ComplexFuncBench: Exploring Multi-Step and Constrained Function Calling under Long-Context Scenario
作者: Lucen Zhong, Zhengxiao Du, Xiaohan Zhang, Haiyi Hu, Jie Tang
分类: cs.CL
发布日期: 2025-01-17
🔗 代码/项目: GITHUB
💡 一句话要点
ComplexFuncBench:长程上下文下多步约束函数调用评测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 函数调用 长程上下文 多步推理 约束优化 大语言模型 评测基准 自动化评估
📋 核心要点
- 现有函数调用评测缺乏对多步骤、约束性真实场景的覆盖,难以有效评估LLM的实际应用能力。
- ComplexFuncBench通过构建包含长程上下文、多步推理和约束条件的函数调用任务,更贴近真实应用场景。
- ComplexEval自动化评估框架,能够定量分析LLM在复杂函数调用任务中的性能,为模型优化提供依据。
📝 摘要(中文)
本文提出了ComplexFuncBench,一个用于评估大型语言模型(LLMs)在复杂函数调用能力方面的基准,涵盖五个真实世界的场景。与现有基准相比,ComplexFuncBench包含多步和约束函数调用,需要长参数填充、参数值推理以及128k的长程上下文。此外,本文还提出了一个自动评估框架ComplexEval,用于定量评估复杂函数调用任务。通过全面的实验,揭示了当前最先进的LLMs在函数调用方面的不足,并为优化这些能力提出了未来的研究方向。数据和代码可在https://github.com/THUDM/ComplexFuncBench获取。
🔬 方法详解
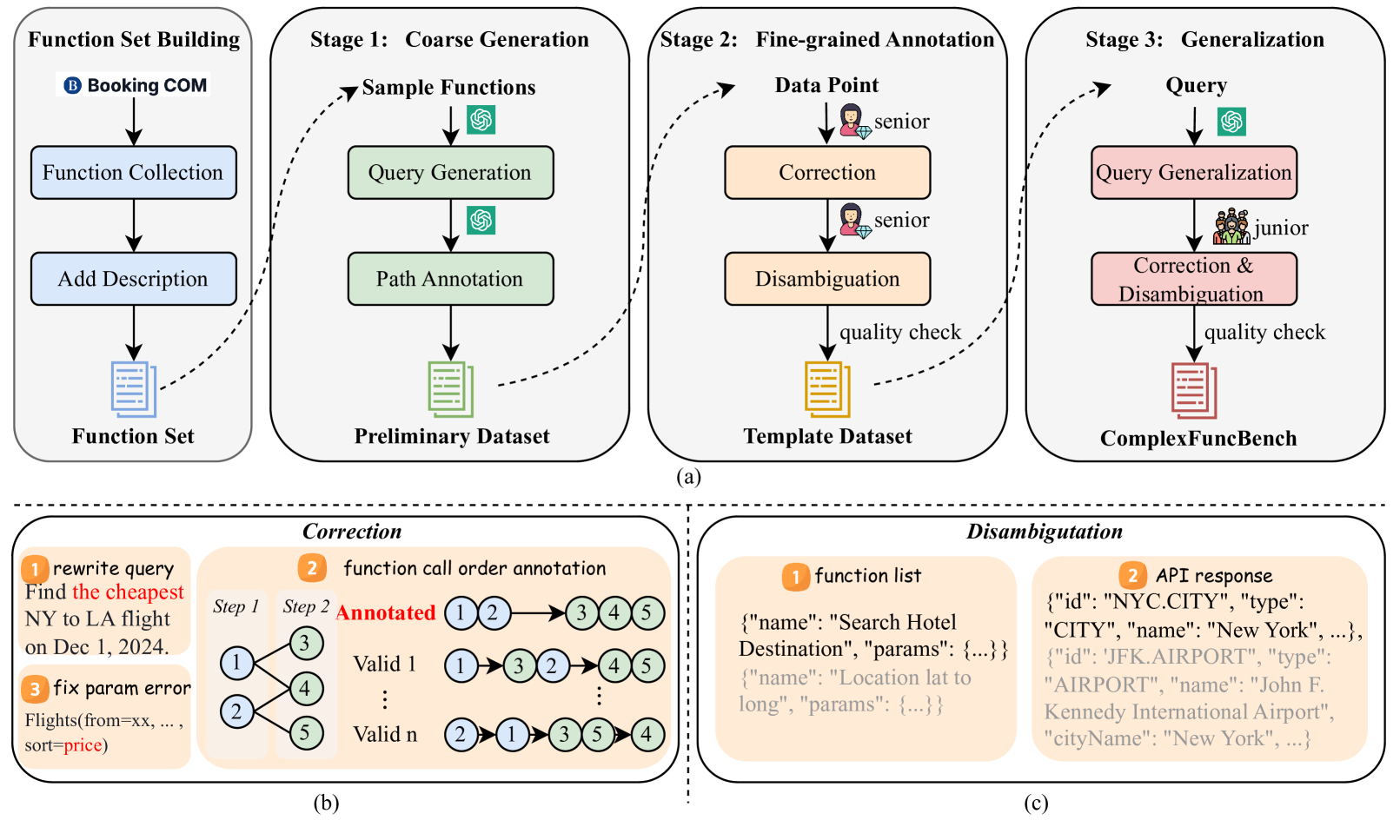
问题定义:现有的大语言模型函数调用能力评测基准,难以模拟真实场景中多步骤、参数约束以及长程上下文依赖等复杂情况。这导致对LLM函数调用能力的评估不够全面,无法准确反映其在实际应用中的表现。现有方法的痛点在于数据收集和评估的复杂性,缺乏一个能够有效评估复杂函数调用能力的基准。
