Domain Adaptation of Foundation LLMs for e-Commerce
作者: Christian Herold, Michael Kozielski, Tala Bazazo, Pavel Petrushkov, Patrycja Cieplicka, Dominika Basaj, Yannick Versley, Seyyed Hadi Hashemi, Shahram Khadivi
分类: cs.CL
发布日期: 2025-01-16 (更新: 2025-05-25)
备注: Accepted at ACL25 (Industry )
💡 一句话要点
提出e-Llama,通过领域自适应提升LLM在电商领域的性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 电商领域 领域自适应 大型语言模型 持续预训练 Llama 3.1 多语言评估 知识迁移
📋 核心要点
- 现有LLM在电商领域知识不足,难以满足电商场景的特定需求。
- 通过在Llama 3.1上进行持续预训练,注入大量电商领域数据,构建e-Llama模型。
- 实验表明,e-Llama在电商领域表现出色,且通用领域性能未明显下降。
📝 摘要(中文)
本文介绍了e-Llama模型,这是一组针对电商领域进行自适应的80亿和700亿参数的大型语言模型。这些模型旨在作为具有深厚电商知识的基础模型,为指令微调和精细调整提供基础。e-Llama模型通过在Llama 3.1基础模型上持续预训练1万亿个领域特定token获得。本文讨论了该方法,并通过一系列消融研究来论证超参数选择的合理性。为了量化模型对电商领域的适应程度,定义并实现了一组多语言、电商特定的评估任务。结果表明,通过仔细选择训练设置,Llama 3.1模型可以适应新领域,而不会牺牲通用领域任务的显著性能。本文还探讨了合并自适应模型和基础模型的可能性,以便更好地控制领域之间的性能权衡。
🔬 方法详解
问题定义:论文旨在解决通用大型语言模型(LLM)在电子商务领域知识不足的问题。现有LLM虽然在通用任务上表现出色,但在处理电商相关的特定任务时,例如商品描述理解、用户意图识别、多语言电商信息处理等方面,表现往往不尽如人意。痛点在于缺乏针对电商领域的专业知识和理解能力。
