Delayed Fusion: Integrating Large Language Models into First-Pass Decoding in End-to-end Speech Recognition
作者: Takaaki Hori, Martin Kocour, Adnan Haider, Erik McDermott, Xiaodan Zhuang
分类: cs.CL, cs.SD, eess.AS
发布日期: 2025-01-16
备注: Accepted to ICASSP2025
💡 一句话要点
提出延迟融合方法,解决端到端语音识别中LLM集成难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 端到端语音识别 大型语言模型 延迟融合 浅融合 解码算法 语音识别
📋 核心要点
- 现有浅融合方法在E2E-ASR中集成LLM时,面临LLM推理成本高昂和词汇不匹配两大挑战。
- 论文提出“延迟融合”策略,在解码过程中延迟应用LLM评分,减少LLM调用次数并支持不同分词方式。
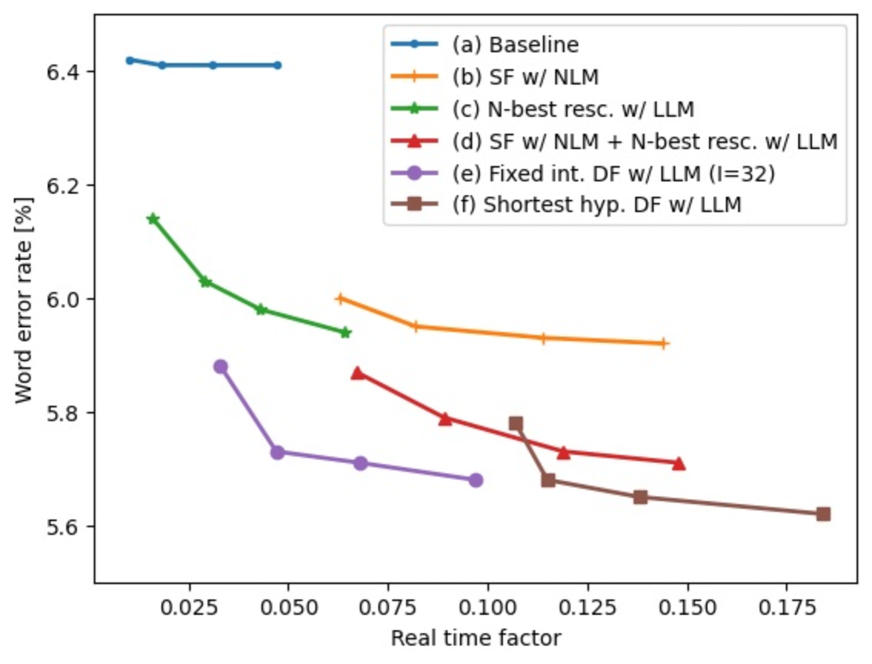
- 实验表明,延迟融合在LibriHeavy数据集上,相较于浅融合和N-best重打分,提升了解码速度和准确性。
📝 摘要(中文)
本文提出了一种高效的解码方法,用于将大型语言模型(LLM)集成到端到端自动语音识别(E2E-ASR)中。尽管浅融合是目前将语言模型融入E2E-ASR解码的最常用方法,但我们在LLM的应用中面临两个实际问题:(1)LLM推理的计算成本很高;(2)ASR模型和LLM之间可能存在词汇不匹配。为了解决这种不匹配,我们需要重新训练ASR模型和/或LLM,这非常耗时,而且在许多情况下是不可行的。我们提出了“延迟融合”,该方法在解码过程中延迟应用LLM分数到ASR假设,从而更容易在ASR任务中使用预训练的LLM。这种方法不仅可以减少LLM评分的假设数量,还可以减少LLM推理调用的次数。如果ASR和LLM采用不同的分词方式,它还允许在解码过程中重新标记ASR假设。我们证明,与使用LibriHeavy ASR语料库和三个公共LLM(OpenLLaMA 3B & 7B 和 Mistral 7B)的浅融合和N-best重打分相比,延迟融合提供了更高的解码速度和准确性。
🔬 方法详解
问题定义:现有端到端语音识别(E2E-ASR)系统集成大型语言模型(LLM)时,主要采用浅融合方法。然而,LLM的计算开销巨大,导致解码速度慢。此外,ASR模型和LLM可能使用不同的词汇表,直接融合会导致性能下降,需要耗时地重新训练模型。
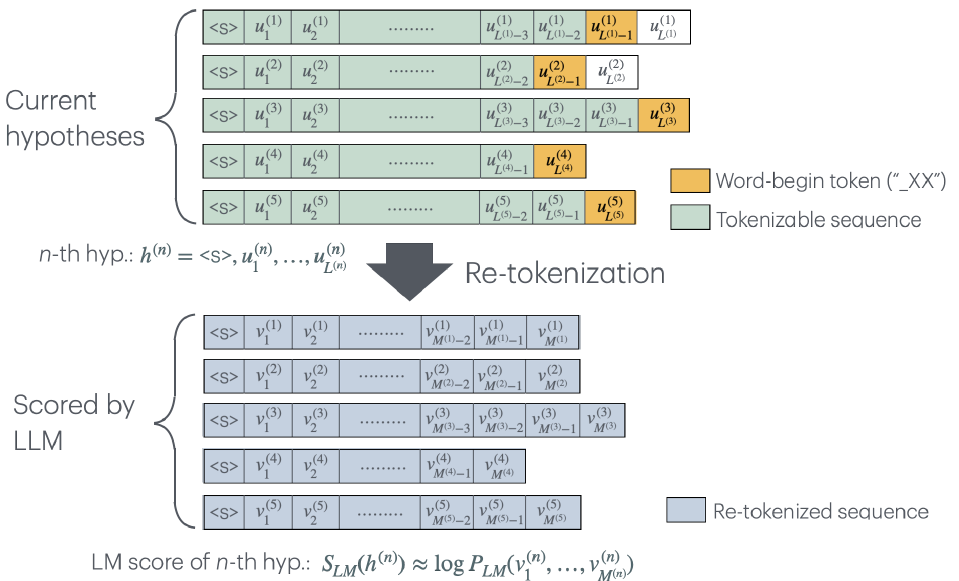
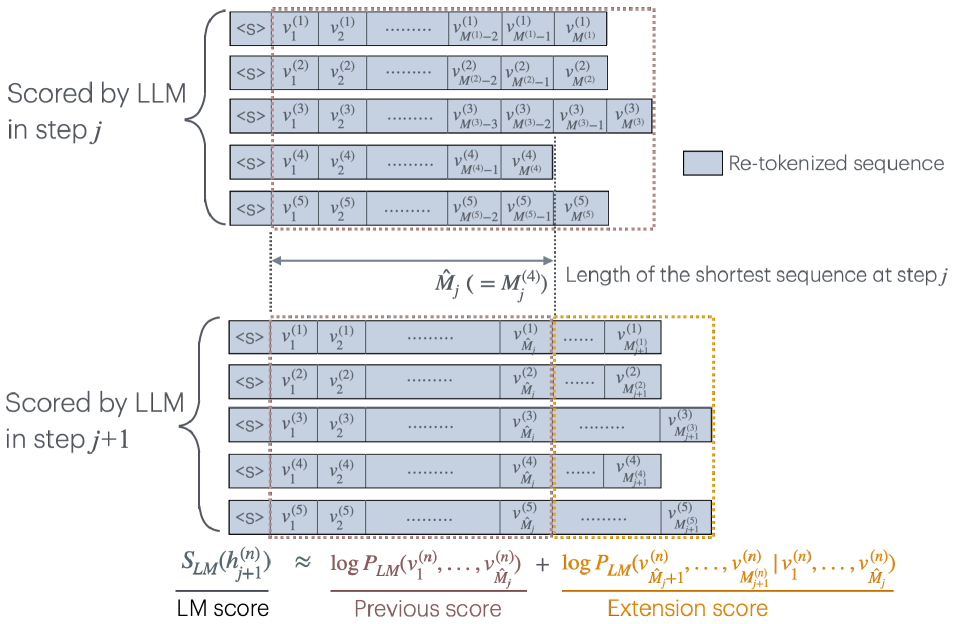
核心思路:论文的核心思路是“延迟融合”,即在ASR解码的早期阶段,先使用计算成本较低的ASR模型进行初步解码,生成候选假设。然后,仅对这些候选假设进行LLM评分,从而显著减少LLM的调用次数,降低计算成本。同时,延迟融合允许在LLM评分前对ASR假设进行重新分词,以解决词汇不匹配问题。
技术框架:整体框架包含以下步骤:1) ASR模型进行第一遍解码,生成N个候选假设;2) 对ASR假设进行重新分词,使其与LLM的词汇表匹配;3) 使用LLM对重新分词后的假设进行评分;4) 将LLM的评分与ASR模型的评分进行融合,得到最终的解码结果。
关键创新:最重要的创新点在于延迟应用LLM评分,避免了对所有可能的假设都进行昂贵的LLM推理。与传统的浅融合方法相比,延迟融合显著降低了计算复杂度,同时通过重新分词解决了词汇不匹配问题,使得预训练的LLM能够更容易地应用于ASR任务。
