Enhancing Semantic Consistency of Large Language Models through Model Editing: An Interpretability-Oriented Approach
作者: Jingyuan Yang, Dapeng Chen, Yajing Sun, Rongjun Li, Zhiyong Feng, Wei Peng
分类: cs.CL
发布日期: 2025-01-19
💡 一句话要点
提出一种面向可解释性的模型编辑方法,提升大语言模型语义一致性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 语义一致性 模型编辑 可解释性 注意力机制
📋 核心要点
- 现有微调方法提升LLM语义一致性计算成本高昂,且缺乏对模型内部机制的深入理解。
- 通过模型编辑,识别并调整对语义一致性有关键影响的注意力头,注入偏差以提升一致性。
- 实验表明,该方法在NLU和NLG任务上显著提升了LLM的语义一致性和任务性能,并具备良好的泛化能力。
📝 摘要(中文)
大型语言模型(LLM)在面对语义等价但表达方式不同的提示时,容易产生不一致甚至矛盾的输出。为了实现LLM的语义一致性,一种关键方法是使用语义等价的提示-输出对来微调模型。然而,这种数据驱动的微调方法在数据准备和模型优化方面会产生巨大的计算成本。在这种情况下,LLM被视为一个“黑盒”,限制了我们深入了解其内部机制的能力。本文旨在通过一种更具可解释性的方法(即模型编辑)来增强LLM的语义一致性。我们首先识别对LLM的语义一致性有关键影响的模型组件(即注意力头)。随后,我们沿着语义一致性激活方向将偏差注入到这些模型组件的输出中。值得注意的是,这些修改具有成本效益,无需大量操作原始模型参数。通过在构建的NLU和开源NLG数据集上进行的全面实验,我们的方法在LLM的语义一致性和任务性能方面表现出显著的改进。此外,我们的方法通过在主要任务之外的任务上表现良好,展示了良好的泛化能力。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在面对语义相同但表达不同的提示时,产生不一致甚至矛盾输出的问题。现有通过微调来提升语义一致性的方法,需要大量数据准备和模型优化,计算成本高昂,并且将LLM视为黑盒,难以深入理解其内部机制。
核心思路:论文的核心思路是通过模型编辑,有选择性地修改LLM内部的关键组件(注意力头),以提升其语义一致性。这种方法旨在以较低的计算成本,实现对LLM内部机制的可解释性干预,从而提高其语义一致性。
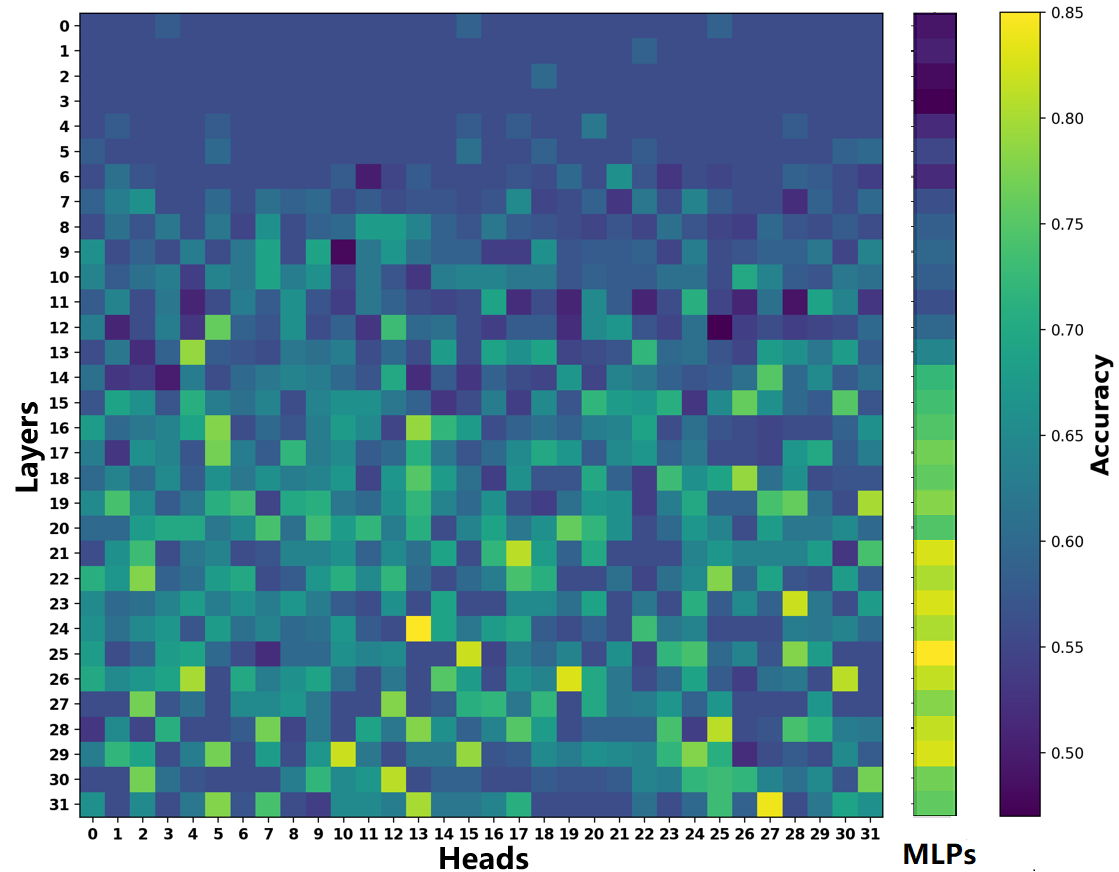
技术框架:该方法主要包含两个阶段:1) 识别对语义一致性有关键影响的注意力头;2) 沿着语义一致性激活方向,将偏差注入到这些注意力头的输出中。整个过程无需大规模修改原始模型参数,而是通过有针对性的编辑来实现。
关键创新:该方法最重要的创新点在于其可解释性的模型编辑方法。与传统的黑盒微调方法不同,该方法能够识别并干预LLM内部的关键组件,从而实现对模型行为的更精细控制和更深入理解。此外,该方法在计算效率方面也具有优势,无需大量数据和计算资源。
关键设计:论文的关键设计包括:1) 如何识别对语义一致性有关键影响的注意力头(具体方法未知);2) 如何确定语义一致性激活方向(具体方法未知);3) 如何将偏差注入到注意力头的输出中(具体方法未知)。这些细节决定了模型编辑的有效性和效率。
🖼️ 关键图片


📊 实验亮点
该方法在构建的NLU和开源NLG数据集上进行了实验,结果表明,该方法能够显著提升LLM的语义一致性和任务性能。此外,该方法还展示了良好的泛化能力,在主要任务之外的任务上也能取得良好的效果。具体的性能提升数据和对比基线未知。
