OmniThink: Expanding Knowledge Boundaries in Machine Writing through Thinking
作者: Zekun Xi, Wenbiao Yin, Jizhan Fang, Jialong Wu, Runnan Fang, Yong Jiang, Pengjun Xie, Fei Huang, Huajun Chen, Ningyu Zhang
分类: cs.CL, cs.AI, cs.HC, cs.IR, cs.LG
发布日期: 2025-01-16 (更新: 2025-11-20)
备注: EMNLP 2025
🔗 代码/项目: GITHUB
💡 一句话要点
OmniThink:通过模拟人类思考过程,扩展机器写作的知识边界
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 机器写作 知识扩展 检索增强生成 慢思考 长文本生成
📋 核心要点
- 现有检索增强生成方法受限于模型预定义知识范围,导致生成内容缺乏深度和新颖性。
- OmniThink框架模拟人类学习过程,通过迭代扩展和反思来加深对主题的理解。
- 实验表明,OmniThink能有效提高生成文章的知识密度,同时保持连贯性和深度。
📝 摘要(中文)
大型语言模型的机器写作通常依赖于检索增强生成。然而,这些方法仍然局限于模型预定义范围内的知识,限制了富含信息的文章生成。具体而言,原始检索的信息往往缺乏深度、新颖性,并且存在冗余,从而对生成的文章质量产生负面影响,导致输出内容浅薄、缺乏原创性和重复性。为了解决这些问题,我们提出了OmniThink,一个慢思考的机器写作框架,它模拟了人类迭代扩展和反思的认知过程。OmniThink的核心思想是模拟学习者逐步加深对主题知识的认知行为。实验结果表明,OmniThink提高了生成文章的知识密度,同时不影响连贯性和深度等指标。人工评估和专家反馈进一步突出了OmniThink在解决长篇幅文章生成中的实际挑战的潜力。
🔬 方法详解
问题定义:论文旨在解决现有检索增强生成方法在机器写作中知识边界受限的问题。现有方法检索的信息往往缺乏深度、新颖性,并且存在冗余,导致生成的文章内容浅薄、缺乏原创性和重复性。这些问题严重影响了长篇幅文章的质量,限制了机器写作的实际应用价值。
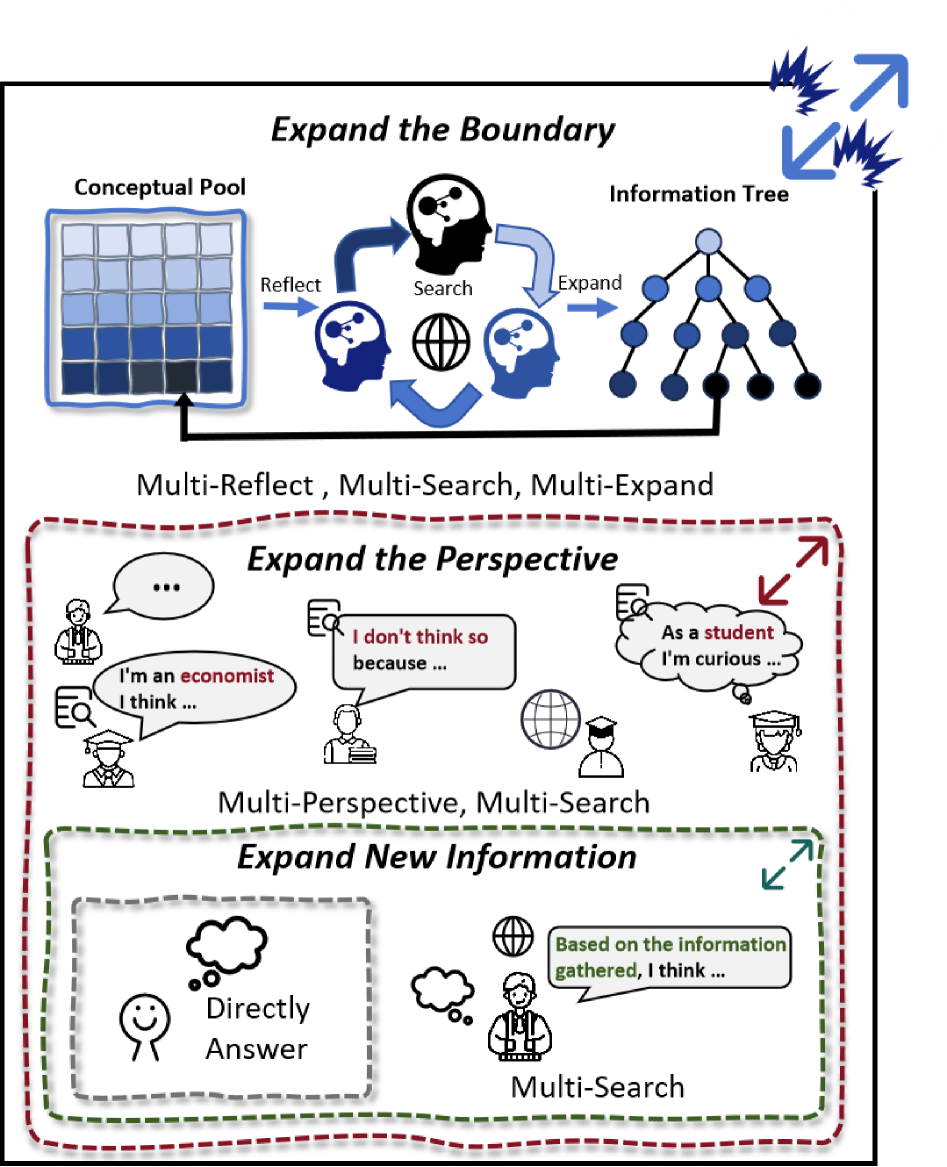
核心思路:OmniThink的核心思路是模拟人类学习和思考的过程,通过迭代式的知识扩展和反思,逐步加深对写作主题的理解。这种“慢思考”的方式旨在克服传统检索增强生成方法的局限性,生成更具深度、新颖性和信息量的文章。通过模拟人类认知过程,模型能够更好地整合和利用检索到的信息,避免简单复制和堆砌。
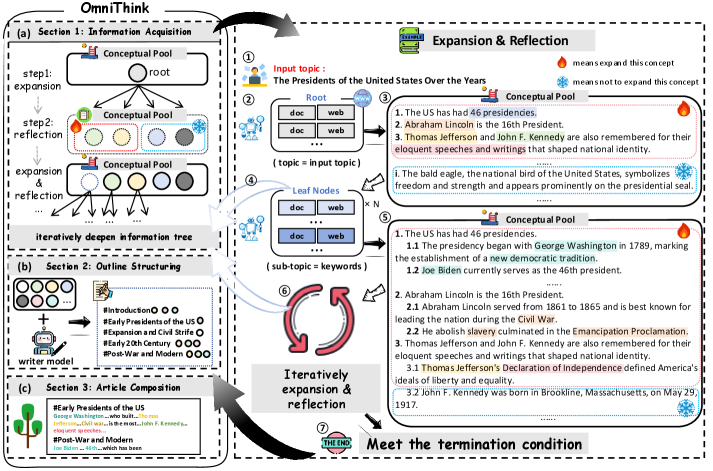
技术框架:OmniThink框架包含多个迭代阶段,每个阶段都包括知识扩展和反思两个主要步骤。在知识扩展阶段,模型利用检索工具获取与写作主题相关的更多信息。在反思阶段,模型对检索到的信息进行分析、整合和提炼,形成更深入的理解。然后,模型基于当前理解生成部分文章内容,并将其作为下一步迭代的输入。这个过程不断重复,直到生成完整的文章。
关键创新:OmniThink最重要的创新点在于其模拟人类思考的迭代式知识扩展和反思机制。与传统的检索增强生成方法不同,OmniThink不是简单地将检索到的信息拼接在一起,而是通过模拟人类的学习过程,逐步加深对主题的理解,从而生成更具深度和原创性的文章。这种方法能够有效地克服现有方法在知识边界和信息冗余方面的局限性。
