Enhancing Lexicon-Based Text Embeddings with Large Language Models
作者: Yibin Lei, Tao Shen, Yu Cao, Andrew Yates
分类: cs.CL, cs.IR
发布日期: 2025-01-16
💡 一句话要点
提出基于LLM的词典嵌入LENS,提升文本嵌入性能并保持紧凑表示
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本嵌入 大型语言模型 词典嵌入 双向注意力 token聚类
📋 核心要点
- 现有稠密嵌入方法在文本嵌入任务中占据主导地位,但缺乏对词汇信息的有效利用,且模型复杂度较高。
- LENS通过token嵌入聚类减少冗余,利用双向注意力克服单向限制,并结合词典信息,提升嵌入质量。
- 实验表明,LENS在MTEB上超越稠密嵌入,并能与稠密嵌入结合,在BEIR检索任务上达到SOTA。
📝 摘要(中文)
本文提出了一种基于大型语言模型(LLMs)的词典嵌入方法LENS,旨在实现与通用文本嵌入任务上具有竞争力的性能。针对传统因果LLM中固有的tokenization冗余问题和单向注意力限制,LENS通过token嵌入聚类来整合词汇空间,并研究了双向注意力和各种池化策略。具体而言,LENS通过将每个维度分配给特定的token簇来简化词典匹配,其中语义相似的token被分组在一起,并通过双向注意力释放LLM的全部潜力。大量实验表明,LENS在Massive Text Embedding Benchmark (MTEB)上优于密集嵌入,并提供了与密集嵌入大小相匹配的紧凑特征表示。值得注意的是,将LENS与密集嵌入相结合,在MTEB的检索子集(即BEIR)上实现了最先进的性能。
🔬 方法详解
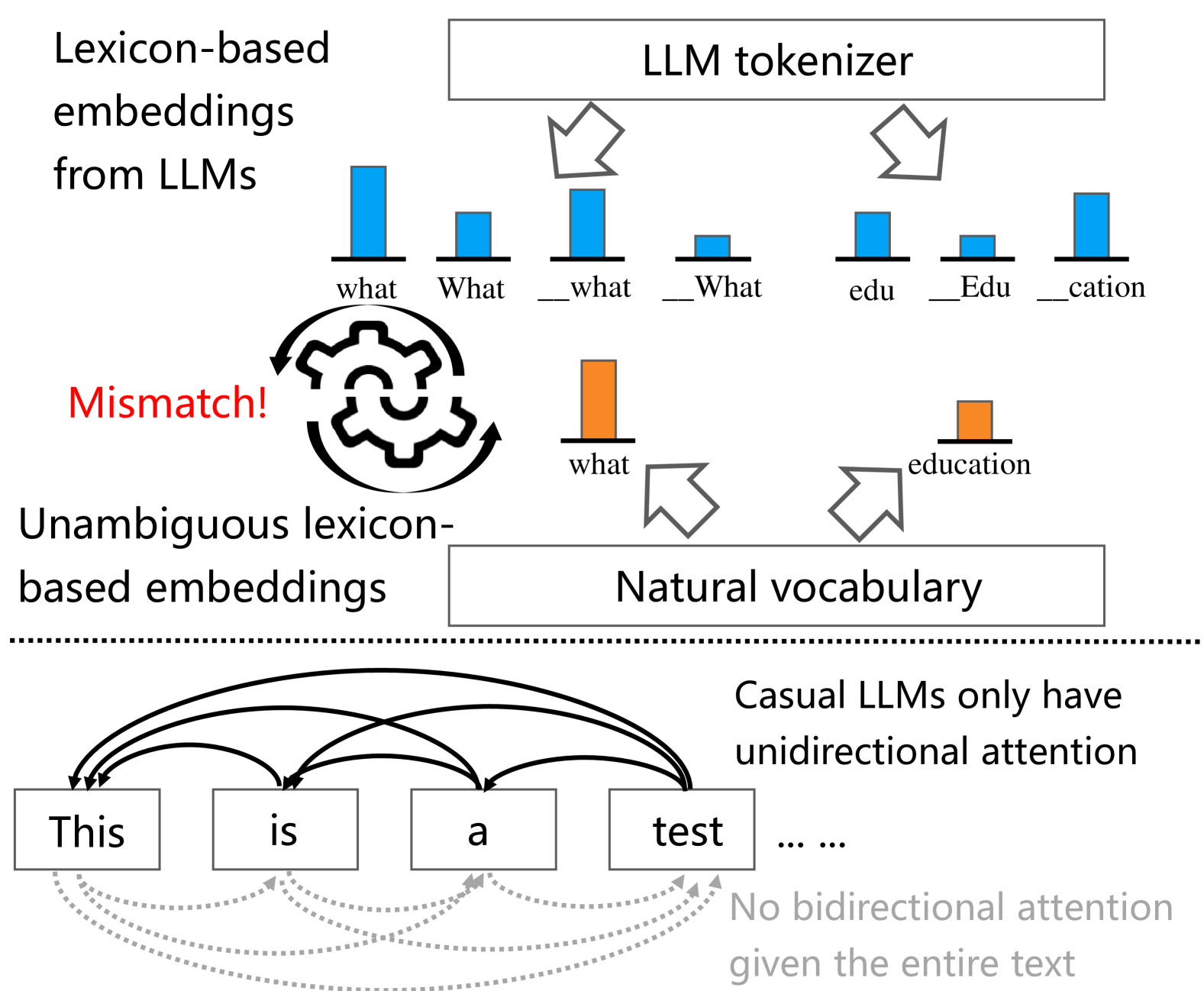
问题定义:现有基于大型语言模型的文本嵌入方法,特别是因果语言模型,存在tokenization冗余和单向注意力机制的局限性。Tokenization冗余导致词汇空间膨胀,增加了计算负担。单向注意力无法充分捕捉上下文信息,影响嵌入质量。此外,如何有效利用词典信息也是一个挑战。
核心思路:LENS的核心思路是利用token嵌入聚类来压缩词汇空间,并采用双向注意力机制来增强上下文理解。通过将语义相似的token聚类到一起,减少了冗余,并简化了词典匹配过程。双向注意力机制允许模型同时关注上下文信息,从而更准确地捕捉文本的语义。
技术框架:LENS的整体框架包括以下几个主要模块:1) Token嵌入聚类:使用聚类算法将LLM的token嵌入进行分组,形成token簇。2) 词典匹配:将每个维度分配给一个特定的token簇,从而简化词典匹配过程。3) 双向注意力:采用双向注意力机制,允许模型同时关注上下文信息。4) 池化策略:研究不同的池化策略,以获得最终的文本嵌入表示。
关键创新:LENS的关键创新在于:1) 首次将词典信息融入到基于LLM的文本嵌入中,实现了词典嵌入与LLM的有效结合。2) 通过token嵌入聚类来压缩词汇空间,减少了冗余,提高了效率。3) 采用双向注意力机制,增强了上下文理解能力,提升了嵌入质量。
关键设计:在token嵌入聚类方面,论文采用了k-means算法,并根据实验结果选择了合适的簇数量。在双向注意力机制方面,论文采用了标准的Transformer架构。在池化策略方面,论文研究了平均池化、最大池化等多种策略,并根据实验结果选择了最佳的池化方法。损失函数采用对比学习损失,以拉近语义相似的文本的嵌入表示,推远语义不相似的文本的嵌入表示。