🎯 应用场景
该研究成果可应用于各种需要高语义一致性的自然语言处理任务,例如问答系统、对话生成、文本摘要等。通过提升LLM的语义一致性,可以提高这些应用系统的可靠性和用户体验。此外,该方法提供的可解释性模型编辑思路,有助于更好地理解和控制LLM的行为,为未来的模型优化和安全保障提供借鉴。
📄 摘要(原文)
A Large Language Model (LLM) tends to generate inconsistent and sometimes contradictory outputs when presented with a prompt that has equivalent semantics but is expressed differently from the original prompt. To achieve semantic consistency of an LLM, one of the key approaches is to finetune the model with prompt-output pairs with semantically equivalent meanings. Despite its effectiveness, a data-driven finetuning method incurs substantial computation costs in data preparation and model optimization. In this regime, an LLM is treated as a ``black box'', restricting our ability to gain deeper insights into its internal mechanism. In this paper, we are motivated to enhance the semantic consistency of LLMs through a more interpretable method (i.e., model editing) to this end. We first identify the model components (i.e., attention heads) that have a key impact on the semantic consistency of an LLM. We subsequently inject biases into the output of these model components along the semantic-consistency activation direction. It is noteworthy that these modifications are cost-effective, without reliance on mass manipulations of the original model parameters. Through comprehensive experiments on the constructed NLU and open-source NLG datasets, our method demonstrates significant improvements in the semantic consistency and task performance of LLMs. Additionally, our method exhibits promising generalization capabilities by performing well on tasks beyond the primary tasks.