Theme-Explanation Structure for Table Summarization using Large Language Models: A Case Study on Korean Tabular Data
作者: TaeYoon Kwack, Jisoo Kim, Ki Yong Jung, DongGeon Lee, Heesun Park
分类: cs.CL, cs.AI
发布日期: 2025-01-17 (更新: 2025-07-09)
备注: Accepted to TRL@ACL 2025
💡 一句话要点
提出基于主题-解释结构的表格摘要生成方法Tabular-TX,提升LLM在韩语表格数据上的可解释性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格摘要 大型语言模型 可解释性 韩语 行政文档
📋 核心要点
- 现有表格摘要方法缺乏对人类可读性的关注,难以生成用户友好的摘要。
- Tabular-TX通过多步推理、记者角色提示和主题-解释结构化输出,提升摘要的可解释性。
- Tabular-TX利用上下文学习,无需大量标注数据和计算资源,即可有效处理复杂表格。
📝 摘要(中文)
本文介绍了一种基于主题-解释结构的表格摘要生成(Tabular-TX)流程,旨在从表格数据中生成高度可解释的摘要,特别关注韩语行政文档。现有的表格摘要方法通常忽略了对人类友好的输出这一关键方面。Tabular-TX通过多步骤推理过程确保LLM对表格的深度理解,然后采用记者角色提示策略来生成清晰的句子。关键在于,它将输出结构化为主题部分(状语短语)和解释部分(谓语从句),显著提高了可读性。该方法利用上下文学习,无需大量的微调以及相关的标注数据或计算资源。实验结果表明,Tabular-TX有效地处理了复杂的表格结构和元数据,为生成以人为中心的表格摘要提供了一个强大而高效的解决方案,尤其是在低资源场景下。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在处理复杂表格数据,特别是韩语行政文档时,生成的摘要可解释性不足的问题。现有方法通常难以理解表格的深层含义,并且生成的摘要不够清晰易懂,难以满足用户需求。
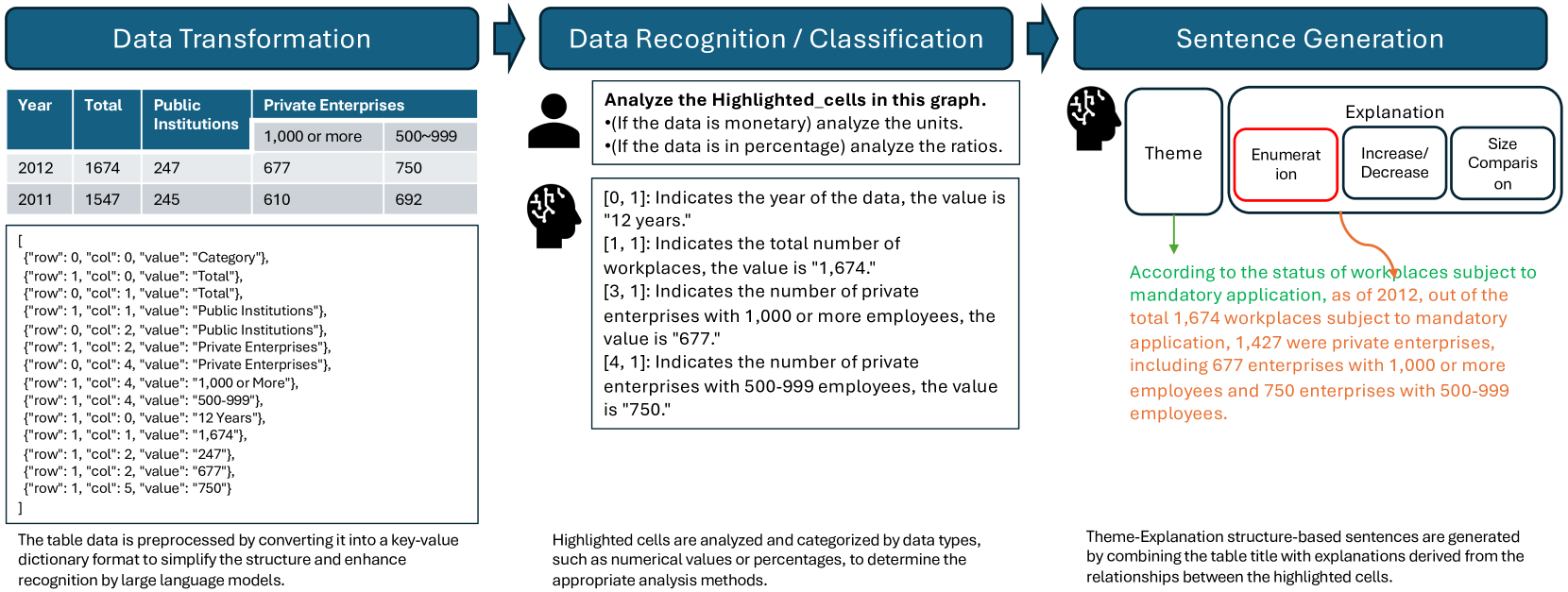
