Multiple Choice Questions: Reasoning Makes Large Language Models (LLMs) More Self-Confident Even When They Are Wrong
作者: Tairan Fu, Javier Conde, Gonzalo Martínez, María Grandury, Pedro Reviriego
分类: cs.CL, cs.AI
发布日期: 2025-01-16 (更新: 2025-01-24)
💡 一句话要点
大语言模型在多选题中进行推理时,即使错误也更自信
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 多项选择题 思维链 置信度评估 推理 模型评估 提示工程
📋 核心要点
- 现有LLM评估方法依赖模型置信度判断正确性,但模型置信度可能存在偏差。
- 该研究探索了思维链推理对LLM回答多选题时置信度的影响。
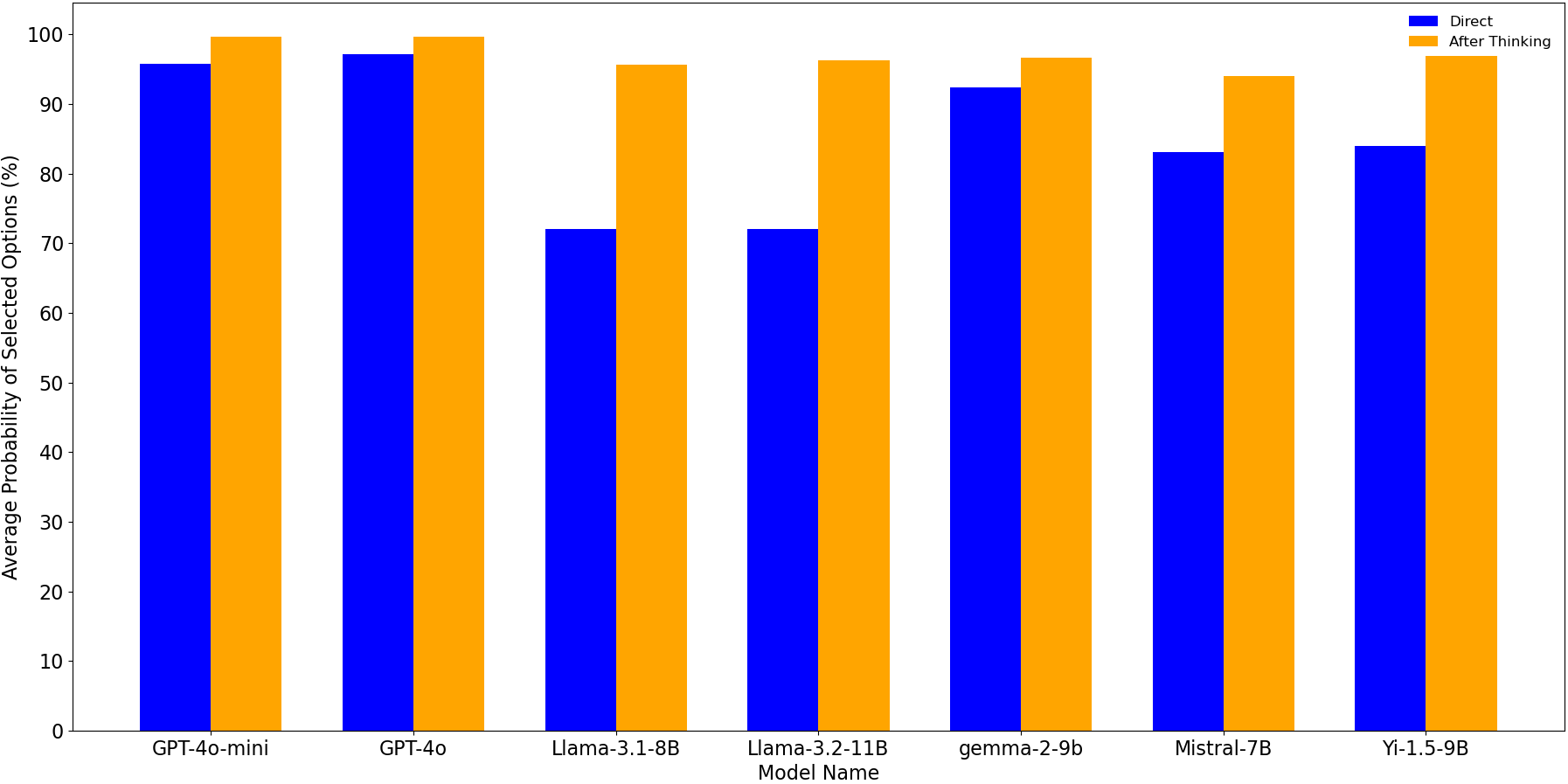
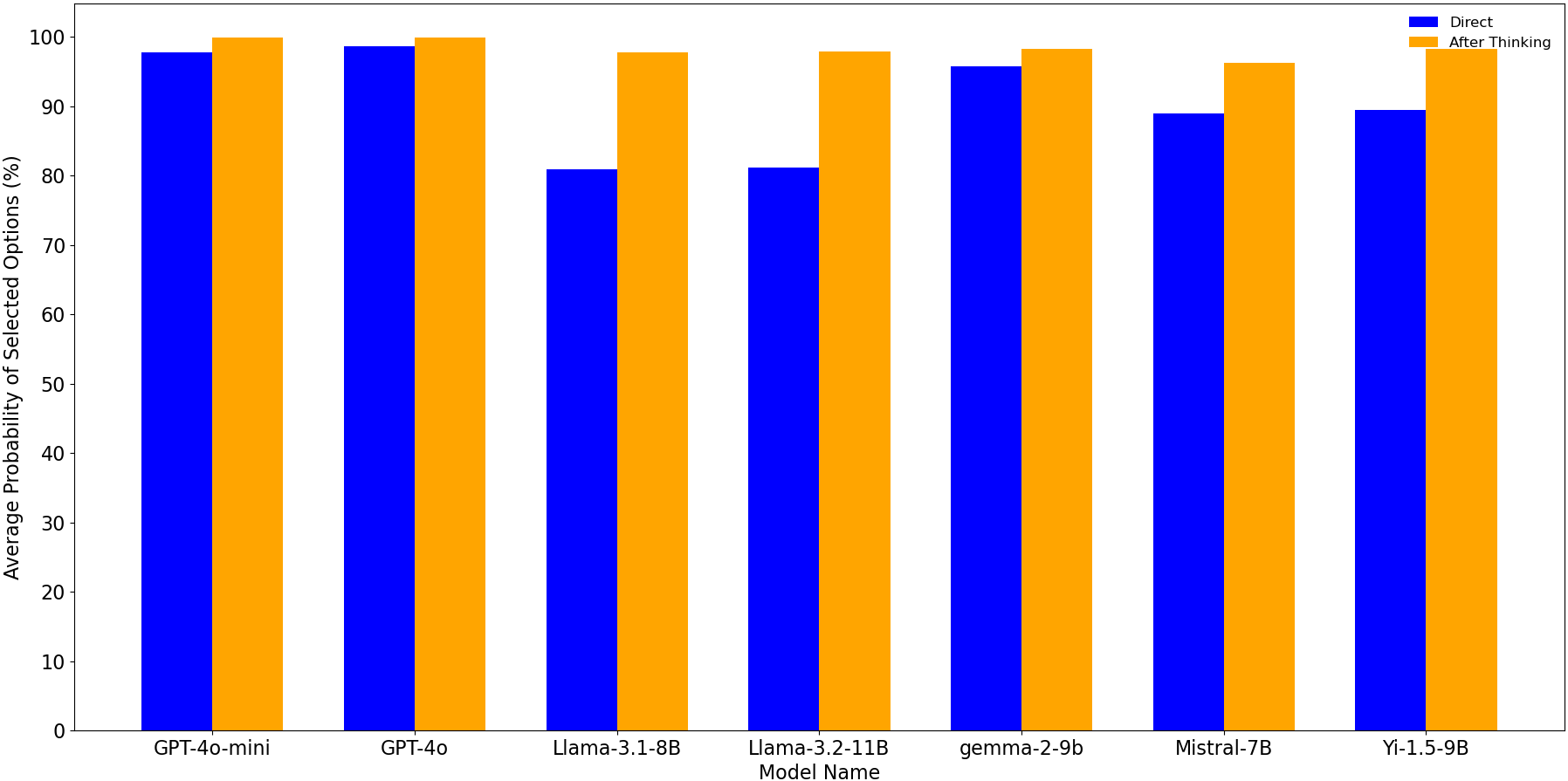
- 实验表明,推理过程会使LLM在回答错误时也表现出更高的置信度。
📝 摘要(中文)
多项选择题(MCQ)测试是评估大型语言模型(LLM)的常用方法。MCQ基准测试能够大规模地测试LLM在几乎任何主题上的知识,因为结果可以自动处理。为了帮助LLM回答,可以在提示中包含一些示例,称为few-shot。此外,可以要求LLM直接用所选选项回答问题,或者首先提供推理,然后提供所选答案,这被称为思维链。除了检查所选答案是否正确之外,评估还可以查看LLM估计的响应概率,以此作为LLM对响应的信心的指标。本文研究了LLM对其答案的信心如何取决于模型是被要求直接回答还是在回答之前提供推理。对七个不同模型中各种主题的问题进行评估的结果表明,当LLM在答案之前提供推理时,它们对答案更有信心。无论所选答案是否正确,都会发生这种情况。我们的假设是,这种行为是由于推理修改了所选答案的概率,因为LLM基于输入问题和支持所做选择的推理来预测答案。因此,LLM估计的概率似乎具有内在的局限性,应该理解这些局限性以便在评估程序中使用它们。有趣的是,在人类身上也观察到了相同的行为,对人类来说,解释一个答案会增加对其正确性的信心。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)在回答多项选择题(MCQ)时,其置信度与是否进行推理(思维链)之间的关系。现有方法依赖LLM的置信度来评估其答案的正确性,但这种置信度可能受到推理过程的影响,导致即使答案错误,模型也表现出高置信度。这使得单纯依赖置信度进行评估变得不可靠。
