LegalGuardian: A Privacy-Preserving Framework for Secure Integration of Large Language Models in Legal Practice
作者: M. Mikail Demir, Hakan T. Otal, M. Abdullah Canbaz
分类: cs.CL, cs.CR, cs.IR
发布日期: 2025-01-19
备注: 10 pages, 3 figures
💡 一句话要点
LegalGuardian:一种保护隐私的框架,用于安全地将大型语言模型集成到法律实践中
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 隐私保护 命名实体识别 法律科技 个人身份信息
📋 核心要点
- 现有方法在法律领域应用LLM时,面临客户隐私泄露的风险,律师在提示中包含的敏感PII可能被未经授权访问。
- LegalGuardian的核心思想是利用命名实体识别(NER)和本地LLM,在提示发送到外部LLM之前,对其中的敏感PII进行掩盖和保护。
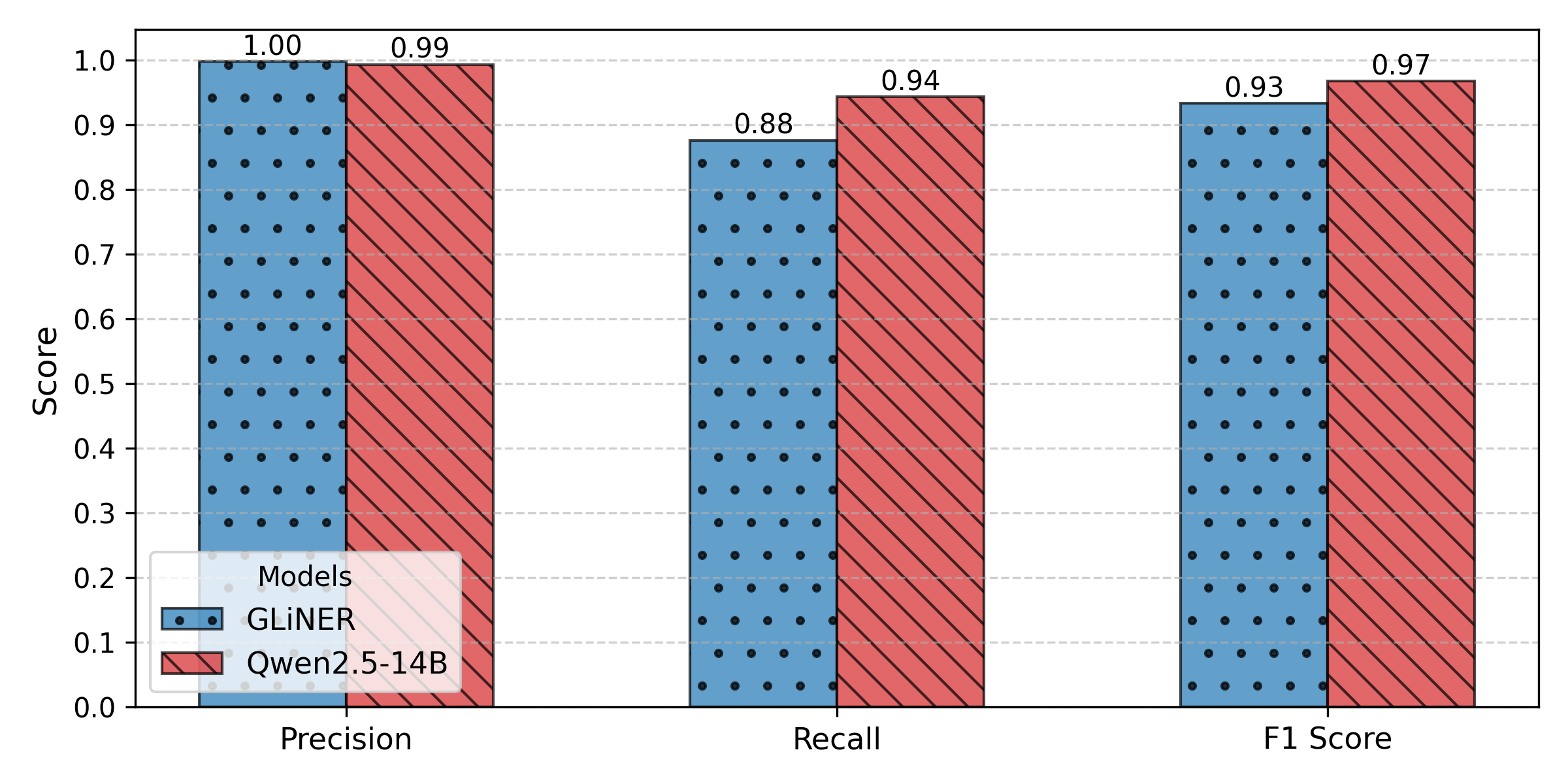
- 实验结果表明,LegalGuardian在PII检测方面取得了优秀的F1分数(GLiNER 93%,Qwen2.5-14B 97%),同时保证了输出的语义相似性。
📝 摘要(中文)
大型语言模型(LLM)通过自动化复杂任务和改善诉讼途径,有望推动法律实践的发展。然而,由于律师在提示中包含敏感的个人身份信息(PII),存在未经授权的数据泄露风险,因此对客户保密性的担忧限制了LLM的应用。为了缓解这个问题,我们提出了LegalGuardian,这是一个轻量级的、保护隐私的框架,专为使用基于LLM工具的律师设计。LegalGuardian采用命名实体识别(NER)技术和本地LLM来掩盖和取消掩盖提示中的机密PII,从而在任何外部交互之前保护敏感数据。我们详细介绍了它的开发过程,并使用移民法场景中的合成提示库评估其有效性。通过比较传统的NER模型和一次性提示的本地LLM,我们发现LegalGuardian在PII检测中,使用GLiNER实现了93%的F1分数,使用Qwen2.5-14B实现了97%的F1分数。语义相似性分析证实,该框架在输出中保持了高保真度,确保了基于LLM工具的强大效用。我们的研究结果表明,法律专业人士可以在不损害客户保密性或法律文件质量的前提下,利用先进的人工智能技术。
🔬 方法详解
问题定义:论文旨在解决法律领域使用大型语言模型(LLM)时,因律师在提示中包含个人身份信息(PII)而导致客户隐私泄露的问题。现有方法缺乏有效的隐私保护机制,使得在利用LLM提高法律工作效率的同时,面临着数据安全风险。
核心思路:论文的核心思路是在将包含敏感信息的提示发送到外部LLM之前,先使用本地的命名实体识别(NER)模型或本地LLM对提示中的PII进行识别和掩盖。在接收到LLM的回复后,再将掩盖的PII恢复,从而在不影响LLM功能的前提下,保护客户的隐私。这种方法的核心在于利用本地模型进行隐私处理,避免敏感数据直接暴露给第三方。
技术框架:LegalGuardian框架主要包含以下几个阶段:1) 提示输入:律师输入包含法律问题的提示,其中可能包含敏感的PII。2) PII识别与掩盖:使用本地NER模型(如GLiNER)或本地LLM(如Qwen2.5-14B)识别提示中的PII,并用预定义的占位符替换。3) LLM处理:将掩盖后的提示发送到外部LLM进行处理。4) 结果接收与PII恢复:接收来自LLM的回复,并使用本地模型将占位符替换回原始的PII。5) 输出:将包含完整信息的回复呈现给律师。
关键创新:该论文的关键创新在于提出了一个轻量级的、保护隐私的框架LegalGuardian,该框架能够在不影响LLM功能的前提下,有效地保护客户的隐私。通过结合NER技术和本地LLM,LegalGuardian能够在本地对敏感信息进行处理,避免了数据泄露的风险。此外,该框架的设计具有通用性,可以应用于不同的法律领域和不同的LLM。