核心思路:ComplexFuncBench的核心思路是构建一个更贴近真实应用场景的复杂函数调用评测基准。通过设计包含多步骤、参数约束和长程上下文依赖的任务,来全面评估LLM的函数调用能力。同时,开发自动评估框架,实现对复杂函数调用任务的定量评估。
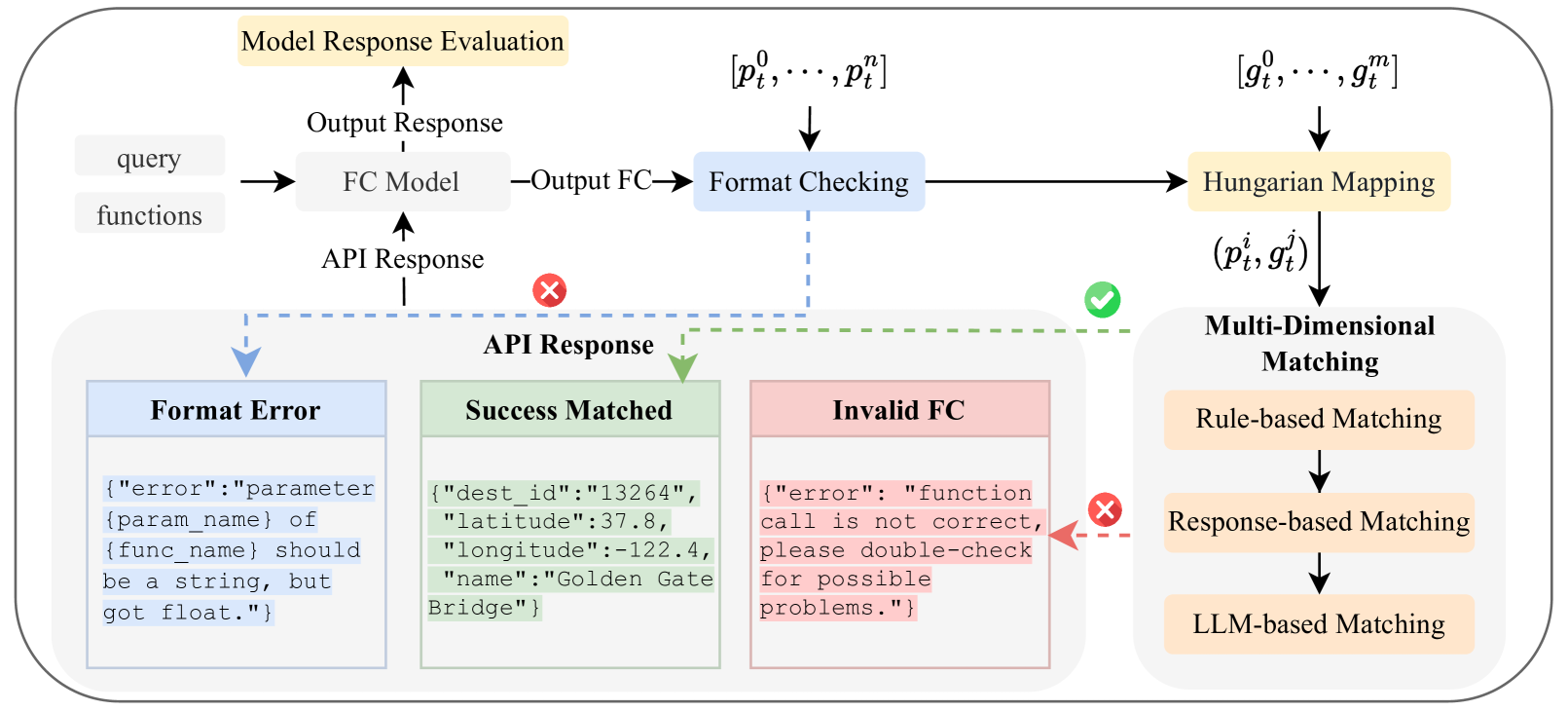
技术框架:ComplexFuncBench包含五个真实世界的场景,每个场景都设计了多步和约束函数调用任务。这些任务需要LLM进行长参数填充、参数值推理,并处理128k的长程上下文。ComplexEval自动评估框架则用于定量评估LLM在这些任务上的表现。整体流程为:LLM接收包含函数调用请求的输入,生成函数调用序列,ComplexEval根据预定义的规则和指标对生成的序列进行评估。
关键创新:ComplexFuncBench的关键创新在于其对复杂函数调用场景的模拟,包括多步骤、约束条件和长程上下文。这使得该基准能够更全面地评估LLM的函数调用能力,并发现现有模型在处理复杂任务时的不足。此外,ComplexEval自动评估框架的提出,也为复杂函数调用任务的定量评估提供了有效的工具。
关键设计:ComplexFuncBench中的任务设计需要仔细考虑参数之间的依赖关系和约束条件,以确保任务的合理性和挑战性。ComplexEval的评估指标需要能够准确反映LLM在不同方面的表现,例如参数填充的准确性、推理的正确性以及对约束条件的满足程度。具体的参数设置和损失函数等技术细节未知,需要参考论文的后续章节或代码实现。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有最先进的LLM在ComplexFuncBench上的表现仍有不足,尤其是在处理多步骤推理和约束条件时。这表明,当前的模型在复杂函数调用方面仍有很大的提升空间。具体的性能数据和对比基线未知,需要参考论文的实验章节。
🎯 应用场景
该研究成果可应用于智能助手、自动化流程、智能客服等领域。通过提升LLM在复杂函数调用方面的能力,可以实现更智能、更高效的任务自动化,从而提高生产力并改善用户体验。未来,该研究可以推动LLM在更广泛的实际应用场景中的落地。
📄 摘要(原文)
Enhancing large language models (LLMs) with real-time APIs can help generate more accurate and up-to-date responses. However, evaluating the function calling abilities of LLMs in real-world scenarios remains under-explored due to the complexity of data collection and evaluation. In this work, we introduce ComplexFuncBench, a benchmark for complex function calling across five real-world scenarios. Compared to existing benchmarks, ComplexFuncBench encompasses multi-step and constrained function calling, which requires long-parameter filing, parameter value reasoning, and 128k long context. Additionally, we propose an automatic framework, ComplexEval, for quantitatively evaluating complex function calling tasks. Through comprehensive experiments, we demonstrate the deficiencies of state-of-the-art LLMs in function calling and suggest future directions for optimizing these capabilities. The data and code are available at \url{https://github.com/THUDM/ComplexFuncBench}.