Agent-as-Judge for Factual Summarization of Long Narratives
作者: Yeonseok Jeong, Minsoo Kim, Seung-won Hwang, Byung-Hak Kim
分类: cs.CL
发布日期: 2025-01-17 (更新: 2025-09-29)
💡 一句话要点
提出 NarrativeFactScore,利用 Agent-as-Judge 评估长叙事文本摘要的事实准确性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本摘要 事实准确性 Agent-as-a-Judge 人物知识图 叙事理解
📋 核心要点
- 现有摘要评估指标,如ROUGE和BERTScore,无法有效衡量长叙事文本摘要的事实准确性,尤其是在人物关系理解方面。
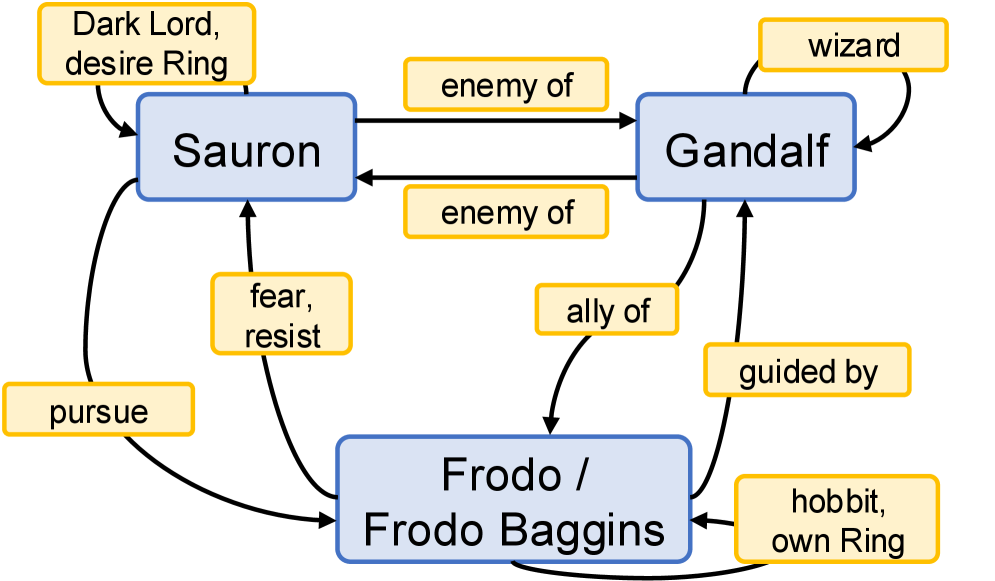
- 提出 NarrativeFactScore 框架,利用 Agent-as-a-Judge 模式,通过人物知识图(CKG)评估摘要的事实一致性并提供改进指导。
- 实验结果表明,NarrativeFactScore 在评估长叙事文本摘要的事实准确性方面优于现有方法,并能有效指导摘要改进。
📝 摘要(中文)
大型语言模型(LLMs)在摘要任务中,基于ROUGE和BERTScore等传统指标,已经展现出接近人类的表现。然而,这些指标无法充分捕捉摘要质量的关键方面,如事实准确性,特别是对于长叙事文本(>100K tokens)。最近的进展,如LLM-as-a-Judge,解决了基于词汇相似性的指标的局限性,但仍然存在事实不一致的问题,尤其是在理解人物关系和状态方面。本文提出了NarrativeFactScore,一种新颖的“Agent-as-a-Judge”框架,用于评估和改进摘要。通过利用从输入和生成的摘要中提取的人物知识图(CKG),NarrativeFactScore评估事实一致性,并为改进提供可操作的指导,例如识别缺失或错误的facts。通过详细的工作流程说明和在广泛采用的基准上的广泛验证,证明了NarrativeFactScore的有效性,与竞争方法相比,实现了卓越的性能。结果突出了agent驱动的评估系统在提高LLM生成的摘要的事实可靠性方面的潜力。
🔬 方法详解
问题定义:论文旨在解决长叙事文本摘要的事实准确性评估问题。现有方法,如基于词汇相似性的指标(ROUGE, BERTScore)和 LLM-as-a-Judge 方法,在评估长文本摘要的事实一致性方面存在局限性,尤其是在理解人物关系和状态方面,容易产生幻觉和不一致。
核心思路:论文的核心思路是利用 Agent-as-a-Judge 的模式,构建一个能够理解人物关系和状态的智能体,通过人物知识图(CKG)来评估摘要的事实一致性。该智能体能够识别摘要中缺失或错误的 facts,并提供改进建议。
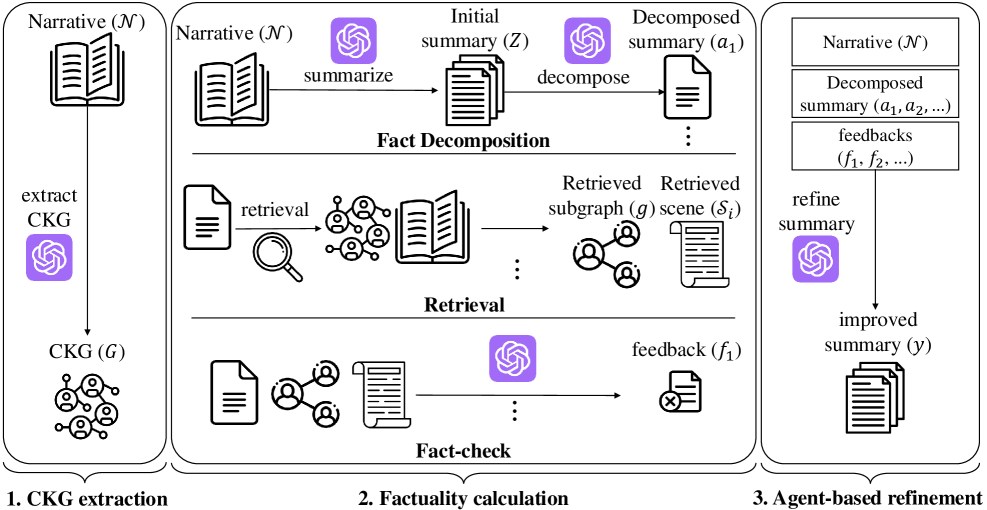
技术框架:NarrativeFactScore 框架主要包含以下几个阶段:1) 从原始文本和生成的摘要中提取人物知识图(CKG)。2) 利用 CKG 构建 Agent-as-a-Judge。3) Agent-as-a-Judge 评估摘要的事实一致性,识别缺失或错误的 facts。4) 提供改进建议,指导摘要改进。
关键创新:该论文的关键创新在于提出了 NarrativeFactScore 框架,将 Agent-as-a-Judge 的模式应用于长叙事文本摘要的事实准确性评估。通过人物知识图(CKG)的构建和利用,该框架能够更准确地评估摘要的事实一致性,并提供可操作的改进建议。与现有方法相比,NarrativeFactScore 能够更好地理解人物关系和状态,减少幻觉和不一致。
