Suggesting Code Edits in Interactive Machine Learning Notebooks Using Large Language Models
作者: Bihui Jin, Jiayue Wang, Pengyu Nie
分类: cs.SE, cs.CL, cs.LG
发布日期: 2025-01-16
💡 一句话要点
提出基于大型语言模型的交互式机器学习Notebook代码编辑建议方法与数据集。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 代码编辑 大型语言模型 Jupyter Notebook 机器学习 数据集 代码维护 交互式编程
📋 核心要点
- 交互式Notebook维护困难,缺乏针对Notebook编辑的基准数据集,阻碍了自动化代码编辑工具的发展。
- 利用大型语言模型预测Notebook代码编辑,构建包含单元格和行级别修改信息的Jupyter Notebook编辑数据集。
- 实验表明,现有模型在真实场景下的Notebook代码编辑任务中表现不佳,强调了上下文信息的重要性。
📝 摘要(中文)
本文提出了首个Jupyter Notebook代码编辑数据集,该数据集包含从GitHub上792个机器学习仓库的20,095个修订版本中提取的48,398个Jupyter Notebook编辑。该数据集捕捉了单元格级别和行级别的修改细节,为理解机器学习工作流程中的真实维护模式奠定了基础。研究发现,Jupyter Notebook上的编辑具有高度局部性,仓库中平均只有166行代码发生更改。尽管较大的模型在代码编辑方面优于较小的模型,但即使经过微调,所有模型在本文提出的数据集上的准确率仍然较低,这表明真实机器学习维护任务的复杂性。研究结果强调了上下文信息在提高模型性能方面的关键作用,并为推进大型语言模型在工程化机器学习代码方面的能力指明了有希望的途径。
🔬 方法详解
问题定义:论文旨在解决机器学习开发者在使用Jupyter Notebook进行数据处理和模型训练时,维护Notebook代码(例如添加新功能或修复错误)的挑战。现有的方法缺乏针对Jupyter Notebook代码编辑的基准数据集,难以评估和改进自动化代码编辑工具的性能。
核心思路:论文的核心思路是利用大型语言模型(LLMs)来预测Jupyter Notebook中的代码编辑,并构建一个大规模的Jupyter Notebook编辑数据集,以促进相关研究。通过分析真实世界中的Notebook编辑模式,可以更好地理解开发者在维护机器学习代码时的行为,并为LLMs提供更有效的训练数据。
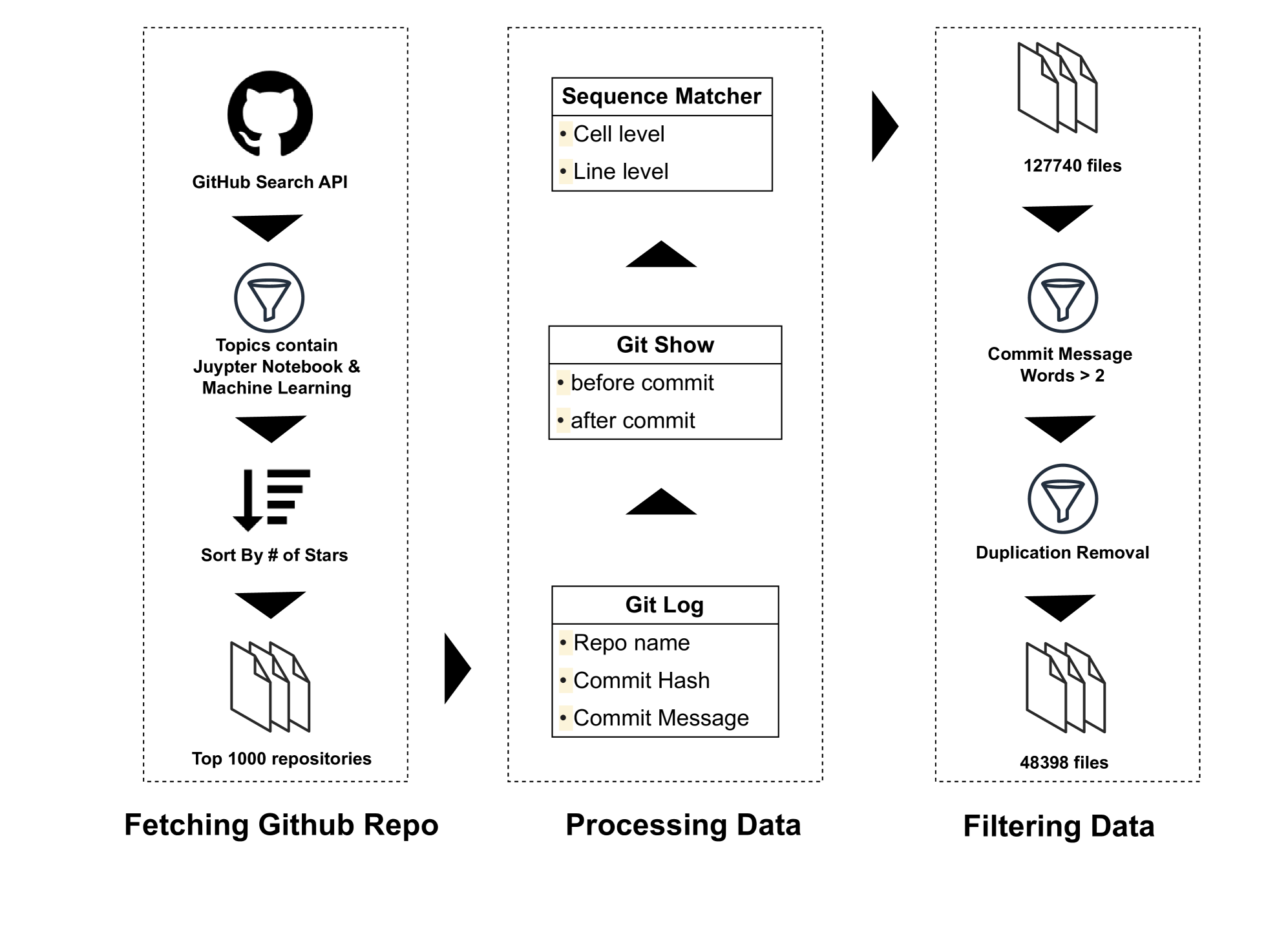
技术框架:该研究主要包含两个部分:数据集构建和模型评估。数据集构建部分,从GitHub上的机器学习仓库中提取Jupyter Notebook的修订历史,并解析出单元格级别和行级别的代码修改。模型评估部分,使用大型语言模型(包括不同大小的模型)在构建的数据集上进行微调,并评估其在代码编辑任务上的性能。
关键创新:该论文的关键创新在于:1)构建了首个大规模的Jupyter Notebook代码编辑数据集,为相关研究提供了基准;2)首次尝试使用大型语言模型来预测Jupyter Notebook中的代码编辑,并分析了现有模型在真实场景下的性能瓶颈。
关键设计:数据集构建的关键设计包括:1)选择包含机器学习相关代码的GitHub仓库;2)提取Jupyter Notebook的修订历史;3)解析出单元格级别和行级别的代码修改,并进行清洗和过滤。模型评估的关键设计包括:1)选择不同大小的大型语言模型;2)使用构建的数据集对模型进行微调;3)使用准确率等指标评估模型在代码编辑任务上的性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,即使经过微调,现有的大型语言模型在Jupyter Notebook代码编辑数据集上的准确率仍然较低,这表明真实机器学习维护任务的复杂性。研究发现,Jupyter Notebook上的编辑具有高度局部性,仓库中平均只有166行代码发生更改。虽然较大的模型通常优于较小的模型,但所有模型都未能达到令人满意的性能,突出了上下文信息在提高模型性能方面的重要性。
