Multilingual LLMs Struggle to Link Orthography and Semantics in Bilingual Word Processing
作者: Eshaan Tanwar, Gayatri Oke, Tanmoy Chakraborty
分类: cs.CL
发布日期: 2025-01-15
备注: Code available at: https://github.com/EshaanT/Bilingual_processing_LLMs
💡 一句话要点
多语言LLM在双语词汇处理中难以关联正字法与语义
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言LLM 双语词汇处理 跨语言同形异义词 语义理解 正字法 词义消歧 机器翻译
📋 核心要点
- 现有LLM在处理双语词汇时,尤其是在跨语言同形异义词的消歧方面存在不足,未能有效整合正字法和语义信息。
- 该论文通过评估LLM在不同双语场景下的词义辨析能力,揭示了模型对正字法相似性的过度依赖。
- 实验结果表明,LLM在跨语言同形异义词处理上表现不佳,且孤立词汇消歧能力与语义理解能力不相关。
📝 摘要(中文)
双语词汇处理受到两种语言语音、正字法和语义特征在整合心理词典中复杂相互作用的影响。在人类中,这体现在同源词(在正字法形式和意义上相似的词,例如英语和德语中的“blind”,都表示“失明”)的处理容易程度,与跨语言同形异义词(共享正字法形式但意义不同,例如英语中的“gift”表示“礼物”,而德语中表示“毒药”)带来的挑战相比。我们研究了多语言大型语言模型(LLM)如何处理这种现象,重点关注英语-西班牙语、英语-法语和英语-德语的同源词、非同源词和跨语言同形异义词。具体来说,我们评估了它们在孤立或在句子上下文中呈现这些词类型时,消歧义和进行语义判断的能力。我们的研究结果表明,虽然某些LLM在识别孤立的同源词和非同源词方面表现出强大的性能,但它们在消除跨语言同形异义词的歧义方面表现出显著的困难,通常低于随机基线。这表明LLM在解释跨语言同形异义词时,倾向于严重依赖正字法相似性,而不是语义理解。此外,我们发现LLM在检索词义方面存在困难,孤立消歧任务中的表现与语义理解无关。最后,我们研究了LLM如何在不一致的句子中处理跨语言同形异义词。我们发现模型在理解英语和非英语同形异义词时选择不同的策略,突出了在处理跨语言歧义方面缺乏统一的方法。
🔬 方法详解
问题定义:论文旨在研究多语言LLM在双语词汇处理中,特别是处理同源词、非同源词和跨语言同形异义词时的表现。现有LLM在处理跨语言同形异义词时,常常无法正确区分其在不同语言中的含义,暴露出模型在语义理解上的不足,以及对正字法相似性的过度依赖。
核心思路:论文的核心思路是通过设计一系列任务,评估LLM在不同双语场景下(英语-西班牙语、英语-法语、英语-德语)处理上述三种词汇的能力。通过分析模型在孤立词汇和句子上下文中的表现,揭示模型在正字法和语义信息整合方面的缺陷。
