The Geometry of Tokens in Internal Representations of Large Language Models
作者: Karthik Viswanathan, Yuri Gardinazzi, Giada Panerai, Alberto Cazzaniga, Matteo Biagetti
分类: cs.CL, cs.LG
发布日期: 2025-01-17
备注: 15+9 pages, 21 figures, all comments welcome!
💡 一句话要点
研究大型语言模型内部表征中token几何结构与next token预测的关系
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 token嵌入 几何结构 经验测度 next token预测
📋 核心要点
- 现有方法缺乏对大型语言模型内部token表征几何结构的深入理解,限制了对模型行为的解释。
- 论文核心思想是利用经验测度来量化token在Transformer层中的分布,并分析其几何特征与next token预测性能的关系。
- 实验结果表明,token嵌入的几何属性与next token预测的交叉熵损失之间存在相关性,高损失prompt的token表征位于高维空间。
📝 摘要(中文)
本文研究了Transformer模型中token嵌入的几何结构及其在next token预测中的作用。一个重要的联系使用了经验测度的概念,它编码了Transformer层中token点云的分布,并在平均场交互图中驱动token表征的演变。我们使用诸如内在维度、邻域重叠和余弦相似度等指标来观察性地探测跨层的这些经验测度。为了验证我们的方法,我们将这些指标与token被打乱的数据集进行比较,这破坏了句法和语义结构。我们的发现揭示了token嵌入的几何属性与next token预测的交叉熵损失之间的相关性,这意味着具有较高损失值的prompt中的token在高维空间中表示。
🔬 方法详解
问题定义:论文旨在理解大型语言模型(LLM)内部表征中,token的几何结构如何影响其在next token预测中的作用。现有方法通常将token嵌入视为独立的向量,忽略了它们之间的几何关系,以及这种关系如何影响模型的预测能力。因此,理解token嵌入的几何结构,有助于更好地解释LLM的行为,并可能用于改进模型的设计和训练。
核心思路:论文的核心思路是利用经验测度来描述token在Transformer层中的分布情况,并分析这些分布的几何特征。经验测度可以捕捉token之间的相互作用和整体结构,从而更好地理解token表征的演变过程。通过研究这些几何特征与next token预测性能之间的关系,可以揭示token表征的几何结构在模型预测中的作用。
技术框架:论文的技术框架主要包括以下几个步骤:1. 提取LLM不同层的token嵌入;2. 计算每一层的token嵌入的经验测度;3. 使用诸如内在维度、邻域重叠和余弦相似度等指标来量化经验测度的几何特征;4. 将这些几何特征与next token预测的交叉熵损失进行比较,分析它们之间的相关性;5. 通过对token进行shuffle,破坏句法和语义结构,验证几何特征与模型性能之间的关系。
关键创新:论文的关键创新在于将经验测度的概念引入到LLM的token表征分析中。通过经验测度,可以更好地捕捉token之间的相互作用和整体结构,从而更全面地理解token表征的几何特征。此外,论文还提出了一系列指标来量化经验测度的几何特征,为研究token表征的几何结构提供了新的工具。
