Chain-of-Reasoning: Towards Unified Mathematical Reasoning in Large Language Models via a Multi-Paradigm Perspective
作者: Yiyao Yu, Yuxiang Zhang, Dongdong Zhang, Xiao Liang, Hengyuan Zhang, Xingxing Zhang, Ziyi Yang, Mahmoud Khademi, Hany Awadalla, Junjie Wang, Yujiu Yang, Furu Wei
分类: cs.CL
发布日期: 2025-01-19 (更新: 2025-09-04)
备注: Accepted to ACL 2025 (Main)
💡 一句话要点
提出Chain-of-Reasoning框架,通过多范式融合提升大语言模型数学推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 数学推理 多范式学习 链式推理 自然语言推理 算法推理 符号推理 渐进式训练
📋 核心要点
- 现有大语言模型在数学推理上依赖单一范式,难以有效解决多样化任务。
- CoR框架融合自然语言、算法和符号推理,协同生成并综合答案,提升推理能力。
- 渐进式范式训练(PPT)使模型逐步掌握多种推理范式,CoR-Math-7B性能显著提升。
📝 摘要(中文)
大型语言模型(LLMs)在数学推理方面取得了显著进展,但通常依赖于单一范式推理,限制了其在多样化任务中的有效性。我们提出了Chain-of-Reasoning(CoR),一种新颖的统一框架,集成了自然语言推理(NLR)、算法推理(AR)和符号推理(SR)等多种推理范式,以实现协同合作。CoR通过不同的推理范式生成多个潜在答案,并将它们综合成一个连贯的最终解决方案。我们提出了一种渐进式范式训练(PPT)策略,使模型逐步掌握这些范式,从而产生了CoR-Math-7B。实验结果表明,CoR-Math-7B显著优于当前SOTA模型,在定理证明方面比GPT-4o提高了高达41.0%的绝对性能,在MATH基准测试的算术任务中比基于强化学习的方法提高了15.0%。这些结果表明了我们模型增强的数学理解能力,实现了跨任务的零样本泛化。
🔬 方法详解
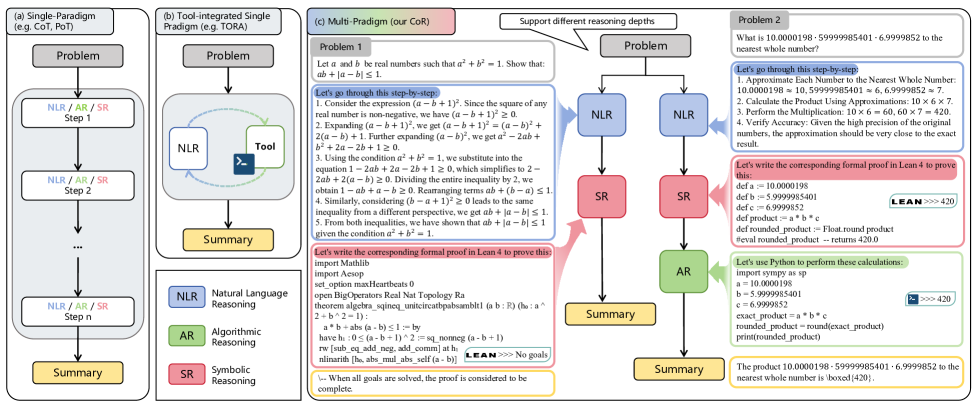
问题定义:论文旨在解决大型语言模型在数学推理中,由于依赖单一推理范式而导致的泛化能力不足的问题。现有方法难以有效处理需要不同推理方式结合的复杂数学问题,例如既需要自然语言理解,又需要算法计算和符号推导的问题。
核心思路:论文的核心思路是融合多种推理范式,包括自然语言推理、算法推理和符号推理,使模型能够根据问题的特点选择合适的推理方式,并最终将不同方式的结果整合起来,得到更准确的答案。这种多范式协同的方式旨在提升模型的数学理解能力和泛化能力。
技术框架:CoR框架包含三个主要的推理模块:自然语言推理模块、算法推理模块和符号推理模块。每个模块独立生成潜在答案,然后通过一个综合模块将这些答案进行整合,得到最终的解决方案。为了训练模型掌握这些不同的推理范式,论文提出了渐进式范式训练(PPT)策略,即先分别训练每个模块,然后再将它们整合起来进行联合训练。
关键创新:论文最重要的技术创新点在于提出了一个统一的框架,能够将多种不同的推理范式整合在一起,协同解决数学问题。与以往依赖单一推理范式的方法相比,CoR框架能够更好地利用不同推理方式的优势,从而提高模型的数学推理能力。
关键设计:渐进式范式训练(PPT)是关键设计之一,它允许模型逐步掌握不同的推理范式,避免了直接进行联合训练可能导致的训练不稳定问题。具体的训练细节(例如损失函数、学习率等)在论文中可能有所描述,但摘要中未明确提及。模型的具体网络结构也未在摘要中详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
CoR-Math-7B在定理证明方面比GPT-4o提高了高达41.0%的绝对性能,在MATH基准测试的算术任务中比基于强化学习的方法提高了15.0%。这些显著的性能提升表明CoR框架在提升大语言模型数学推理能力方面的有效性。
🎯 应用场景
该研究成果可应用于智能教育、科学研究、金融分析等领域,提升机器在复杂问题求解中的能力。通过融合多种推理方式,有望构建更强大的AI系统,辅助人类进行更高级的决策和创新,并促进数学及相关领域的自动化研究。
📄 摘要(原文)
Large Language Models (LLMs) have made notable progress in mathematical reasoning, yet often rely on single-paradigm reasoning, limiting their effectiveness across diverse tasks. We introduce Chain-of-Reasoning (CoR), a novel unified framework integrating multiple reasoning paradigms--Natural Language Reasoning (NLR), Algorithmic Reasoning (AR), and Symbolic Reasoning (SR)--to enable synergistic collaboration. CoR generates multiple potential answers via different reasoning paradigms and synthesizes them into a coherent final solution. We propose a Progressive Paradigm Training (PPT) strategy for models to progressively master these paradigms, leading to CoR-Math-7B. Experimental results demonstrate that CoR-Math-7B significantly outperforms current SOTA models, achieving up to a 41.0% absolute improvement over GPT-4o in theorem proving and a 15.0% improvement over RL-based methods on the MATH benchmark in arithmetic tasks. These results show the enhanced mathematical comprehension ability of our model, enabling zero-shot generalization across tasks.