技术框架:论文采用实验评估的方法,没有提出新的模型架构。主要流程包括:1) 选择合适的双语词汇(同源词、非同源词、跨语言同形异义词);2) 设计孤立词汇消歧和句子上下文消歧两种任务;3) 使用多个多语言LLM进行实验;4) 分析实验结果,评估模型在不同任务上的表现,并分析其错误模式。
关键创新:论文的创新点在于,它首次系统性地评估了多语言LLM在双语词汇处理中的能力,特别是针对跨语言同形异义词的消歧。通过实验揭示了LLM在语义理解方面的不足,以及对正字法相似性的过度依赖,为后续研究提供了重要的参考。
关键设计:论文的关键设计在于任务的设计,包括孤立词汇消歧和句子上下文消歧。孤立词汇消歧任务旨在评估模型在没有上下文信息的情况下,能否正确识别词汇的含义。句子上下文消歧任务旨在评估模型在句子上下文中,能否根据上下文信息正确理解词汇的含义。此外,论文还分析了模型在处理不一致句子时的策略,进一步揭示了模型在跨语言歧义处理方面的不足。
🖼️ 关键图片

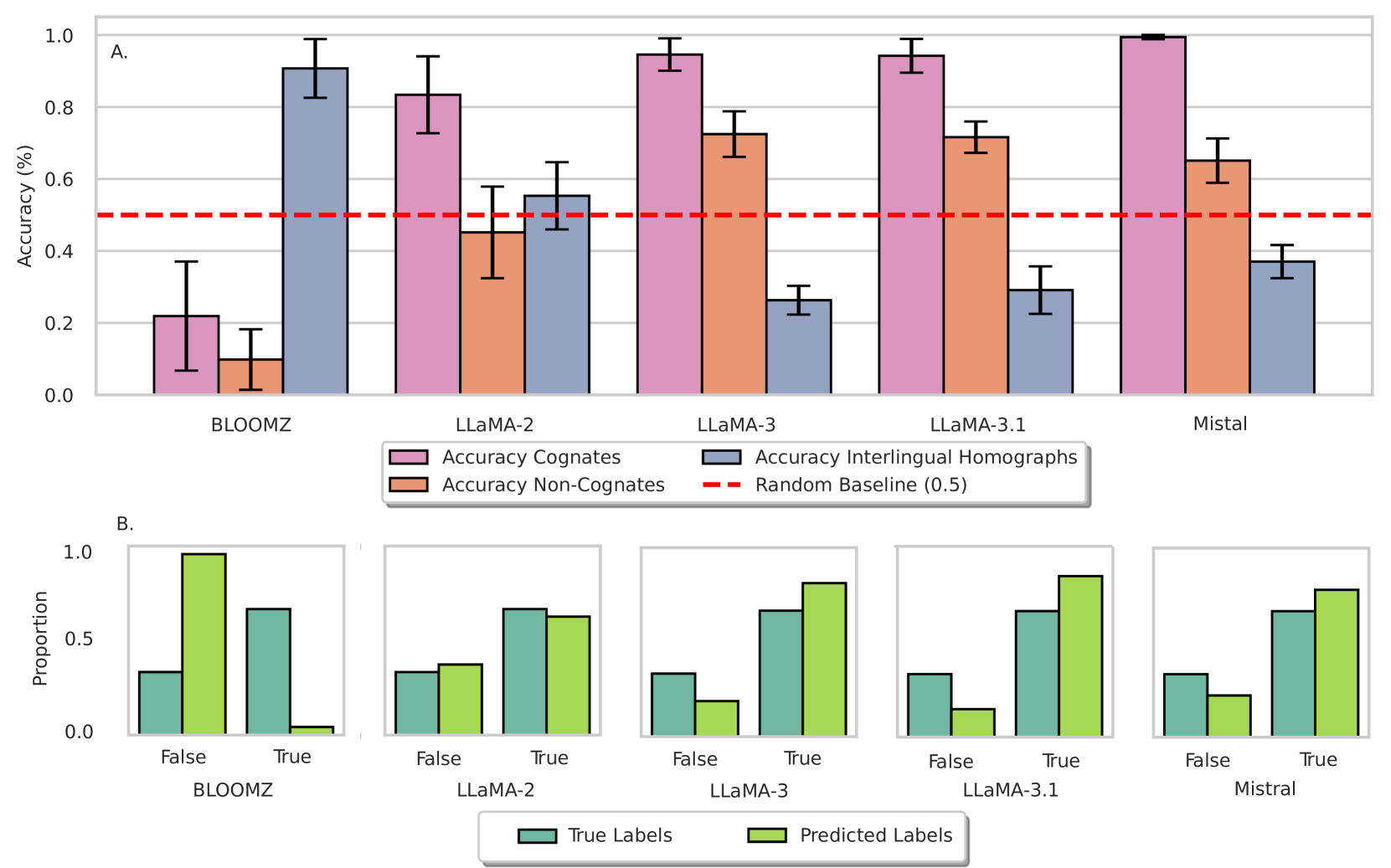
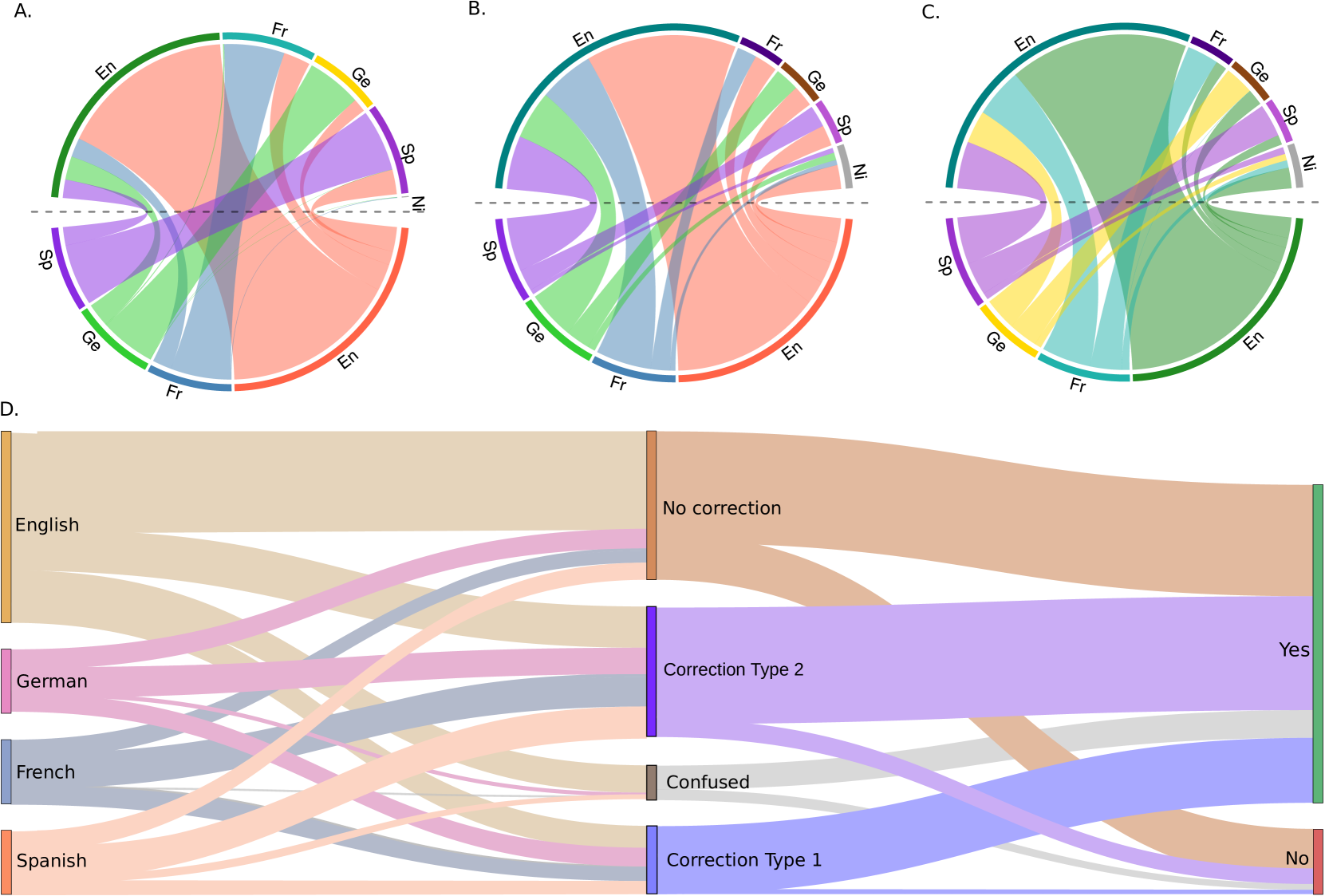
📊 实验亮点
实验结果表明,LLM在识别孤立的同源词和非同源词方面表现良好,但在消除跨语言同形异义词的歧义方面表现显著低于随机基线。这表明LLM在处理跨语言同形异义词时,过度依赖正字法相似性,而忽略了语义信息。此外,孤立消歧任务中的表现与语义理解无关,进一步证实了模型在语义理解方面的不足。
🎯 应用场景
该研究成果可应用于改进多语言机器翻译系统,提高其在处理歧义词汇时的准确性。此外,该研究对于开发更智能的多语言对话系统,以及提升LLM在跨语言理解方面的能力具有重要意义。未来的研究可以探索如何通过引入更强的语义约束,来提高LLM在双语词汇处理中的表现。
📄 摘要(原文)
Bilingual lexical processing is shaped by the complex interplay of phonological, orthographic, and semantic features of two languages within an integrated mental lexicon. In humans, this is evident in the ease with which cognate words - words similar in both orthographic form and meaning (e.g., blind, meaning "sightless" in both English and German) - are processed, compared to the challenges posed by interlingual homographs, which share orthographic form but differ in meaning (e.g., gift, meaning "present" in English but "poison" in German). We investigate how multilingual Large Language Models (LLMs) handle such phenomena, focusing on English-Spanish, English-French, and English-German cognates, non-cognate, and interlingual homographs. Specifically, we evaluate their ability to disambiguate meanings and make semantic judgments, both when these word types are presented in isolation or within sentence contexts. Our findings reveal that while certain LLMs demonstrate strong performance in recognizing cognates and non-cognates in isolation, they exhibit significant difficulty in disambiguating interlingual homographs, often performing below random baselines. This suggests LLMs tend to rely heavily on orthographic similarities rather than semantic understanding when interpreting interlingual homographs. Further, we find LLMs exhibit difficulty in retrieving word meanings, with performance in isolative disambiguation tasks having no correlation with semantic understanding. Finally, we study how the LLM processes interlingual homographs in incongruent sentences. We find models to opt for different strategies in understanding English and non-English homographs, highlighting a lack of a unified approach to handling cross-lingual ambiguities.