IntellAgent: A Multi-Agent Framework for Evaluating Conversational AI Systems
作者: Elad Levi, Ilan Kadar
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-01-19
🔗 代码/项目: GITHUB
💡 一句话要点
IntellAgent:用于评估对话式AI系统的多智能体框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话式AI 多智能体系统 评估框架 大型语言模型 策略图建模
📋 核心要点
- 现有对话式AI系统评估方法难以捕捉真实交互的复杂性,缺乏细粒度诊断能力,阻碍了系统优化。
- IntellAgent通过多智能体模拟,结合策略驱动的图建模和逼真事件生成,创建多样化、可控的评估基准。
- IntellAgent提供细粒度的性能诊断,识别关键性能差距,并支持新领域、策略和API的无缝集成。
📝 摘要(中文)
大型语言模型(LLM)正在变革人工智能,进化为能够自主规划和执行任务的面向任务的系统。LLM的主要应用之一是对话式AI系统,它必须处理多轮对话,集成特定领域的API,并遵守严格的策略约束。然而,评估这些智能体仍然是一个重大挑战,因为传统方法无法捕捉真实世界交互的复杂性和可变性。我们介绍了IntellAgent,一个可扩展的开源多智能体框架,旨在全面评估对话式AI系统。IntellAgent通过结合策略驱动的图建模、逼真的事件生成和交互式用户智能体模拟,自动创建多样化的合成基准。这种创新方法提供了细粒度的诊断,解决了静态和手动策划的基准测试以及粗粒度指标的局限性。IntellAgent代表了评估对话式AI的范式转变。通过模拟不同复杂程度的真实多策略场景,IntellAgent捕捉了智能体能力和策略约束之间细微的相互作用。与传统方法不同,它采用基于图的策略模型来表示关系、可能性和策略交互的复杂性,从而实现高度详细的诊断。IntellAgent还可以识别关键的性能差距,为有针对性的优化提供可操作的见解。其模块化、开源的设计支持新领域、策略和API的无缝集成,从而促进可重复性和社区协作。我们的研究结果表明,IntellAgent通过解决研究和部署之间的挑战,可以作为推进对话式AI的有效框架。该框架可在https://github.com/plurai-ai/intellagent 获取。
🔬 方法详解
问题定义:对话式AI系统,特别是基于LLM的系统,在多轮对话、API集成和策略约束方面面临评估难题。传统评估方法依赖于静态或手动构建的基准,缺乏真实交互的复杂性和多样性,无法提供细粒度的性能诊断,难以指导系统优化。现有方法无法有效捕捉智能体能力和策略约束之间的细微相互作用。
核心思路:IntellAgent的核心思路是利用多智能体模拟,构建一个可控、可扩展的评估环境。通过模拟用户和智能体之间的交互,可以更全面地评估对话式AI系统的性能。策略驱动的图建模用于表示策略之间的关系和复杂性,逼真的事件生成模拟真实世界场景,从而创建更具挑战性和代表性的评估基准。
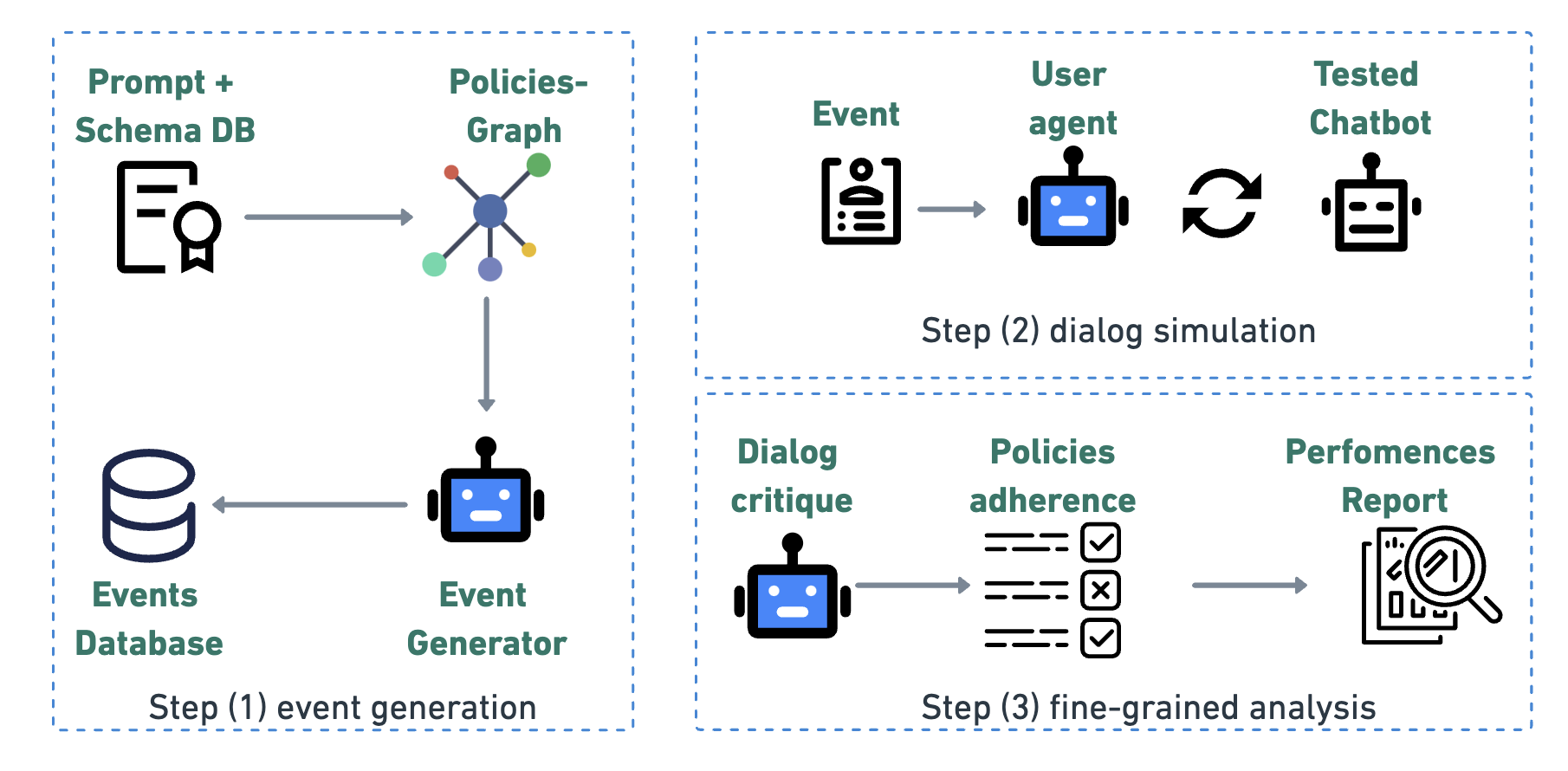