关键设计:LegalGuardian的关键设计包括:1) 使用命名实体识别(NER)技术来识别提示中的PII。论文比较了传统的NER模型(GLiNER)和一次性提示的本地LLM(Qwen2.5-14B)在PII检测方面的性能。2) 使用预定义的占位符来替换PII,以确保LLM无法识别敏感信息。3) 在接收到LLM的回复后,使用本地模型将占位符替换回原始的PII。4) 通过语义相似性分析来评估框架在输出中保持的保真度。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LegalGuardian框架在PII检测方面取得了显著的成果。使用GLiNER模型时,F1分数为93%,而使用Qwen2.5-14B模型时,F1分数高达97%。此外,语义相似性分析证实,该框架在输出中保持了高保真度,确保了LLM工具的有效性。这些结果表明,LegalGuardian能够在保护客户隐私的同时,充分利用LLM的强大功能。
🎯 应用场景
LegalGuardian框架可广泛应用于法律咨询、合同审查、案件分析等领域,使律师能够在利用LLM提高工作效率的同时,确保客户信息的安全。该框架的应用有助于提升法律服务的质量和效率,同时增强客户对法律服务的信任感。未来,该框架可以扩展到其他需要处理敏感信息的领域,如医疗保健和金融服务。
📄 摘要(原文)
Large Language Models (LLMs) hold promise for advancing legal practice by automating complex tasks and improving access to justice. However, their adoption is limited by concerns over client confidentiality, especially when lawyers include sensitive Personally Identifiable Information (PII) in prompts, risking unauthorized data exposure. To mitigate this, we introduce LegalGuardian, a lightweight, privacy-preserving framework tailored for lawyers using LLM-based tools. LegalGuardian employs Named Entity Recognition (NER) techniques and local LLMs to mask and unmask confidential PII within prompts, safeguarding sensitive data before any external interaction. We detail its development and assess its effectiveness using a synthetic prompt library in immigration law scenarios. Comparing traditional NER models with one-shot prompted local LLM, we find that LegalGuardian achieves a F1-score of 93% with GLiNER and 97% with Qwen2.5-14B in PII detection. Semantic similarity analysis confirms that the framework maintains high fidelity in outputs, ensuring robust utility of LLM-based tools. Our findings indicate that legal professionals can harness advanced AI technologies without compromising client confidentiality or the quality of legal documents.