核心思路:论文的核心思路是探究思维链推理过程如何影响LLM对其答案的置信度。作者假设,推理过程会改变LLM对所选答案的概率估计,从而影响其置信度。即使推理过程导致了错误的答案,推理本身也会增强模型对该答案的信心。
技术框架:该研究主要通过实验进行。首先,选择多个LLM模型和涵盖广泛主题的多项选择题数据集。然后,设计两种不同的提示方式:一种是直接要求模型选择答案,另一种是要求模型先进行推理(思维链),再选择答案。最后,比较两种提示方式下,模型对答案的置信度(通过模型输出的概率估计来衡量)以及答案的正确率。
关键创新:该研究的关键创新在于揭示了思维链推理对LLM置信度的非预期影响。以往的研究通常认为,思维链推理可以提高LLM的准确率。然而,该研究表明,即使推理过程导致错误答案,它也会增加模型对该答案的置信度。这表明LLM的置信度评估存在内在局限性。
关键设计:实验的关键设计在于对比两种提示方式:直接回答和思维链推理。通过比较这两种方式下模型输出的概率分布,可以分析推理过程对模型置信度的影响。此外,实验还考虑了不同模型和不同主题的问题,以验证结论的普适性。没有涉及特定的损失函数或网络结构设计,重点在于提示工程和结果分析。
🖼️ 关键图片

📊 实验亮点
实验结果表明,当LLM在回答多项选择题之前进行推理时,无论答案是否正确,其对答案的置信度都会显著提高。这一现象在七个不同的LLM模型和各种主题的问题中都得到了验证。这表明LLM的置信度评估存在内在局限性,需要更谨慎地使用。
🎯 应用场景
该研究成果可应用于改进LLM的评估方法,避免过度依赖模型置信度。在实际应用中,例如智能客服、自动问答系统等,需要更谨慎地对待LLM给出的答案,尤其是在模型进行了推理的情况下。未来的研究可以探索如何校准LLM的置信度,使其更准确地反映答案的正确性。
📄 摘要(原文)
One of the most widely used methods to evaluate LLMs are Multiple Choice Question (MCQ) tests. MCQ benchmarks enable the testing of LLM knowledge on almost any topic at scale as the results can be processed automatically. To help the LLM answer, a few examples called few shots can be included in the prompt. Moreover, the LLM can be asked to answer the question directly with the selected option or to first provide the reasoning and then the selected answer, which is known as chain of thought. In addition to checking whether the selected answer is correct, the evaluation can look at the LLM-estimated probability of its response as an indication of the confidence of the LLM in the response. In this paper, we study how the LLM confidence in its answer depends on whether the model has been asked to answer directly or to provide the reasoning before answering. The results of the evaluation of questions on a wide range of topics in seven different models show that LLMs are more confident in their answers when they provide reasoning before the answer. This occurs regardless of whether the selected answer is correct. Our hypothesis is that this behavior is due to the reasoning that modifies the probability of the selected answer, as the LLM predicts the answer based on the input question and the reasoning that supports the selection made. Therefore, LLM estimated probabilities seem to have intrinsic limitations that should be understood in order to use them in evaluation procedures. Interestingly, the same behavior has been observed in humans, for whom explaining an answer increases confidence in its correctness.