🎯 应用场景
该研究成果可应用于自动化代码编辑工具的开发,帮助机器学习开发者更高效地维护和更新Jupyter Notebook。通过利用大型语言模型预测代码编辑,可以减少手动修改代码的工作量,提高开发效率。此外,该数据集可以作为机器学习代码维护模式研究的基础,为开发更智能的开发工具提供支持。
📄 摘要(原文)
Machine learning developers frequently use interactive computational notebooks, such as Jupyter notebooks, to host code for data processing and model training. Jupyter notebooks provide a convenient tool for writing machine learning pipelines and interactively observing outputs, however, maintaining Jupyter notebooks, e.g., to add new features or fix bugs, can be challenging due to the length and complexity of the notebooks. Moreover, there is no existing benchmark related to developer edits on Jupyter notebooks. To address this, we present the first dataset of 48,398 Jupyter notebook edits derived from 20,095 revisions of 792 machine learning repositories on GitHub, and perform the first study of the using LLMs to predict code edits in Jupyter notebooks. Our dataset captures granular details of cell-level and line-level modifications, offering a foundation for understanding real-world maintenance patterns in machine learning workflows. We observed that the edits on Jupyter notebooks are highly localized, with changes averaging only 166 lines of code in repositories. While larger models outperform smaller counterparts in code editing, all models have low accuracy on our dataset even after finetuning, demonstrating the complexity of real-world machine learning maintenance tasks. Our findings emphasize the critical role of contextual information in improving model performance and point toward promising avenues for advancing large language models' capabilities in engineering machine learning code.