FineMedLM-o1: Enhancing Medical Knowledge Reasoning Ability of LLM from Supervised Fine-Tuning to Test-Time Training
作者: Hongzhou Yu, Tianhao Cheng, Yingwen Wang, Wen He, Qing Wang, Ying Cheng, Yuejie Zhang, Rui Feng, Xiaobo Zhang
分类: cs.CL
发布日期: 2025-01-16 (更新: 2025-07-30)
💡 一句话要点
FineMedLM-o1:通过监督微调与测试时训练提升LLM的医学知识推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学大型语言模型 监督微调 直接偏好优化 测试时训练 医学对话合成 知识推理 领域自适应
📋 核心要点
- 现有医学LLM在深度推理方面存在不足,难以应对复杂医学问题,如鉴别诊断和药物推荐。
- FineMedLM-o1通过高质量医学合成数据进行SFT和DPO,并创新性地引入TTT,提升模型推理能力。
- 实验表明,FineMedLM-o1在医学基准测试中性能显著提升,TTT进一步增强了模型的推理能力。
📝 摘要(中文)
本文提出FineMedLM-o1,旨在提升大型语言模型(LLM)在医学领域的知识推理能力,特别是在疾病诊断和治疗方案规划等复杂医学问题上。该模型利用高质量的医学合成数据和长文本推理数据进行监督微调(SFT)和直接偏好优化(DPO),从而实现高级对话和深度推理能力。此外,首次在医学领域引入测试时训练(TTT),以促进领域自适应并确保可靠、准确的推理。实验结果表明,FineMedLM-o1在关键医学基准测试中,相比之前的模型平均性能提升了23%。TTT的引入进一步提升了14%的性能,突显了其在增强医学推理能力方面的有效性。为了支持这一过程,还提出了一种新的医学对话合成方法。与其它开源数据集相比,该数据集在质量和复杂性方面都表现出优越性。项目和数据将在GitHub上发布。
🔬 方法详解
问题定义:现有医学大型语言模型在处理需要深度推理的复杂医学问题时表现不佳,例如在进行鉴别诊断或给出药物推荐时,无法充分利用医学知识进行有效推理。这主要是因为缺乏高质量的医学训练数据,以及模型在特定医学领域的适应性不足。
核心思路:本文的核心思路是通过高质量的医学合成数据和长文本推理数据,对LLM进行监督微调(SFT)和直接偏好优化(DPO),从而增强其医学知识和推理能力。此外,引入测试时训练(TTT)机制,使模型能够在实际应用中进一步适应特定领域的医学数据,从而提高推理的准确性和可靠性。
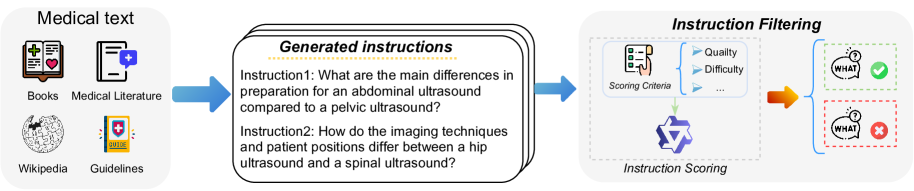
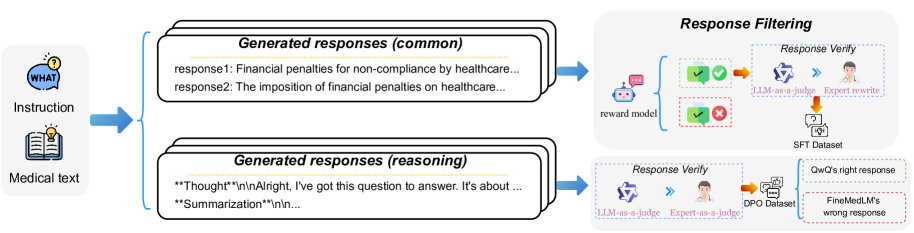
技术框架:FineMedLM-o1的训练流程主要包括以下几个阶段:1) 医学合成数据生成:使用一种新的方法合成高质量的医学对话数据。2) 监督微调(SFT):使用合成数据对LLM进行微调,使其具备基本的医学知识和对话能力。3) 直接偏好优化(DPO):使用长文本推理数据,通过DPO算法优化模型的推理能力。4) 测试时训练(TTT):在实际应用场景中,使用少量真实医学数据对模型进行微调,使其适应特定领域的医学数据。
关键创新:该论文的关键创新点包括:1) 提出了一种新的医学对话合成方法,生成了高质量的医学训练数据。2) 首次在医学领域引入了测试时训练(TTT)机制,使模型能够在实际应用中进一步适应特定领域的医学数据。3) 结合SFT、DPO和TTT,构建了一个完整的医学LLM训练框架。
关键设计:在数据合成方面,论文提出了一种新颖的医学对话合成方法,具体细节未知。在TTT方面,使用了少量真实医学数据对模型进行微调,微调的具体参数设置和损失函数未知。DPO 算法的具体实现细节也未知,但其目标是优化模型的推理能力。
🖼️ 关键图片

📊 实验亮点
实验结果表明,FineMedLM-o1在关键医学基准测试中,相比之前的模型平均性能提升了23%。引入测试时训练(TTT)后,性能进一步提升了14%,证明了TTT在增强医学推理能力方面的有效性。此外,论文提出的医学对话合成方法生成的数据集在质量和复杂性方面优于其他开源数据集。
🎯 应用场景
FineMedLM-o1具有广泛的应用前景,可用于辅助医生进行疾病诊断、制定治疗方案、提供药物推荐等。该模型可以作为智能医疗助手,提高医疗效率和质量,尤其是在医疗资源匮乏的地区,可以为患者提供远程医疗服务。未来,该模型有望应用于医学教育、科研等领域,促进医学知识的传播和创新。
📄 摘要(原文)
Recent advancements in large language models (LLMs) have shown promise in medical applications such as disease diagnosis and treatment planning. However, most existing medical LLMs struggle with the deep reasoning required for complex medical problems, such as differential diagnosis and medication recommendations. We propose FineMedLM-o1, which leverages high-quality medical synthetic data and long-form reasoning data for Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO), enabling advanced dialogue and deep reasoning capabilities. Additionally, we introduce Test-Time Training (TTT) in the medical domain for the first time, facilitating domain adaptation and ensuring reliable, accurate reasoning. Experimental results demonstrate that FineMedLM-o1 achieves a 23% average performance improvement over prior models on key medical benchmarks. Furthermore, the introduction of TTT provides an additional 14% performance boost, highlighting its effectiveness in enhancing medical reasoning capabilities. To support this process, we also propose a novel method for synthesizing medical dialogue. Compared to other open-source datasets, our dataset stands out as superior in both quality and complexity. The project and data will be released on GitHub.