Can Large Language Models Predict the Outcome of Judicial Decisions?
作者: Mohamed Bayan Kmainasi, Ali Ezzat Shahroor, Amani Al-Ghraibah
分类: cs.CL, cs.AI
发布日期: 2025-01-15 (更新: 2025-02-28)
💡 一句话要点
提出阿拉伯语法律判决预测数据集,并验证LLaMA-3在法律领域的有效性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 法律判决预测 大型语言模型 阿拉伯语NLP 低资源语言 微调 LoRA 数据集构建
📋 核心要点
- 现有方法在阿拉伯语等低资源语言的法律判决预测(LJP)领域应用不足,缺乏高质量的阿拉伯语LJP数据集。
- 论文核心在于构建阿拉伯语LJP数据集,并探索LLaMA-3等LLM在不同配置下进行法律判决预测的性能。
- 实验结果表明,微调后的小型模型在特定任务中可与大型模型媲美,同时更节省资源,为后续研究奠定基础。
📝 摘要(中文)
大型语言模型(LLMs)在自然语言处理(NLP)的各个领域都展现出了卓越的能力。然而,它们在特定任务中的应用,例如针对阿拉伯语等低资源语言的法律判决预测(LJP),仍有待探索。本文通过开发一个阿拉伯语LJP数据集来填补这一空白,该数据集从沙特商业法院的判决中收集和预处理而来。我们对最先进的开源LLM(包括LLaMA-3.2-3B和LLaMA-3.1-8B)在零样本、单样本和使用LoRA进行微调等不同配置下进行了基准测试。此外,我们采用了一个综合评估框架,该框架集成了定量指标(如BLEU、ROUGE和BERT)和使用LLM进行的定性评估(包括连贯性、法律语言、清晰度等)。结果表明,在特定任务的上下文中,微调后的小型模型可以达到与大型模型相当的性能,同时提供显著的资源效率。此外,我们还研究了在各种指令集上微调模型的影响,为开发更以人为本和适应性强的LLM提供了有价值的见解。我们已将数据集、代码和模型公开发布,为未来阿拉伯语法律NLP的研究奠定坚实的基础。
🔬 方法详解
问题定义:论文旨在解决阿拉伯语法律判决预测(LJP)任务中缺乏高质量数据集和模型的问题。现有方法在低资源语言上的表现不佳,并且缺乏针对法律领域的专门优化。
核心思路:论文的核心思路是构建一个高质量的阿拉伯语LJP数据集,并利用该数据集对开源LLM(如LLaMA-3)进行微调,以提高其在法律领域的预测能力。通过比较不同模型大小和微调策略,寻找资源效率和性能之间的最佳平衡。
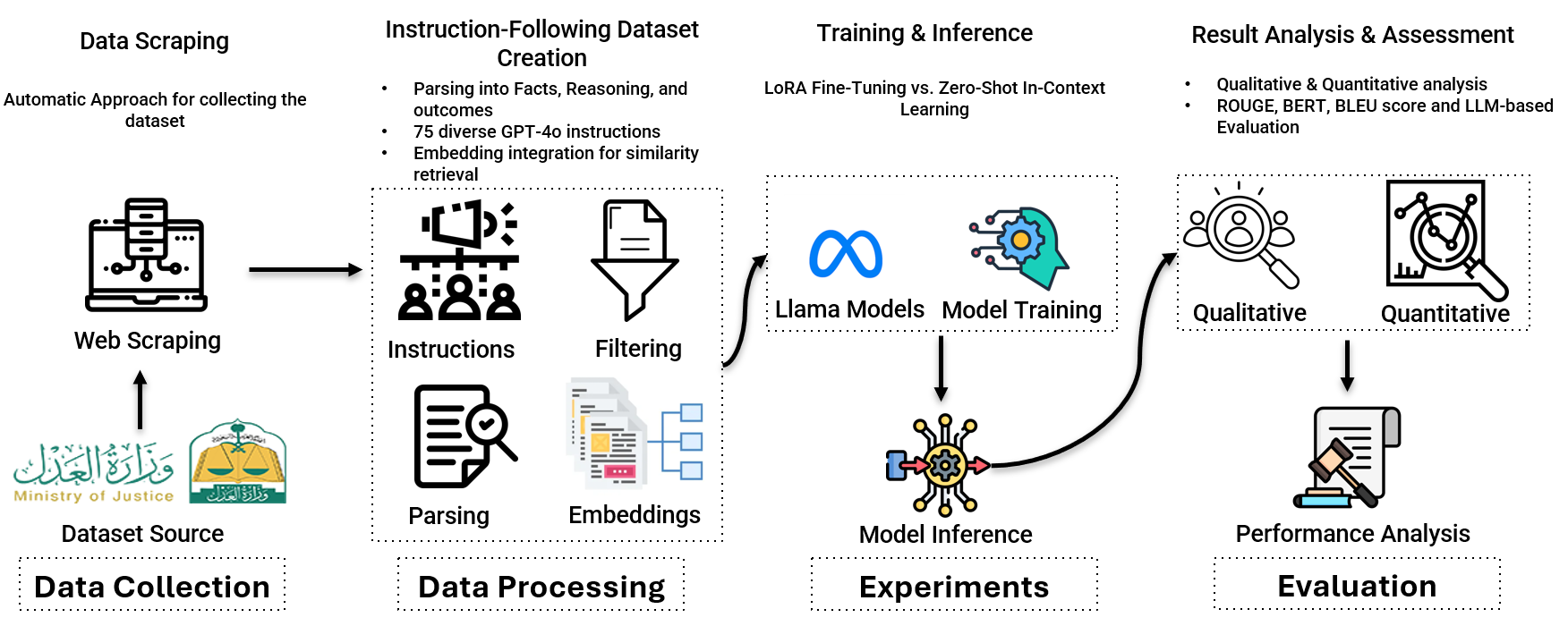
技术框架:整体框架包括数据收集与预处理、模型选择与配置、微调训练和评估四个主要阶段。首先,从沙特商业法院的判决中收集数据,并进行清洗和标注。然后,选择LLaMA-3等开源LLM,并配置不同的微调策略(如零样本、单样本、LoRA)。接着,使用构建的数据集对模型进行微调训练。最后,采用定量和定性指标对模型性能进行评估。
关键创新:论文的关键创新在于构建了一个高质量的阿拉伯语LJP数据集,并验证了微调小型LLM在特定任务中可以达到与大型模型相当的性能,同时更节省资源。此外,论文还探索了不同微调策略对模型性能的影响,为后续研究提供了指导。
关键设计:论文采用了LoRA(Low-Rank Adaptation)进行参数高效的微调,减少了计算资源的需求。评估指标包括BLEU、ROUGE和BERT等定量指标,以及连贯性、法律语言和清晰度等定性指标。具体参数设置和损失函数等细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