关键设计:论文的关键设计包括:1. 使用内在维度来衡量token嵌入空间的复杂度;2. 使用邻域重叠来衡量token之间的相似性;3. 使用余弦相似度来衡量token之间的方向一致性;4. 通过shuffle token来破坏句法和语义结构,从而验证几何特征与模型性能之间的关系。论文没有特别提及损失函数或网络结构的修改,而是侧重于分析现有模型的内部表征。
🖼️ 关键图片

📊 实验亮点
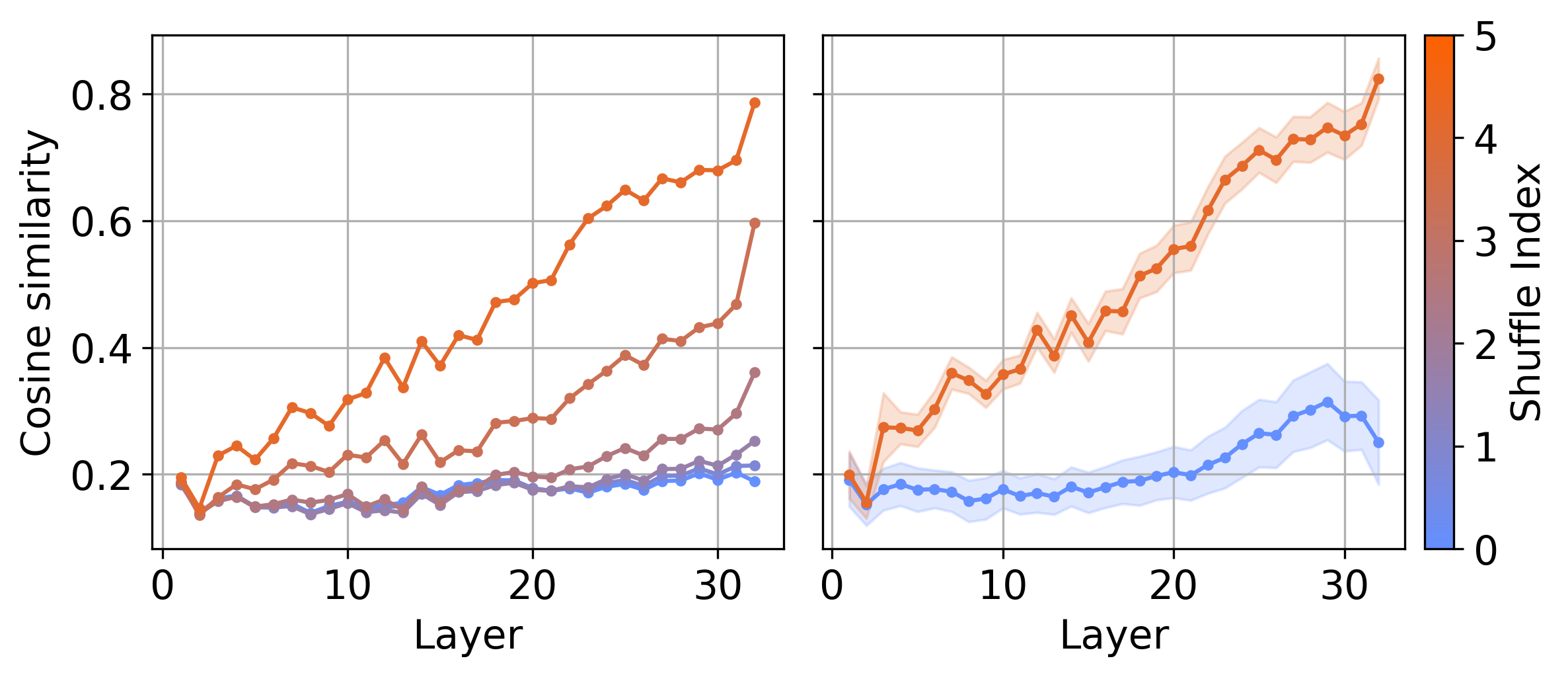
实验结果表明,token嵌入的几何属性与next token预测的交叉熵损失之间存在显著相关性。具体来说,具有较高损失值的prompt中的token在高维空间中表示,表明模型在处理这些prompt时可能面临更大的挑战。通过shuffle token的实验,验证了句法和语义结构对token表征几何结构的影响。
🎯 应用场景
该研究成果可应用于理解和改进大型语言模型。通过分析token表征的几何结构,可以更好地解释模型的预测行为,并可能用于设计更高效的训练方法和更鲁棒的模型架构。此外,该研究还可以用于评估不同模型的表征能力,并为模型的选择和部署提供指导。
📄 摘要(原文)
We investigate the relationship between the geometry of token embeddings and their role in the next token prediction within transformer models. An important aspect of this connection uses the notion of empirical measure, which encodes the distribution of token point clouds across transformer layers and drives the evolution of token representations in the mean-field interacting picture. We use metrics such as intrinsic dimension, neighborhood overlap, and cosine similarity to observationally probe these empirical measures across layers. To validate our approach, we compare these metrics to a dataset where the tokens are shuffled, which disrupts the syntactic and semantic structure. Our findings reveal a correlation between the geometric properties of token embeddings and the cross-entropy loss of next token predictions, implying that prompts with higher loss values have tokens represented in higher-dimensional spaces.