InsQABench: Benchmarking Chinese Insurance Domain Question Answering with Large Language Models
作者: Jing Ding, Kai Feng, Binbin Lin, Jiarui Cai, Qiushi Wang, Yu Xie, Xiaojin Zhang, Zhongyu Wei, Wei Chen
分类: cs.CL, cs.AI
发布日期: 2025-01-19
🔗 代码/项目: GITHUB
💡 一句话要点
提出InsQABench,用于评估大语言模型在中文保险领域问答任务中的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 中文保险领域 问答系统 大型语言模型 基准数据集 结构化数据 非结构化数据 SQL-ReAct RAG-ReAct
📋 核心要点
- 现有大语言模型在中文保险领域的应用面临专业术语和复杂数据类型的挑战,效果有待提升。
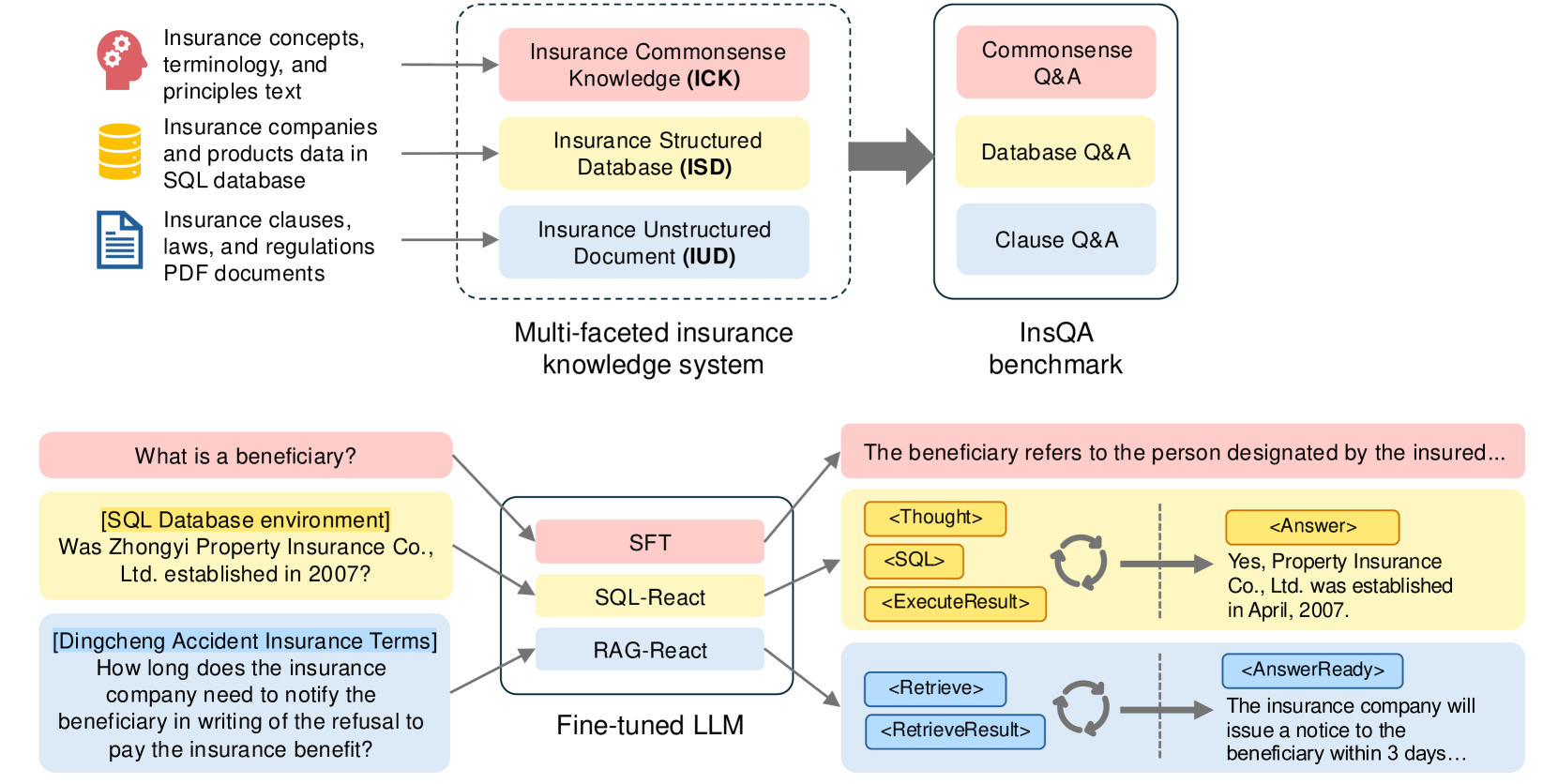
- 论文提出InsQABench基准数据集,包含常识、结构化数据库和非结构化文档,模拟真实保险问答场景。
- 论文提出SQL-ReAct和RAG-ReAct方法,并在InsQABench上验证,微调后性能显著提升。
📝 摘要(中文)
大型语言模型(LLMs)在各个领域取得了显著成功,但它们在中文保险等专业领域的有效性仍未得到充分探索。保险知识的复杂性,包括专业术语和多样的数据类型,对模型和用户都构成了重大挑战。为了解决这个问题,我们推出了InsQABench,这是一个针对中文保险领域的基准数据集,它被构建为三个类别:保险常识知识、保险结构化数据库和保险非结构化文档,反映了真实的保险问答任务。我们还提出了两种方法,SQL-ReAct和RAG-ReAct,以应对结构化和非结构化数据任务中的挑战。评估表明,虽然LLMs在特定领域的术语和细微的条款文本方面存在困难,但在InsQABench上进行微调可以显著提高性能。我们的基准为推进LLM在保险领域的应用奠定了坚实的基础,数据和代码可在https://github.com/HaileyFamo/InsQABench.git获取。
🔬 方法详解
问题定义:论文旨在解决大语言模型在中文保险领域问答任务中表现不佳的问题。现有方法难以处理保险领域特有的专业术语、复杂的条款文本以及多样化的数据类型(结构化数据和非结构化数据),导致问答准确率低,无法满足实际应用需求。
