Multi-stage Training of Bilingual Islamic LLM for Neural Passage Retrieval
作者: Vera Pavlova
分类: cs.CL
发布日期: 2025-01-17
💡 一句话要点
提出一种多阶段训练的伊斯兰双语LLM,用于提升神经段落检索性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 神经段落检索 双语模型 领域自适应 多阶段训练 数据增强 伊斯兰领域 XLM-R 语言缩减
📋 核心要点
- 现有伊斯兰领域神经检索模型面临语料库不平衡问题,阿拉伯语资源丰富,而英语等其他语言资源匮乏。
- 论文提出一种多阶段训练方法,结合领域自适应技术,利用XLM-R模型构建轻量级双语LLM。
- 通过数据增强和领域内数据集的构建,该模型在下游检索任务中表现优于单语模型。
📝 摘要(中文)
本研究探讨了自然语言处理(NLP)技术在伊斯兰领域中的应用,重点是开发一种伊斯兰神经检索模型。通过利用强大的XLM-R模型,该研究采用了一种语言缩减技术来创建一个轻量级的双语大型语言模型(LLM)。我们的领域自适应方法解决了伊斯兰领域面临的独特挑战,即只有阿拉伯语存在大量的领域内语料库,而包括英语在内的其他语言的语料库则有限。该工作采用了一种用于检索模型的多阶段训练过程,结合了大型检索数据集(如MS MARCO)和较小的领域内数据集,以提高检索性能。此外,我们还通过数据增强技术并结合可靠的伊斯兰来源,策划了一个英语的领域内检索数据集。这种方法增强了用于检索的领域特定数据集,从而进一步提高了性能。研究结果表明,将领域自适应和多阶段训练方法相结合,可以使双语伊斯兰神经检索模型在下游检索任务中优于单语模型。
🔬 方法详解
问题定义:论文旨在解决伊斯兰领域神经段落检索中,由于阿拉伯语和英语语料库规模差异巨大导致的模型性能瓶颈。现有方法难以有效利用有限的英语领域内数据,导致检索效果不佳。
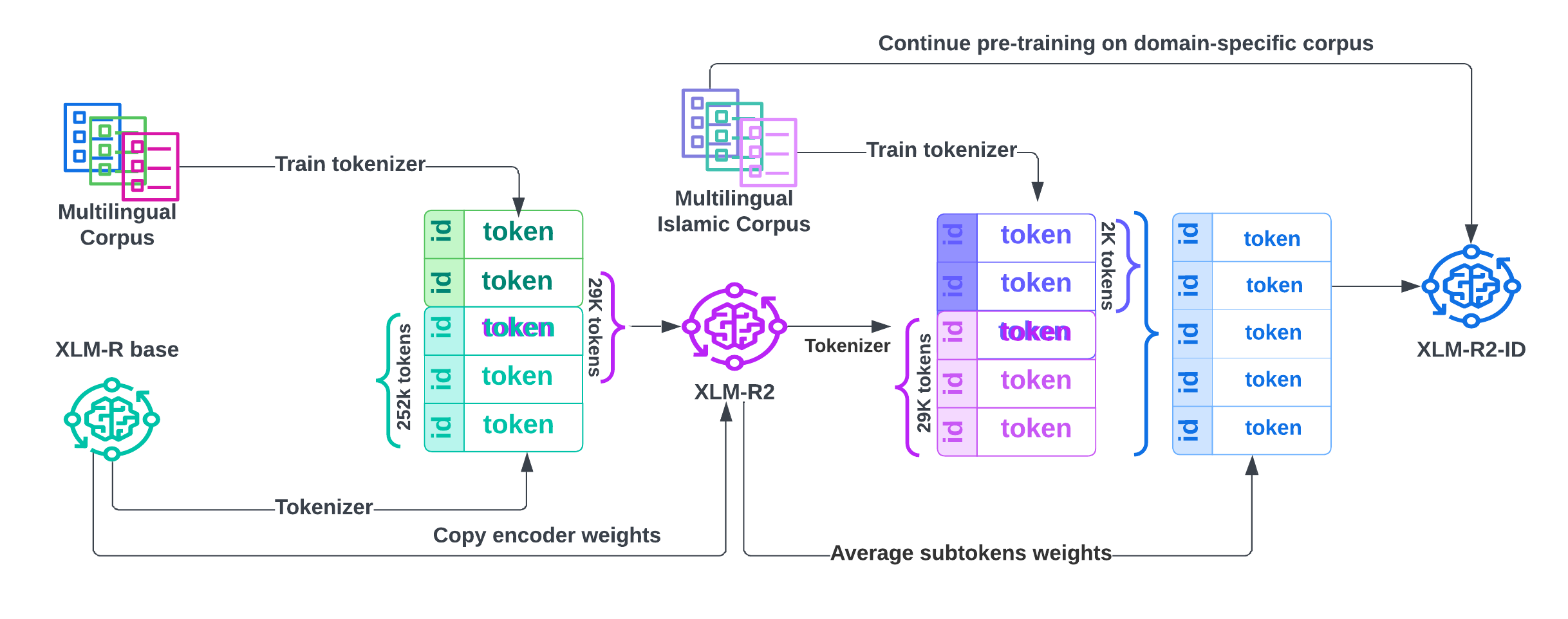
核心思路:论文的核心思路是利用XLM-R模型强大的跨语言能力,通过语言缩减技术构建一个轻量级的双语LLM。然后,采用多阶段训练策略,先在大规模通用检索数据集上预训练,再在领域内数据集上进行微调,从而使模型能够更好地适应伊斯兰领域的特定语言和知识。同时,通过数据增强技术扩充英语领域内数据集,进一步提升模型性能。
