Decompose-ToM: Enhancing Theory of Mind Reasoning in Large Language Models through Simulation and Task Decomposition
作者: Sneheel Sarangi, Maha Elgarf, Hanan Salam
分类: cs.CL, cs.AI
发布日期: 2025-01-15
备注: Accepted to COLING 2025
💡 一句话要点
Decompose-ToM:通过模拟和任务分解增强大语言模型中的心智理论推理
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 心智理论 大型语言模型 任务分解 模拟推理 人机交互
📋 核心要点
- 现有大语言模型在复杂的心智理论任务中表现不佳,尤其是在需要结构化推理的场景下。
- 论文提出Decompose-ToM算法,通过模拟用户视角和分解任务来提升模型的心智理论推理能力。
- 实验表明,Decompose-ToM在多种模型上均取得了显著改进,且无需额外的模型训练和大量提示调整。
📝 摘要(中文)
心智理论(ToM)是理解和反思他人心理状态的能力。尽管这种能力对人际互动至关重要,但对大型语言模型(LLM)的测试表明,它们仅具备初步的理解。尽管最强大的闭源LLM在某些ToM任务上已接近人类水平,但在涉及更结构化推理的复杂变体任务上,它们的表现仍然很差。在这项工作中,我们利用认知心理学中的“假装游戏”或“模拟理论”的概念,提出了“Decompose-ToM”:一种基于LLM的推理算法,可提高模型在复杂ToM任务上的性能。我们递归地模拟用户视角,并将ToM任务分解为一组更简单的函数:主体识别、问题重构、世界模型更新和知识可用性。我们在高阶ToM任务和测试对话环境中ToM能力的任务上测试了该算法,结果表明,与基线方法相比,我们的方法在各种模型中均显示出显着改进,同时只需要最少的跨任务提示调整,而无需额外的模型训练。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在复杂心智理论(ToM)任务中表现不佳的问题。现有方法,即使是最先进的闭源LLM,在涉及高阶推理和对话场景的ToM任务中仍然面临挑战,无法准确理解和预测他人的心理状态。
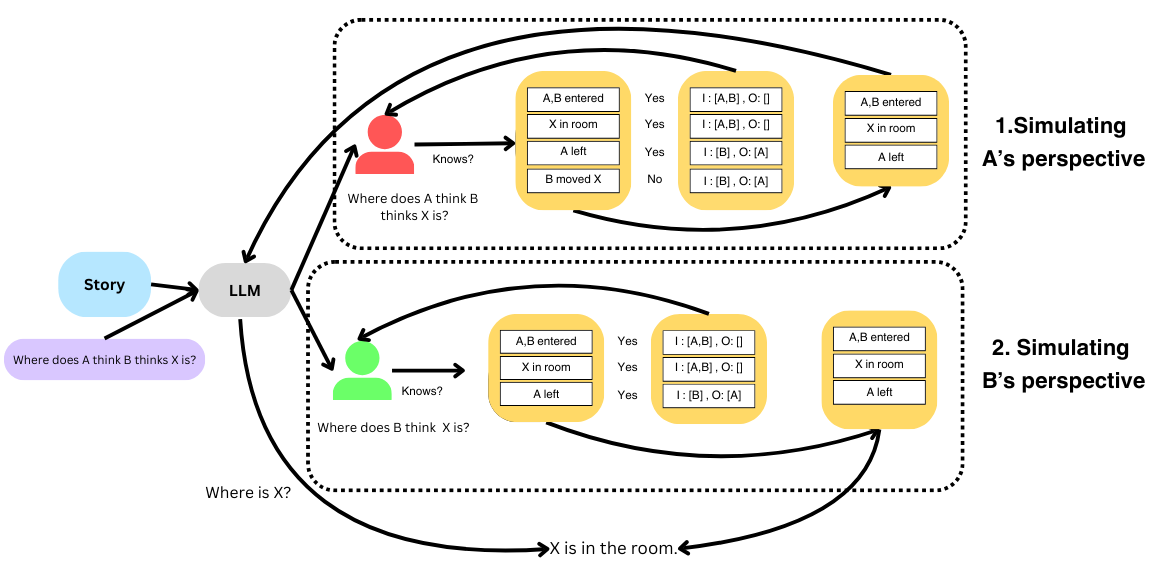
核心思路:论文的核心思路是借鉴认知心理学中的“模拟理论”,通过让LLM模拟不同角色的视角来理解ToM任务。具体而言,Decompose-ToM将复杂的ToM任务分解为一系列更简单的子任务,从而降低了推理难度,提高了模型的准确性。
技术框架:Decompose-ToM算法包含以下主要模块:1) 主体识别:识别ToM任务中的相关主体及其角色。2) 问题重构:根据不同主体的视角重新构建问题。3) 世界模型更新:根据主体的信息和行动更新世界模型。4) 知识可用性:确定主体可用的知识。算法递归地模拟用户视角,并利用这些子任务的输出来进行最终的ToM推理。
关键创新:Decompose-ToM的关键创新在于其任务分解和模拟用户视角的结合。与传统的直接推理方法相比,Decompose-ToM通过将复杂任务分解为更易于处理的子任务,并模拟不同角色的视角,显著提高了模型在复杂ToM任务中的性能。这种方法更接近人类的推理方式,也更易于理解和解释。
关键设计:Decompose-ToM算法的关键设计在于其递归模拟过程和子任务的定义。递归模拟允许模型从不同角色的视角审视问题,而精心设计的子任务则确保了模型能够有效地提取和利用相关信息。论文中没有明确提及具体的参数设置或损失函数,因为该方法主要依赖于LLM的固有能力,并通过提示工程来引导其行为。关键在于提示的设计,以确保LLM能够准确地执行每个子任务。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Decompose-ToM在各种ToM任务上均取得了显著的性能提升。在高阶ToM任务和对话ToM任务中,Decompose-ToM的表现明显优于基线方法,证明了其有效性。更重要的是,该方法只需要最少的提示调整,无需额外的模型训练,使其具有很强的通用性和易用性。具体的性能数据和提升幅度在论文中进行了详细的展示。
🎯 应用场景
Decompose-ToM具有广泛的应用前景,例如在人机交互、智能对话系统、游戏AI和社交机器人等领域。通过提高机器对人类心理状态的理解能力,可以构建更自然、更智能、更具同理心的人工智能系统。该研究还有助于我们更深入地理解人类的认知过程,并为开发更强大的通用人工智能提供新的思路。
📄 摘要(原文)
Theory of Mind (ToM) is the ability to understand and reflect on the mental states of others. Although this capability is crucial for human interaction, testing on Large Language Models (LLMs) reveals that they possess only a rudimentary understanding of it. Although the most capable closed-source LLMs have come close to human performance on some ToM tasks, they still perform poorly on complex variations of the task that involve more structured reasoning. In this work, we utilize the concept of "pretend-play", or
Simulation Theory'' from cognitive psychology to proposeDecompose-ToM'': an LLM-based inference algorithm that improves model performance on complex ToM tasks. We recursively simulate user perspectives and decompose the ToM task into a simpler set of functions: subject identification, question-reframing, world model updation, and knowledge availability. We test the algorithm on higher-order ToM tasks and a task testing for ToM capabilities in a conversational setting, demonstrating that our approach shows significant improvement across models compared to baseline methods while requiring minimal prompt tuning across tasks and no additional model training.