🖼️ 关键图片


📊 实验亮点
实验结果表明,LENS在MTEB基准测试中优于现有的稠密嵌入方法,尤其是在检索任务上表现突出。LENS在保持与稠密嵌入相当大小的特征表示的同时,取得了更好的性能。将LENS与稠密嵌入相结合,在BEIR检索任务上实现了SOTA,证明了LENS的有效性和互补性。
🎯 应用场景
LENS可应用于各种文本检索、文本分类、语义相似度计算等自然语言处理任务。其紧凑的特征表示使其在资源受限的环境中也具有优势。未来可进一步探索LENS在知识图谱构建、信息抽取等领域的应用,并研究如何将LENS与其他类型的嵌入方法相结合,以获得更好的性能。
📄 摘要(原文)
Recent large language models (LLMs) have demonstrated exceptional performance on general-purpose text embedding tasks. While dense embeddings have dominated related research, we introduce the first Lexicon-based EmbeddiNgS (LENS) leveraging LLMs that achieve competitive performance on these tasks. Regarding the inherent tokenization redundancy issue and unidirectional attention limitations in traditional causal LLMs, LENS consolidates the vocabulary space through token embedding clustering, and investigates bidirectional attention and various pooling strategies. Specifically, LENS simplifies lexicon matching by assigning each dimension to a specific token cluster, where semantically similar tokens are grouped together, and unlocking the full potential of LLMs through bidirectional attention. Extensive experiments demonstrate that LENS outperforms dense embeddings on the Massive Text Embedding Benchmark (MTEB), delivering compact feature representations that match the sizes of dense counterparts. Notably, combining LENSE with dense embeddings achieves state-of-the-art performance on the retrieval subset of MTEB (i.e. BEIR).