📊 实验亮点
实验结果表明,经过微调的小型模型(如LLaMA-3.2-3B)在阿拉伯语LJP任务中可以达到与大型模型(如LLaMA-3.1-8B)相当的性能。这表明在特定领域,小型模型通过微调可以有效利用领域知识,实现资源效率和性能的平衡。具体的性能提升幅度未在摘要中明确给出,属于未知信息。
🎯 应用场景
该研究成果可应用于智能法律咨询、法律文书自动生成、辅助法官判案等领域。通过提高LLM在法律领域的理解和推理能力,可以提升法律服务的效率和质量,并促进法律知识的普及。未来,该研究可扩展到其他低资源语言的法律领域,具有广阔的应用前景。
📄 摘要(原文)
Large Language Models (LLMs) have shown exceptional capabilities in Natural Language Processing (NLP) across diverse domains. However, their application in specialized tasks such as Legal Judgment Prediction (LJP) for low-resource languages like Arabic remains underexplored. In this work, we address this gap by developing an Arabic LJP dataset, collected and preprocessed from Saudi commercial court judgments. We benchmark state-of-the-art open-source LLMs, including LLaMA-3.2-3B and LLaMA-3.1-8B, under varying configurations such as zero-shot, one-shot, and fine-tuning using LoRA. Additionally, we employed a comprehensive evaluation framework that integrates both quantitative metrics (such as BLEU, ROUGE, and BERT) and qualitative assessments (including Coherence, Legal Language, Clarity, etc.) using an LLM. Our results demonstrate that fine-tuned smaller models achieve comparable performance to larger models in task-specific contexts while offering significant resource efficiency. Furthermore, we investigate the impact of fine-tuning the model on a diverse set of instructions, offering valuable insights into the development of a more human-centric and adaptable LLM. We have made the dataset, code, and models publicly available to provide a solid foundation for future research in Arabic legal NLP.