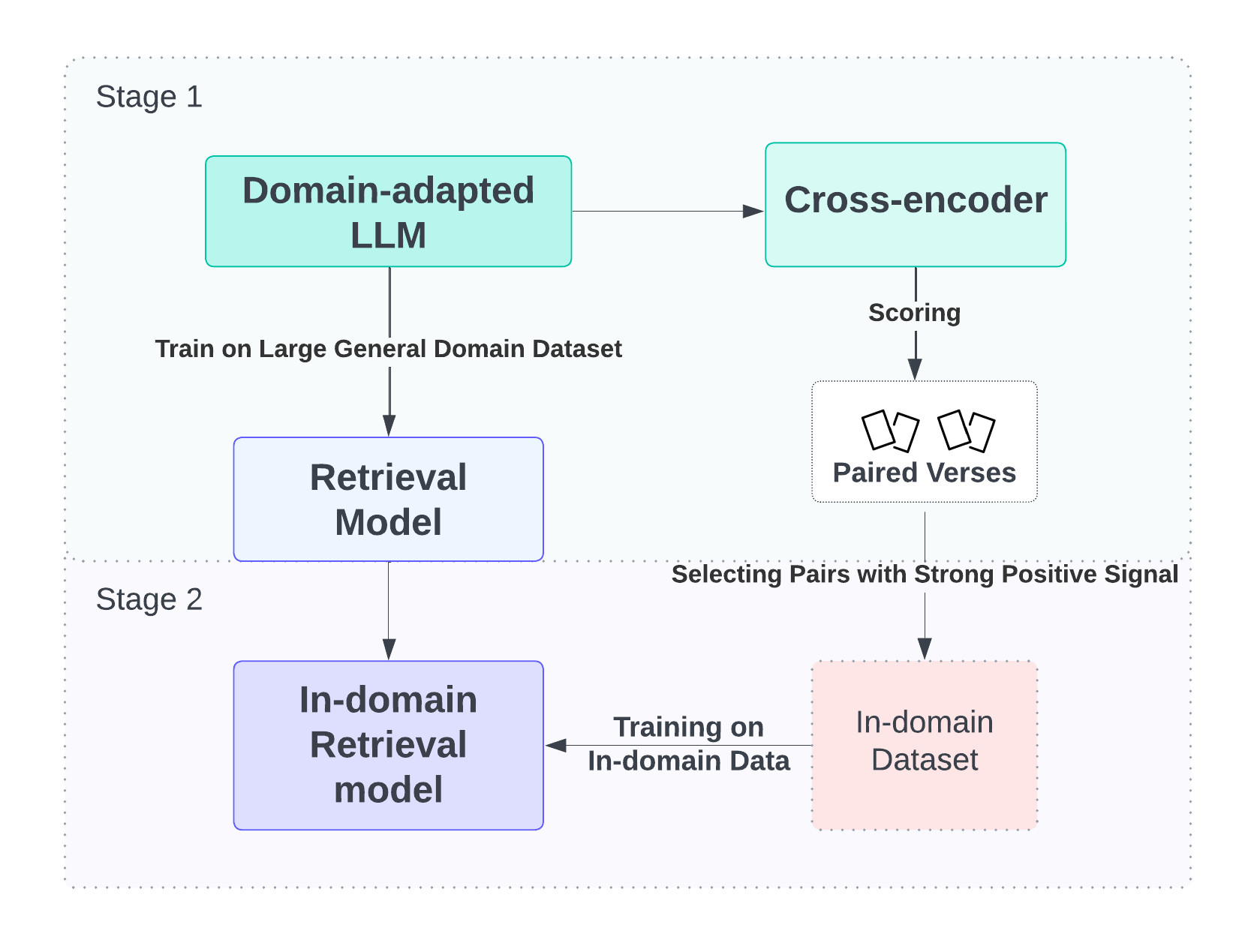
技术框架:整体框架包含以下几个主要阶段: 1. 语言缩减:对XLM-R模型进行裁剪,减少模型参数量,使其更轻量化。 2. 多阶段训练: - 第一阶段:在大规模通用检索数据集(如MS MARCO)上进行预训练。 - 第二阶段:在领域内阿拉伯语和英语数据集上进行微调。 3. 数据增强:利用可靠的伊斯兰来源,对英语领域内数据集进行数据增强。 4. 检索:使用训练好的模型进行神经段落检索。
关键创新:论文的关键创新在于: 1. 提出了一种针对伊斯兰领域的双语神经检索模型,有效解决了语料库不平衡问题。 2. 结合语言缩减、多阶段训练和数据增强等多种技术,显著提升了模型在领域内的检索性能。 3. 构建了一个英语的领域内检索数据集,为后续研究提供了宝贵资源。
关键设计:论文中关于模型训练的关键设计细节包括: 1. 使用XLM-R作为基础模型,并采用语言缩减技术降低模型复杂度。 2. 多阶段训练过程中,选择合适的损失函数和优化器,并调整学习率等超参数。 3. 数据增强策略的选择,确保生成的数据质量和多样性。
🖼️ 关键图片
📊 实验亮点
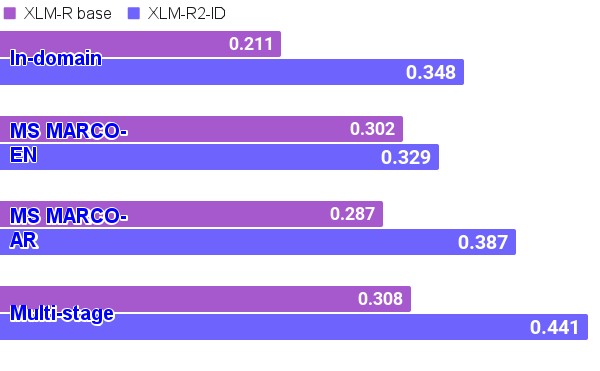
实验结果表明,该方法提出的双语伊斯兰神经检索模型在下游检索任务中优于单语模型。通过结合领域自适应和多阶段训练,模型能够更好地理解和处理伊斯兰领域的特定语言和知识,从而显著提升检索性能。具体的性能数据和对比基线在论文中进行了详细展示。
🎯 应用场景
该研究成果可应用于伊斯兰知识库的构建、伊斯兰问答系统、伊斯兰法律咨询等领域。通过提升神经检索的准确性和效率,可以帮助用户更快速地获取所需的伊斯兰知识,具有重要的实际应用价值和社会意义。未来,该技术还可以扩展到其他低资源语言的领域知识检索。
📄 摘要(原文)
This study examines the use of Natural Language Processing (NLP) technology within the Islamic domain, focusing on developing an Islamic neural retrieval model. By leveraging the robust XLM-R model, the research employs a language reduction technique to create a lightweight bilingual large language model (LLM). Our approach for domain adaptation addresses the unique challenges faced in the Islamic domain, where substantial in-domain corpora exist only in Arabic while limited in other languages, including English. The work utilizes a multi-stage training process for retrieval models, incorporating large retrieval datasets, such as MS MARCO, and smaller, in-domain datasets to improve retrieval performance. Additionally, we have curated an in-domain retrieval dataset in English by employing data augmentation techniques and involving a reliable Islamic source. This approach enhances the domain-specific dataset for retrieval, leading to further performance gains. The findings suggest that combining domain adaptation and a multi-stage training method for the bilingual Islamic neural retrieval model enables it to outperform monolingual models on downstream retrieval tasks.