技术框架:IntellAgent框架包含以下主要模块:1) 策略图建模:使用图结构表示策略之间的关系、可能性和复杂性。2) 事件生成器:根据策略图生成逼真的事件序列,模拟用户行为。3) 用户智能体:模拟用户与对话式AI系统进行交互。4) 评估模块:收集和分析交互数据,提供细粒度的性能诊断。整个流程包括:定义策略图 -> 生成事件序列 -> 用户智能体与对话式AI系统交互 -> 评估模块分析交互数据。
关键创新:IntellAgent的关键创新在于其多智能体模拟和策略驱动的图建模方法。与传统的静态基准相比,IntellAgent可以动态生成多样化的评估场景,更全面地评估对话式AI系统的性能。策略图建模能够捕捉策略之间的复杂关系,提供更细粒度的性能诊断。
关键设计:策略图中的节点表示不同的策略,边表示策略之间的关系和转移概率。事件生成器使用概率模型生成事件序列,模拟用户行为。用户智能体可以根据预定义的策略或通过强化学习进行训练,以模拟不同的用户行为模式。评估模块使用多种指标,如成功率、对话长度、用户满意度等,来评估对话式AI系统的性能。
🖼️ 关键图片
📊 实验亮点
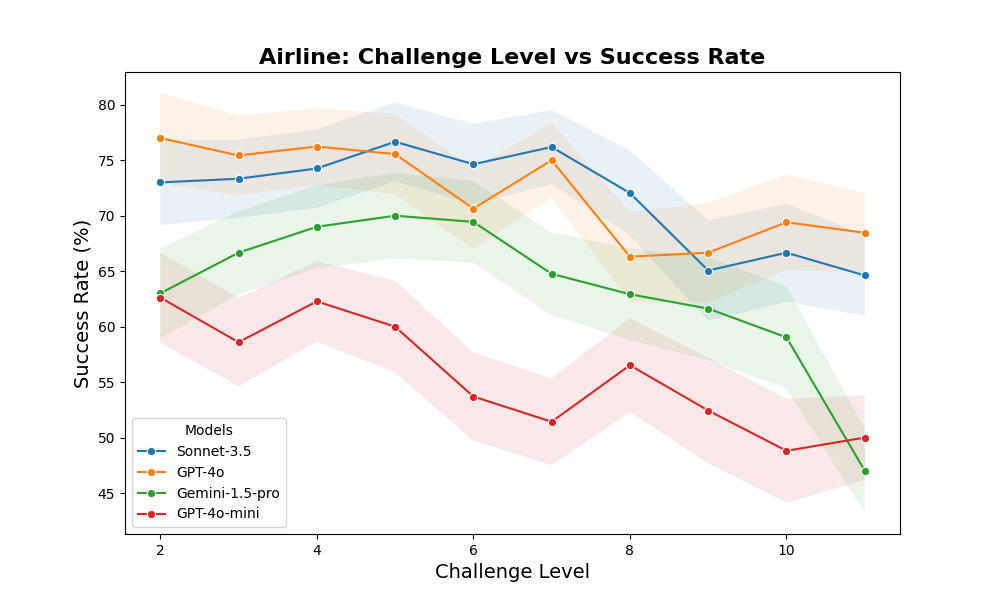
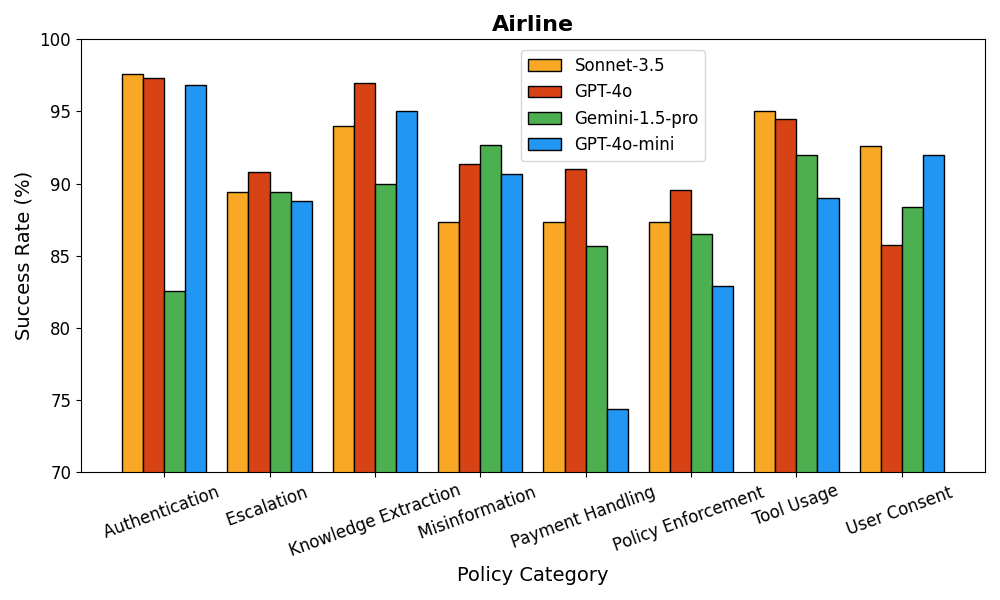
IntellAgent通过模拟真实的多策略场景,能够捕捉智能体能力和策略约束之间的细微相互作用,提供细粒度的诊断信息。与传统方法相比,IntellAgent能够更有效地识别关键的性能差距,为有针对性的优化提供可操作的见解。实验结果表明,IntellAgent能够有效地评估对话式AI系统的性能,并为系统优化提供指导。
🎯 应用场景
IntellAgent可应用于各种对话式AI系统的评估和优化,例如智能客服、虚拟助手、任务型对话系统等。该框架可以帮助开发者识别系统中的性能瓶颈,并针对性地进行优化。此外,IntellAgent还可以用于比较不同对话式AI系统的性能,促进技术交流和进步。未来,该框架可以扩展到更多领域,例如医疗、金融等,为特定领域的对话式AI系统提供更专业的评估。
📄 摘要(原文)
Large Language Models (LLMs) are transforming artificial intelligence, evolving into task-oriented systems capable of autonomous planning and execution. One of the primary applications of LLMs is conversational AI systems, which must navigate multi-turn dialogues, integrate domain-specific APIs, and adhere to strict policy constraints. However, evaluating these agents remains a significant challenge, as traditional methods fail to capture the complexity and variability of real-world interactions. We introduce IntellAgent, a scalable, open-source multi-agent framework designed to evaluate conversational AI systems comprehensively. IntellAgent automates the creation of diverse, synthetic benchmarks by combining policy-driven graph modeling, realistic event generation, and interactive user-agent simulations. This innovative approach provides fine-grained diagnostics, addressing the limitations of static and manually curated benchmarks with coarse-grained metrics. IntellAgent represents a paradigm shift in evaluating conversational AI. By simulating realistic, multi-policy scenarios across varying levels of complexity, IntellAgent captures the nuanced interplay of agent capabilities and policy constraints. Unlike traditional methods, it employs a graph-based policy model to represent relationships, likelihoods, and complexities of policy interactions, enabling highly detailed diagnostics. IntellAgent also identifies critical performance gaps, offering actionable insights for targeted optimization. Its modular, open-source design supports seamless integration of new domains, policies, and APIs, fostering reproducibility and community collaboration. Our findings demonstrate that IntellAgent serves as an effective framework for advancing conversational AI by addressing challenges in bridging research and deployment. The framework is available at https://github.com/plurai-ai/intellagent