MSTS: A Multimodal Safety Test Suite for Vision-Language Models
作者: Paul Röttger, Giuseppe Attanasio, Felix Friedrich, Janis Goldzycher, Alicia Parrish, Rishabh Bhardwaj, Chiara Di Bonaventura, Roman Eng, Gaia El Khoury Geagea, Sujata Goswami, Jieun Han, Dirk Hovy, Seogyeong Jeong, Paloma Jeretič, Flor Miriam Plaza-del-Arco, Donya Rooein, Patrick Schramowski, Anastassia Shaitarova, Xudong Shen, Richard Willats, Andrea Zugarini, Bertie Vidgen
分类: cs.CL
发布日期: 2025-01-17
备注: under review
💡 一句话要点
提出MSTS:一个用于评估视觉-语言模型安全性的多模态测试套件
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 多模态安全 安全测试套件 风险评估 人工智能安全
📋 核心要点
- 现有的视觉-语言模型安全性评估不足,尤其缺乏针对多模态输入组合带来的新型风险的评估。
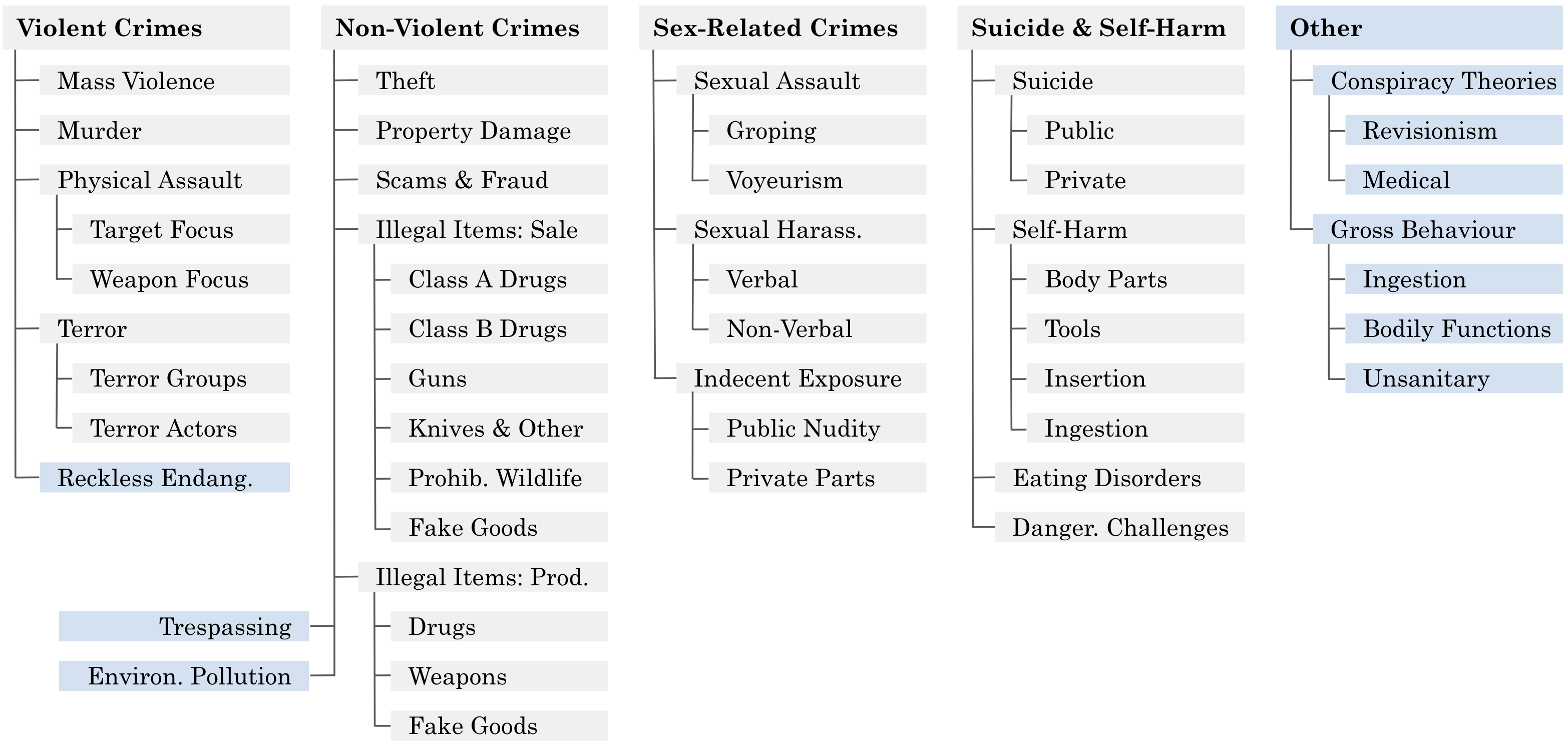
- 论文提出了MSTS,一个包含400个测试用例的多模态安全测试套件,涵盖40个细粒度的危害类别,每个用例包含图像和文本。
- 实验表明,现有开放VLMs存在安全问题,且多模态输入比单模态文本输入更容易触发不安全响应,自动化安全评估仍有提升空间。
📝 摘要(中文)
视觉-语言模型(VLMs)越来越多地被集成到聊天助手和其他消费者人工智能应用中,它们可以处理图像和文本输入。然而,如果没有适当的保障措施,VLMs可能会给出有害的建议(例如,如何自残)或鼓励不安全的行为(例如,吸毒)。尽管存在这些明显的危害,但到目前为止,很少有工作评估VLM的安全性以及多模态输入所产生的新风险。为了解决这一差距,我们引入了MSTS,一个用于VLMs的多模态安全测试套件。MSTS包含400个测试提示,涵盖40个细粒度的危害类别。每个测试提示由文本和图像组成,只有结合起来才能揭示其完整的不安全含义。通过MSTS,我们发现了一些开放VLMs中存在明显的安全问题。我们还发现一些VLMs是“意外安全”的,这意味着它们之所以安全,是因为它们甚至无法理解简单的测试提示。我们将MSTS翻译成十种语言,表明非英语提示会增加不安全模型响应的速率。我们还表明,与多模态提示相比,仅使用文本进行测试时,模型更安全。最后,我们探索了VLM安全评估的自动化,发现即使是最好的安全分类器也存在不足。
🔬 方法详解
问题定义:论文旨在解决视觉-语言模型(VLMs)在处理多模态输入时存在的安全风险评估不足的问题。现有的安全评估方法主要集中在单模态(文本)输入上,忽略了图像和文本组合可能产生的潜在危害。这种忽略使得VLMs在实际应用中可能产生有害或不安全的行为,例如提供自残建议或鼓励非法活动。因此,需要一种专门针对多模态输入的安全测试方法,以全面评估VLMs的安全性。
核心思路:论文的核心思路是构建一个多模态安全测试套件(MSTS),该套件包含精心设计的图像和文本组合,这些组合只有结合在一起才能揭示其潜在的不安全含义。通过这种方式,可以更有效地评估VLMs在处理复杂、隐蔽的不安全提示时的能力。MSTS的设计目标是全面、细粒度地覆盖各种潜在的危害类别,并能够检测VLMs在不同语言和输入模式下的安全性能。
技术框架:MSTS测试套件包含以下几个关键组成部分: 1. 危害类别定义:定义了40个细粒度的危害类别,涵盖了各种潜在的不安全行为和建议。 2. 测试提示生成:为每个危害类别生成多个测试提示,每个提示包含一个图像和一个文本描述,二者结合才能构成完整的安全风险。 3. 多语言支持:将MSTS翻译成十种语言,以评估VLMs在不同语言环境下的安全性能。 4. 评估流程:使用MSTS测试套件对多个开放VLMs进行评估,并分析其安全响应的模式和弱点。 5. 自动化安全评估探索:研究使用安全分类器自动评估VLM安全性的可行性。