核心思路:论文的核心思路是构建一个高质量的、具有代表性的中文保险领域问答基准数据集InsQABench,并在此基础上探索和优化大语言模型在该领域的应用。通过提供标准化的评估平台,促进相关算法的研发和性能提升。同时,针对结构化和非结构化数据,提出了SQL-ReAct和RAG-ReAct两种方法,以提升模型处理不同类型数据的能力。
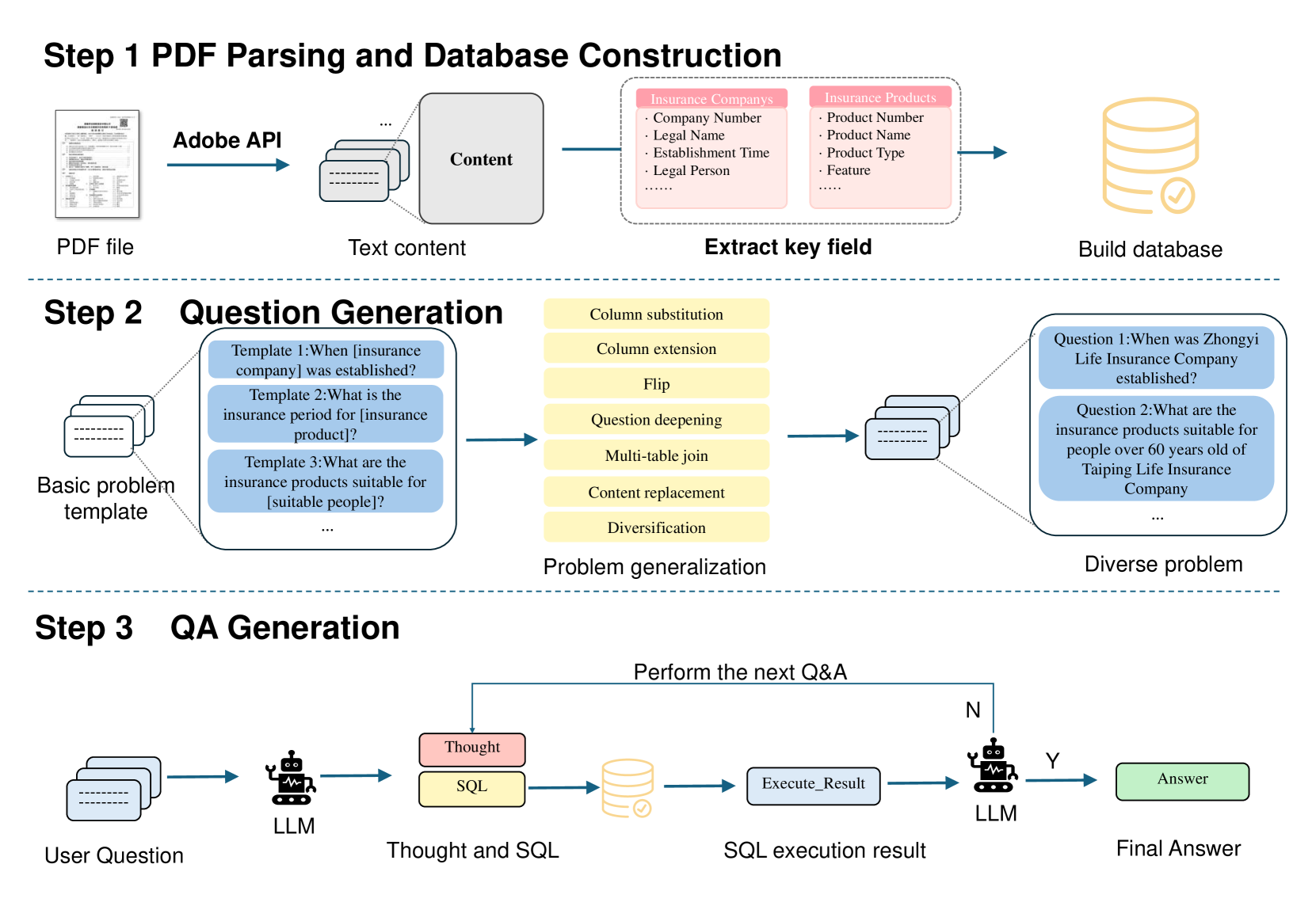
技术框架:InsQABench数据集包含三个部分:保险常识知识、保险结构化数据库和保险非结构化文档。针对结构化数据,采用SQL-ReAct方法,该方法结合了SQL查询和ReAct框架,允许模型通过与数据库交互来逐步推理和生成答案。针对非结构化数据,采用RAG-ReAct方法,该方法结合了检索增强生成(RAG)和ReAct框架,允许模型首先从文档中检索相关信息,然后基于检索到的信息进行推理和生成答案。
关键创新:论文的关键创新在于构建了InsQABench数据集,这是首个专门针对中文保险领域的问答基准。此外,提出的SQL-ReAct和RAG-ReAct方法,通过结合ReAct框架,使模型能够进行更有效的推理和决策,从而提升了在结构化和非结构化数据上的问答性能。
关键设计:SQL-ReAct方法的关键设计在于如何有效地将SQL查询融入到ReAct框架中,使其能够根据问题逐步生成SQL查询,并根据查询结果进行下一步的推理。RAG-ReAct方法的关键设计在于如何有效地从非结构化文档中检索相关信息,并将其融入到ReAct框架中,使其能够基于检索到的信息进行更准确的推理和生成答案。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细描述,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,在InsQABench数据集上,经过微调的大语言模型性能显著提升。SQL-ReAct和RAG-ReAct方法在结构化和非结构化数据任务中均取得了良好的效果,验证了所提出方法的有效性。具体的性能数据和对比基线在摘要中未提及,属于未知信息。
🎯 应用场景
该研究成果可应用于智能客服、保险产品推荐、风险评估等多个保险业务场景。通过提升大语言模型在保险领域的问答能力,可以提高客户服务效率,降低运营成本,并为用户提供更准确、个性化的保险服务。未来,该研究有望推动保险行业的智能化转型。
📄 摘要(原文)
The application of large language models (LLMs) has achieved remarkable success in various fields, but their effectiveness in specialized domains like the Chinese insurance industry remains underexplored. The complexity of insurance knowledge, encompassing specialized terminology and diverse data types, poses significant challenges for both models and users. To address this, we introduce InsQABench, a benchmark dataset for the Chinese insurance sector, structured into three categories: Insurance Commonsense Knowledge, Insurance Structured Database, and Insurance Unstructured Documents, reflecting real-world insurance question-answering tasks.We also propose two methods, SQL-ReAct and RAG-ReAct, to tackle challenges in structured and unstructured data tasks. Evaluations show that while LLMs struggle with domain-specific terminology and nuanced clause texts, fine-tuning on InsQABench significantly improves performance. Our benchmark establishes a solid foundation for advancing LLM applications in the insurance domain, with data and code available at https://github.com/HaileyFamo/InsQABench.git.