核心思路:论文的核心思路是通过领域自适应(Domain Adaptation)的方法,将一个预训练好的通用LLM(Llama 3.1)迁移到电商领域。具体而言,通过在大量的电商领域数据上进行持续预训练,使模型学习到电商领域的特定知识和语言模式。这样,模型就能更好地理解和处理电商相关的任务。
技术框架:整体框架包括以下几个主要阶段:1) 选择Llama 3.1作为基础模型。2) 收集并清洗大规模电商领域数据,包括商品描述、用户评论、搜索查询等。3) 在Llama 3.1上进行持续预训练,使用电商领域数据进行训练。4) 定义并实现一套多语言、电商特定的评估任务,用于评估模型在电商领域的性能。5) 进行消融研究,优化训练超参数。6) 探索合并自适应模型和基础模型的方法,以平衡领域性能和通用性能。
关键创新:论文的关键创新在于针对电商领域的领域自适应方法。与直接从头训练一个LLM相比,领域自适应可以利用已有的通用LLM的知识,从而更快地获得在特定领域的良好性能。此外,论文还提出了针对电商领域的多语言评估任务,为评估模型在电商领域的性能提供了标准。
关键设计:论文的关键设计包括:1) 使用Llama 3.1作为基础模型,因为它具有良好的通用性能和开源特性。2) 收集了1万亿个token的电商领域数据,保证了训练数据的规模和质量。3) 通过消融研究,优化了训练超参数,例如学习率、batch size等。4) 探索了合并自适应模型和基础模型的方法,例如使用加权平均或知识蒸馏等技术,以平衡领域性能和通用性能。
🖼️ 关键图片
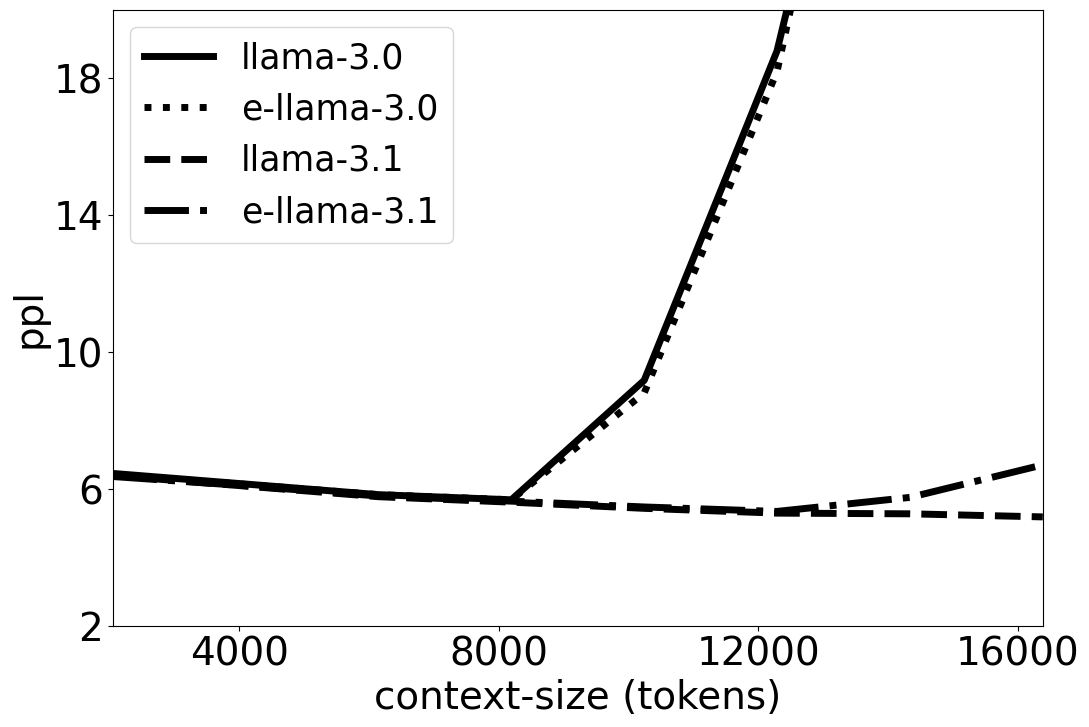
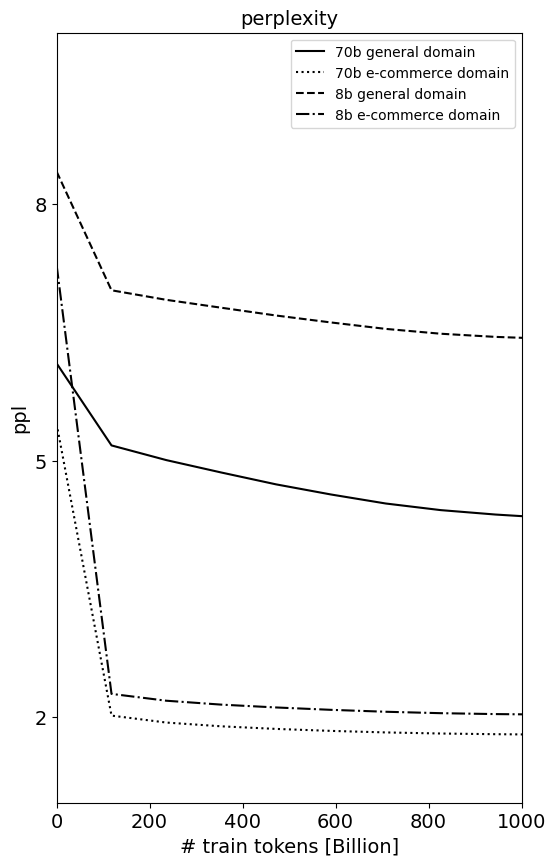
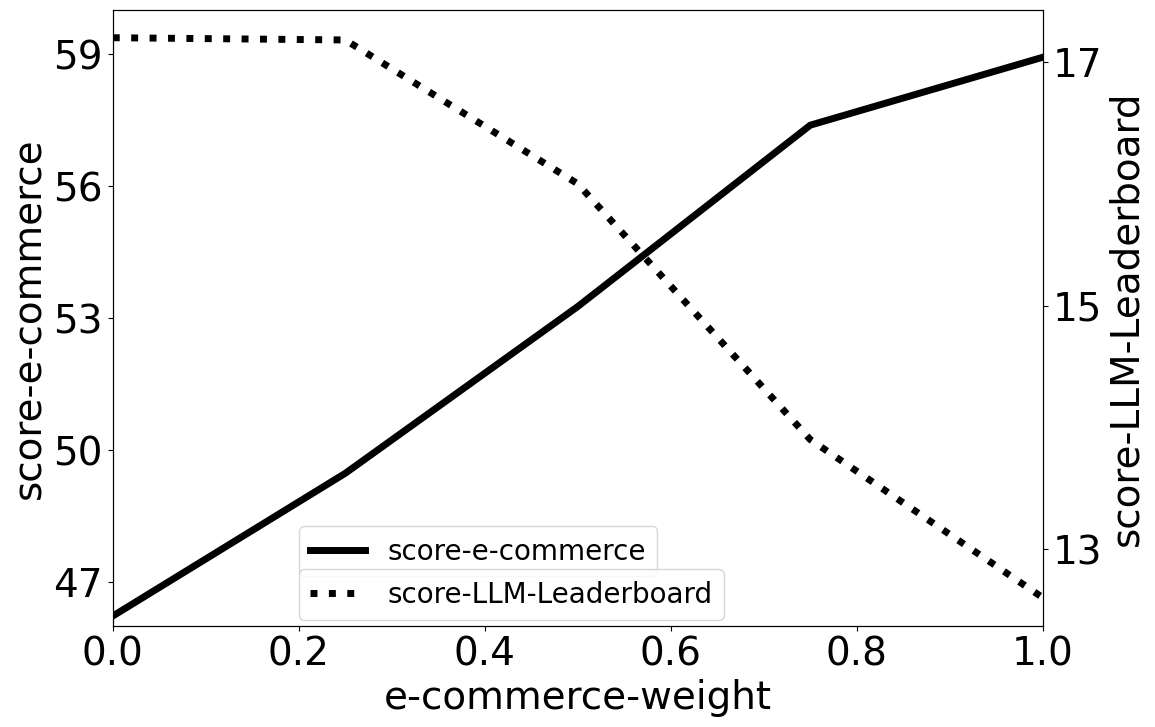
📊 实验亮点
实验结果表明,经过领域自适应后,e-Llama模型在电商特定任务上取得了显著的性能提升,同时在通用任务上的性能损失较小。通过仔细选择训练设置,Llama 3.1模型可以适应新领域,而不会牺牲通用领域任务的显著性能。论文还探索了合并自适应模型和基础模型的方法,以便更好地控制领域之间的性能权衡。
🎯 应用场景
该研究成果可广泛应用于电商领域的各种任务,如商品描述生成、用户意图理解、智能客服、搜索推荐等。通过提升LLM在电商领域的理解和生成能力,可以提高电商平台的运营效率和服务质量,改善用户体验,并为商家提供更智能的营销工具。未来,该技术有望应用于跨境电商、个性化推荐等更复杂的场景。
📄 摘要(原文)
We present the e-Llama models: 8 billion and 70 billion parameter large language models that are adapted towards the e-commerce domain. These models are meant as foundation models with deep knowledge about e-commerce, that form a base for instruction- and fine-tuning. The e-Llama models are obtained by continuously pretraining the Llama 3.1 base models on 1 trillion tokens of domain-specific data. We discuss our approach and motivate our choice of hyperparameters with a series of ablation studies. To quantify how well the models have been adapted to the e-commerce domain, we define and implement a set of multilingual, e-commerce specific evaluation tasks. We show that, when carefully choosing the training setup, the Llama 3.1 models can be adapted towards the new domain without sacrificing significant performance on general domain tasks. We also explore the possibility of merging the adapted model and the base model for a better control of the performance trade-off between domains.