关键设计:OmniThink框架的具体实现细节未知,论文中可能涉及的关键设计包括:知识扩展阶段使用的检索工具和策略,反思阶段使用的信息分析和整合算法,以及迭代过程中的停止条件和文章生成策略。此外,损失函数的设计可能也至关重要,例如,可以使用对比学习来鼓励模型生成更具新颖性和深度的内容。具体的网络结构和参数设置需要在论文的详细描述中查找。
🖼️ 关键图片

📊 实验亮点
实验结果表明,OmniThink能够显著提高生成文章的知识密度,同时保持良好的连贯性和深度。具体性能数据和对比基线未知,但人工评估和专家反馈表明,OmniThink在生成长篇幅文章方面具有显著优势,能够有效解决现有方法存在的知识边界和信息冗余问题。
🎯 应用场景
OmniThink具有广泛的应用前景,可用于自动生成新闻报道、学术论文、产品描述、创意写作等各种类型的长篇幅文章。该技术能够提高生成文章的质量和信息量,减少人工编辑的需求,从而提高写作效率和降低成本。未来,OmniThink有望成为智能写作领域的重要工具,为各行各业提供高质量的内容生成服务。
📄 摘要(原文)
Machine writing with large language models often relies on retrieval-augmented generation. However, these approaches remain confined within the boundaries of the model's predefined scope, limiting the generation of content with rich information. Specifically, vanilla-retrieved information tends to lack depth, novelty, and suffers from redundancy, which negatively impacts the quality of generated articles, leading to shallow, unoriginal, and repetitive outputs. To address these issues, we propose OmniThink, a slow-thinking machine writing framework that emulates the human-like process of iterative expansion and reflection. The core idea behind OmniThink is to simulate the cognitive behavior of learners as they slowly deepen their knowledge of the topics. Experimental results demonstrate that OmniThink improves the knowledge density of generated articles without compromising metrics such as coherence and depth. Human evaluations and expert feedback further highlight the potential of OmniThink to address real-world challenges in the generation of long-form articles. Code is available at https://github.com/zjunlp/OmniThink.