关键设计:关键设计包括:1) 确定何时应用LLM评分的延迟策略,需要在计算成本和解码精度之间进行权衡;2) 设计高效的重新分词算法,将ASR假设转换为LLM可理解的格式;3) 选择合适的融合策略,将ASR模型和LLM的评分进行有效结合,例如加权平均或更复杂的模型。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在LibriHeavy数据集上,延迟融合方法在使用OpenLLaMA 3B & 7B 和 Mistral 7B等LLM时,相较于浅融合和N-best重打分,显著提升了解码速度和准确性。具体性能数据(例如字错误率WER的降低幅度)在论文中进行了详细展示,证明了该方法的有效性。
🎯 应用场景
该研究成果可广泛应用于各种语音识别场景,尤其是在计算资源有限或需要快速响应的场景下,例如移动设备上的语音助手、实时语音翻译等。通过延迟融合,可以更高效地利用大型语言模型提升语音识别的准确性,并降低部署成本,推动语音交互技术的普及。
📄 摘要(原文)
This paper presents an efficient decoding approach for end-to-end automatic speech recognition (E2E-ASR) with large language models (LLMs). Although shallow fusion is the most common approach to incorporate language models into E2E-ASR decoding, we face two practical problems with LLMs. (1) LLM inference is computationally costly. (2) There may be a vocabulary mismatch between the ASR model and the LLM. To resolve this mismatch, we need to retrain the ASR model and/or the LLM, which is at best time-consuming and in many cases not feasible. We propose "delayed fusion," which applies LLM scores to ASR hypotheses with a delay during decoding and enables easier use of pre-trained LLMs in ASR tasks. This method can reduce not only the number of hypotheses scored by the LLM but also the number of LLM inference calls. It also allows re-tokenizion of ASR hypotheses during decoding if ASR and LLM employ different tokenizations. We demonstrate that delayed fusion provides improved decoding speed and accuracy compared to shallow fusion and N-best rescoring using the LibriHeavy ASR corpus and three public LLMs, OpenLLaMA 3B & 7B and Mistral 7B.