核心思路:论文的核心思路是将表格摘要生成过程分解为多个步骤,首先让LLM深入理解表格内容,然后通过特定的提示策略引导LLM生成清晰的句子,最后将输出结构化为“主题-解释”的形式,从而提高摘要的可读性和可解释性。这种结构化的输出方式更符合人类的阅读习惯,更容易理解摘要的含义。
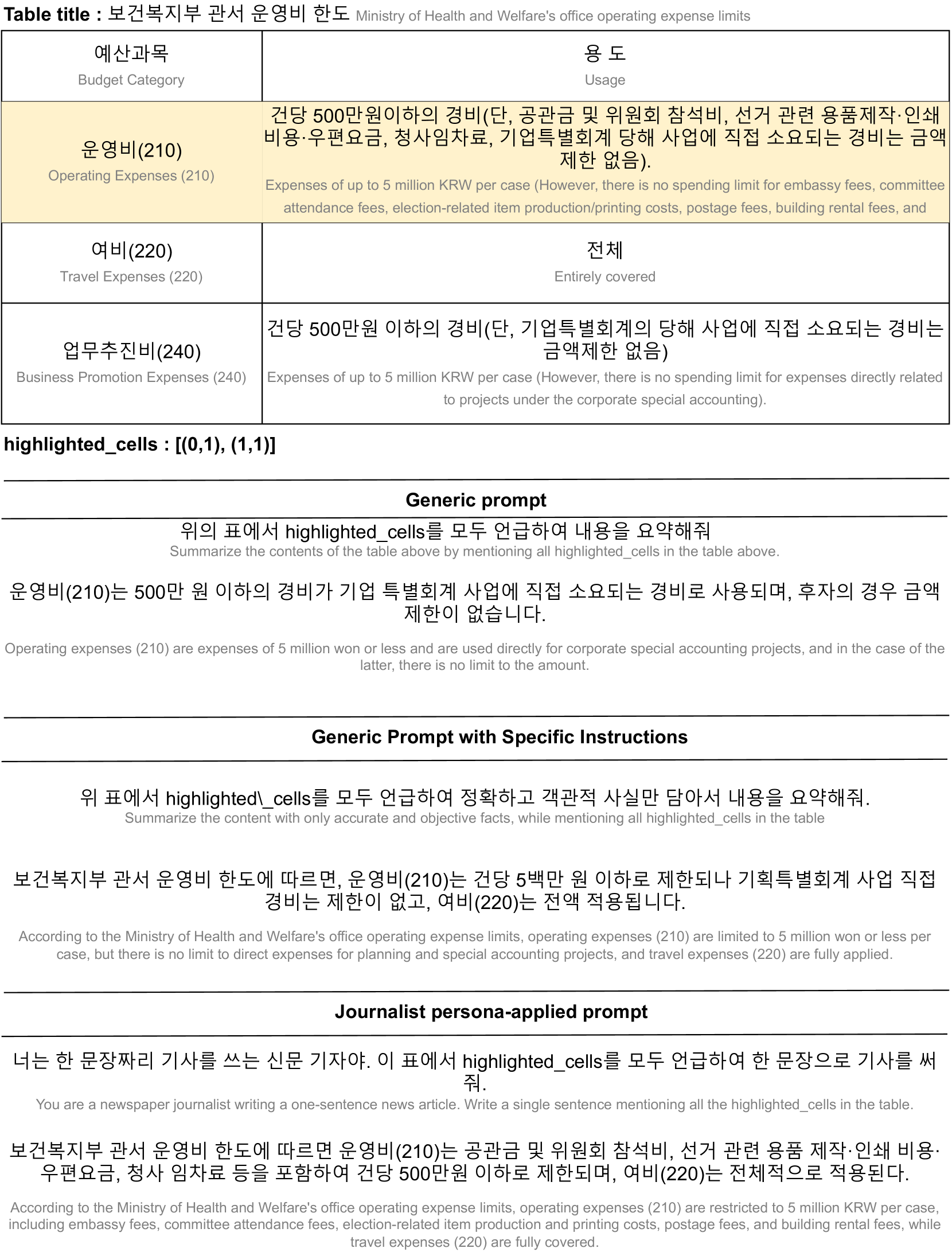
技术框架:Tabular-TX流程主要包含以下几个阶段:1) 多步推理:通过多个步骤引导LLM深入理解表格数据,包括识别关键信息、理解表格结构等。2) 记者角色提示:使用特定的提示语,引导LLM以记者的身份生成清晰、简洁的句子。3) 主题-解释结构化输出:将生成的句子结构化为“主题(状语短语)-解释(谓语从句)”的形式,提高可读性。
关键创新:Tabular-TX的关键创新在于其“主题-解释”的结构化输出方式。这种结构化的输出方式能够显著提高摘要的可读性和可解释性,使得用户更容易理解表格数据的含义。此外,该方法还采用了上下文学习,无需大量的微调和标注数据,降低了模型的训练成本。
关键设计:论文采用了in-context learning,避免了繁琐的fine-tuning过程。具体prompt的设计上,采用了journalist persona prompting,引导LLM生成更清晰的句子。主题-解释结构的具体实现方式未知,可能是在prompt中进行了约束,或者在后处理阶段进行了调整。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Tabular-TX能够有效处理复杂的表格结构和元数据,生成以人为中心的表格摘要。该方法在低资源场景下表现出色,无需大量标注数据和计算资源即可取得良好的效果。具体的性能数据和对比基线在摘要中未提及,属于未知信息。
🎯 应用场景
该研究成果可应用于各种需要从表格数据中提取关键信息的场景,例如行政文档处理、金融报告分析、科学数据挖掘等。通过生成可解释性强的摘要,可以帮助用户快速理解表格数据,提高工作效率。未来,该方法可以扩展到其他语言和领域,为更多用户提供高质量的表格摘要服务。
📄 摘要(原文)
Tables are a primary medium for conveying critical information in administrative domains, yet their complexity hinders utilization by Large Language Models (LLMs). This paper introduces the Theme-Explanation Structure-based Table Summarization (Tabular-TX) pipeline, a novel approach designed to generate highly interpretable summaries from tabular data, with a specific focus on Korean administrative documents. Current table summarization methods often neglect the crucial aspect of human-friendly output. Tabular-TX addresses this by first employing a multi-step reasoning process to ensure deep table comprehension by LLMs, followed by a journalist persona prompting strategy for clear sentence generation. Crucially, it then structures the output into a Theme Part (an adverbial phrase) and an Explanation Part (a predicative clause), significantly enhancing readability. Our approach leverages in-context learning, obviating the need for extensive fine-tuning and associated labeled data or computational resources. Experimental results show that Tabular-TX effectively processes complex table structures and metadata, offering a robust and efficient solution for generating human-centric table summaries, especially in low-resource scenarios.