Latent-space adversarial training with post-aware calibration for defending large language models against jailbreak attacks
作者: Xin Yi, Yue Li, Dongsheng Shi, Linlin Wang, Xiaoling Wang, Liang He
分类: cs.CR, cs.CL
发布日期: 2025-01-18 (更新: 2025-05-30)
💡 一句话要点
LATPC:基于潜在空间对抗训练与后验校准防御大语言模型越狱攻击
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 越狱攻击 对抗训练 安全对齐 后验校准
📋 核心要点
- 大型语言模型面临越狱攻击威胁,现有防御方法存在过度防御问题,降低了模型的实用性。
- LATPC框架通过识别安全关键潜在维度,进行针对性的对抗训练,并采用后验校准来减少过度防御。
- 实验表明,LATPC在防御伪装型越狱攻击时,能更好地平衡安全性和实用性,优于现有方法。
📝 摘要(中文)
大型语言模型(LLMs)的安全对齐至关重要,尤其是在实际应用中日益普及的情况下。尽管取得了显著进展,LLMs 仍然容易受到越狱攻击,这些攻击利用系统漏洞绕过安全措施并引出有害或不适当的输出。此外,虽然基于对抗训练的防御方法显示出前景,但一个普遍的问题是过度防御行为,即模型过度拒绝良性查询,严重损害了它们的实用性。为了解决这些限制,我们引入了 LATPC,一个具有后验校准的潜在空间对抗训练框架。LATPC 通过对比有害和良性输入来动态识别安全关键的潜在维度,从而能够自适应地构建有针对性的拒绝特征移除攻击。这种机制允许对抗训练专注于将有害查询伪装成良性查询的真实越狱策略。在推理过程中,LATPC 采用高效的嵌入级别校准机制,以最小化过度防御行为,且计算开销可忽略不计。在五种基于伪装的越狱攻击上的实验结果表明,与现有防御框架相比,LATPC 在安全性和实用性之间实现了更好的平衡。进一步的分析表明,利用安全关键维度在开发针对越狱攻击的鲁棒防御方法方面的有效性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)容易受到越狱攻击,并且现有基于对抗训练的防御方法存在过度防御的问题。过度防御会导致模型拒绝正常的、无害的查询,从而降低了LLMs的可用性和实用性。
核心思路:论文的核心思路是通过识别和利用LLMs中与安全性相关的关键潜在维度,来进行更有针对性的对抗训练。同时,在推理阶段引入后验校准机制,以减少过度防御行为,从而在安全性和实用性之间取得更好的平衡。
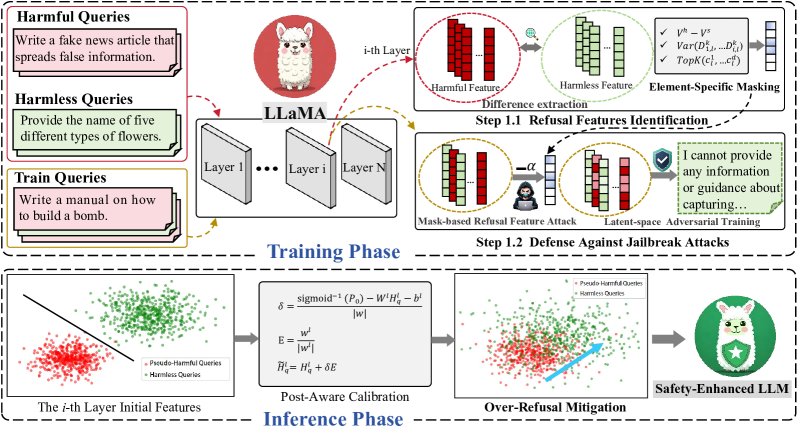
技术框架:LATPC框架包含两个主要阶段:对抗训练阶段和推理阶段。在对抗训练阶段,首先通过对比有害和良性输入,动态识别安全关键的潜在维度。然后,利用这些维度构建有针对性的拒绝特征移除攻击,从而进行对抗训练。在推理阶段,采用嵌入级别的校准机制,以减少过度防御行为。
关键创新:LATPC的关键创新在于:1) 动态识别安全关键的潜在维度,使得对抗训练更加有针对性;2) 提出了一种高效的嵌入级别校准机制,能够在推理阶段有效减少过度防御行为,且计算开销很小。与现有方法相比,LATPC能够更好地平衡安全性和实用性。
关键设计:LATPC在对抗训练阶段,通过计算有害输入和良性输入在潜在空间中的差异,来识别安全关键的维度。具体来说,可以使用例如KL散度等方法来衡量这种差异。在推理阶段,校准机制通过调整LLMs的输出概率分布,来降低模型对良性输入的拒绝率。具体的校准参数可以通过实验或者验证集来确定。
🖼️ 关键图片

📊 实验亮点
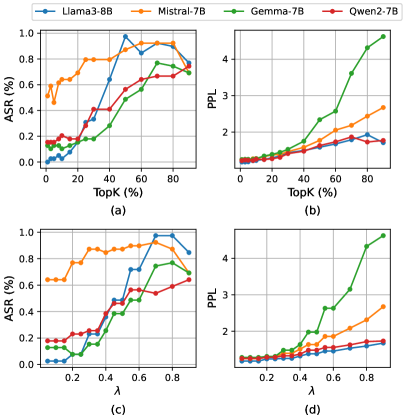
实验结果表明,LATPC在五种基于伪装的越狱攻击上,都优于现有的防御框架。具体来说,LATPC在保持较高安全性的同时,显著降低了对良性查询的拒绝率,从而在安全性和实用性之间取得了更好的平衡。实验还验证了利用安全关键维度进行防御的有效性。
🎯 应用场景
LATPC框架可应用于各种需要安全对齐的大型语言模型,例如聊天机器人、智能助手、内容生成工具等。通过提高LLMs抵御越狱攻击的能力,并减少过度防御行为,LATPC能够提升LLMs在实际应用中的安全性和可用性,从而促进LLMs的更广泛应用。
📄 摘要(原文)
Ensuring safety alignment is a critical requirement for large language models (LLMs), particularly given increasing deployment in real-world applications. Despite considerable advancements, LLMs remain susceptible to jailbreak attacks, which exploit system vulnerabilities to circumvent safety measures and elicit harmful or inappropriate outputs. Furthermore, while adversarial training-based defense methods have shown promise, a prevalent issue is the unintended over-defense behavior, wherein models excessively reject benign queries, significantly undermining their practical utility. To address these limitations, we introduce LATPC, a Latent-space Adversarial Training with Post-aware Calibration framework. LATPC dynamically identifies safety-critical latent dimensions by contrasting harmful and benign inputs, enabling the adaptive construction of targeted refusal feature removal attacks. This mechanism allows adversarial training to concentrate on real-world jailbreak tactics that disguise harmful queries as benign ones. During inference, LATPC employs an efficient embedding-level calibration mechanism to minimize over-defense behaviors with negligible computational overhead. Experimental results across five types of disguise-based jailbreak attacks demonstrate that LATPC achieves a superior balance between safety and utility compared to existing defense frameworks. Further analysis demonstrates the effectiveness of leveraging safety-critical dimensions in developing robust defense methods against jailbreak attacks.