关键设计:关于 CKG 的构建,论文可能采用了实体识别、关系抽取等技术。Agent-as-a-Judge 的具体实现细节(例如,智能体的架构、推理方法等)未知。损失函数和网络结构等技术细节在摘要中没有提及,因此未知。
🖼️ 关键图片

📊 实验亮点
论文通过在广泛采用的基准数据集上进行实验,验证了 NarrativeFactScore 的有效性。实验结果表明,与现有的摘要评估方法相比,NarrativeFactScore 在评估长叙事文本摘要的事实准确性方面表现更优,能够更准确地识别摘要中存在的错误和不一致,并提供有效的改进建议。具体的性能数据和提升幅度在摘要中没有明确给出,因此未知。
🎯 应用场景
该研究成果可应用于各种需要生成长文本摘要的场景,例如新闻报道、小说创作、剧本编写等。通过提高摘要的事实准确性,可以增强用户对信息的信任度,并减少因错误信息带来的负面影响。未来,该技术有望应用于智能写作、自动校对等领域,提高文本生成质量。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated near-human performance in summarization tasks based on traditional metrics such as ROUGE and BERTScore. However, these metrics do not adequately capture critical aspects of summarization quality, such as factual accuracy, particularly for long narratives (>100K tokens). Recent advances, such as LLM-as-a-Judge, address the limitations of metrics based on lexical similarity but still exhibit factual inconsistencies, especially in understanding character relationships and states. In this work, we introduce NarrativeFactScore, a novel "Agent-as-a-Judge" framework for evaluating and refining summaries. By leveraging a Character Knowledge Graph (CKG) extracted from input and generated summaries, NarrativeFactScore assesses the factual consistency and provides actionable guidance for refinement, such as identifying missing or erroneous facts. We demonstrate the effectiveness of NarrativeFactScore through a detailed workflow illustration and extensive validation on widely adopted benchmarks, achieving superior performance compared to competitive methods. Our results highlight the potential of agent-driven evaluation systems to improve the factual reliability of LLM-generated summaries.