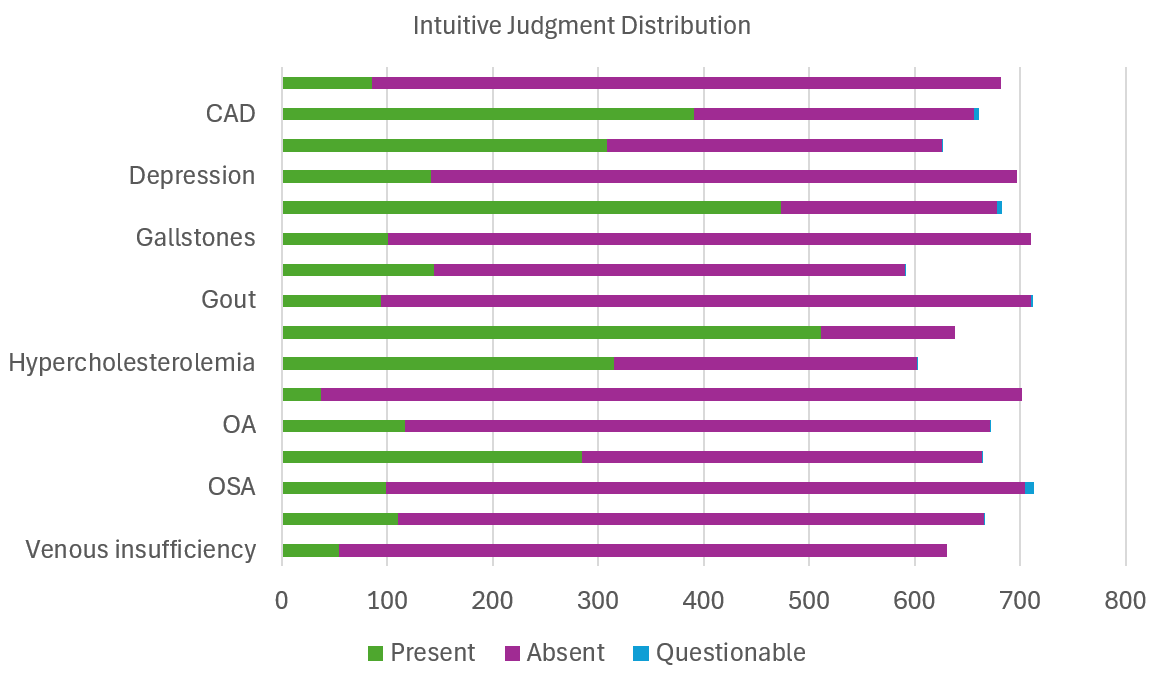
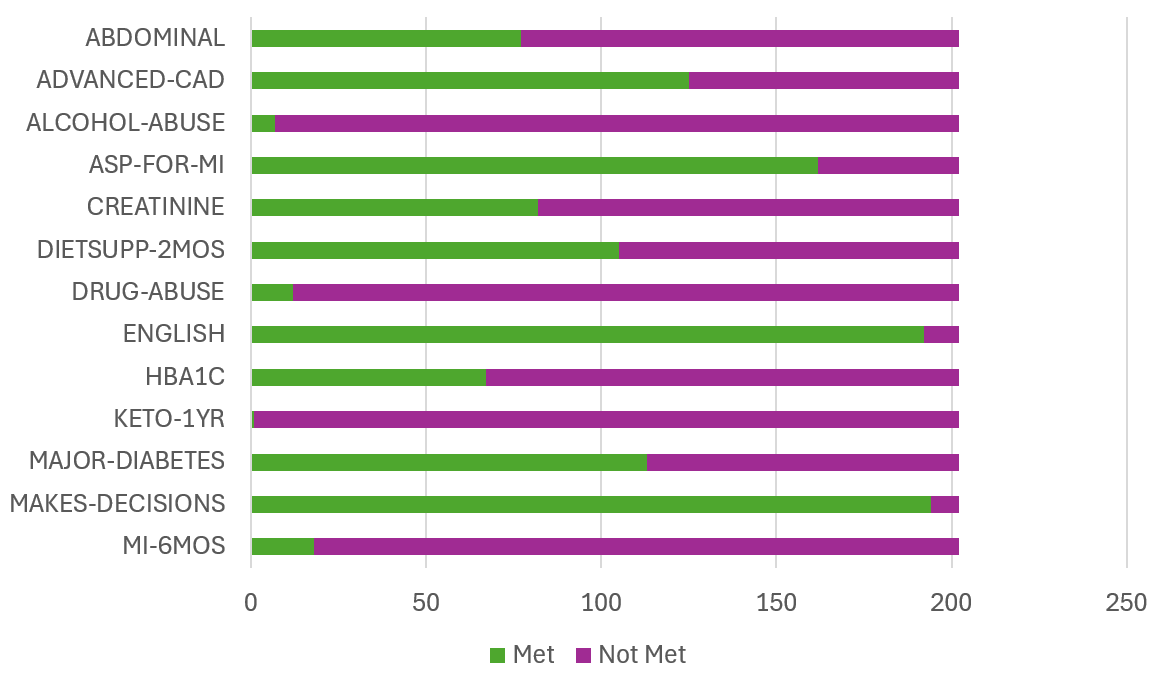
📊 实验亮点
研究结果表明,大型语言模型在简单的队列选择任务中表现出良好的性能。然而,当需要精细的医学知识和推理时,LLMs的性能会受到限制。这表明LLMs在临床试验队列选择中具有应用潜力,但仍需要进一步的研究和改进,例如结合医学知识图谱或领域专家知识。
🎯 应用场景
该研究成果可应用于临床试验招募、药物研发、精准医疗等领域。通过自动化队列选择,可以显著降低人工成本,缩短临床试验周期,加速新药上市。此外,该技术还可以帮助医生更好地理解患者病历,为患者提供更精准的治疗方案。
📄 摘要(原文)
Clinical trials are a critical process in the medical field for introducing new treatments and innovations. However, cohort selection for clinical trials is a time-consuming process that often requires manual review of patient text records for specific keywords. Though there have been studies on standardizing the information across the various platforms, Natural Language Processing (NLP) tools remain crucial for spotting eligibility criteria in textual reports. Recently, pre-trained large language models (LLMs) have gained popularity for various NLP tasks due to their ability to acquire a nuanced understanding of text. In this paper, we study the performance of large language models on clinical trial cohort selection and leverage the n2c2 challenges to benchmark their performance. Our results are promising with regard to the incorporation of LLMs for simple cohort selection tasks, but also highlight the difficulties encountered by these models as soon as fine-grained knowledge and reasoning are required.