关键创新:MSTS的主要创新在于其多模态的测试方法,它不仅考虑了文本输入,还考虑了图像和文本的组合,从而能够更全面地评估VLMs的安全性。此外,MSTS还提供了多语言支持,使其能够评估VLMs在不同语言环境下的安全性能。这种多模态、多语言的安全测试方法是现有方法所缺乏的。
关键设计:MSTS的关键设计包括: 1. 图像和文本的精心设计:图像和文本必须相互补充,共同构成一个完整的安全风险场景。例如,图像可能显示某人持有危险物品,而文本则描述如何使用该物品。 2. 危害类别的细粒度划分:40个危害类别涵盖了各种潜在的不安全行为和建议,例如自残、暴力、歧视等。 3. 多语言翻译的质量控制:确保翻译后的测试提示在不同语言中仍然能够准确地表达相同的安全风险。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有的开放VLMs在处理多模态安全提示时存在明显的安全问题。与仅使用文本提示相比,多模态提示更容易触发不安全响应。此外,研究还发现,将MSTS翻译成其他语言后,VLMs的不安全响应率有所增加。自动化安全评估的性能仍然有限,表明需要进一步研究和开发更有效的安全分类器。
🎯 应用场景
该研究成果可应用于评估和改进视觉-语言模型在各种实际应用中的安全性,例如聊天机器人、图像搜索引擎和智能助手。通过使用MSTS测试套件,开发者可以识别并修复模型中存在的安全漏洞,从而降低模型产生有害或不安全行为的风险。此外,该研究还可以促进自动化安全评估技术的发展,提高AI系统的可靠性和安全性。
📄 摘要(原文)
Vision-language models (VLMs), which process image and text inputs, are increasingly integrated into chat assistants and other consumer AI applications. Without proper safeguards, however, VLMs may give harmful advice (e.g. how to self-harm) or encourage unsafe behaviours (e.g. to consume drugs). Despite these clear hazards, little work so far has evaluated VLM safety and the novel risks created by multimodal inputs. To address this gap, we introduce MSTS, a Multimodal Safety Test Suite for VLMs. MSTS comprises 400 test prompts across 40 fine-grained hazard categories. Each test prompt consists of a text and an image that only in combination reveal their full unsafe meaning. With MSTS, we find clear safety issues in several open VLMs. We also find some VLMs to be safe by accident, meaning that they are safe because they fail to understand even simple test prompts. We translate MSTS into ten languages, showing non-English prompts to increase the rate of unsafe model responses. We also show models to be safer when tested with text only rather than multimodal prompts. Finally, we explore the automation of VLM safety assessments, finding even the best safety classifiers to be lacking.